
In the previous blog, we discussed how to identify identity and sequence columns that are reaching their limits of inserts
Here, we are going to explore ways to identify other datatypes that are running near the limit, plus sequences
Sequences on the limit: how to identify the sequence itself, not the column
First we should create the sequence and a table:
go
create sequence new_sequence as smallint
start with 1
increment by 1;
create table sequence_demo2(
id smallint not null
constraint pk_2_sequence_demo primary key
default(next value for dbo.new_sequence),
col1 int)
---- now let's insert some
go
with
n1(c) as(select 1 union all select 1),
n2(c) as( select 1 as t1 from n1 cross join n1 as t2),
n3(c) as(select 1 as t1 from n2 cross join n2 as t2 ),
n4(c) as (select 1 from n3 as t1 cross join n3 as t2),
ids(id) as ( select ROW_NUMBER() over (order by (select null)) from n4)
insert into sequence_demo2(col1)
select id*2
from ids ;
go 10
And the script to detect that is:
go
use contosoretaildw
go
declare @id_datatype table
(
datatype_id int not null primary key,
datatype_name sysname not null,
max_entry decimal(38) not null
)
insert into @id_datatype(datatype_id,datatype_name,max_entry)
values
(48,'TINYINT',255),
(52,'SMALLINT',32767),
(56,'INT',2147483647),
(127,'BIGINT',9223372036854775807),
(108,'NUMERIC',99999999999999999999999999999999999999),
(106,'DECIMAL',99999999999999999999999999999999999999);
declare @tipping_percent int = 1 ;
with
sequence_limits
as
(
select
s.name +'.'+ sq.name as sequence_name,
case dt.datatype_id
when 48 then convert(decimal(38),convert(TINYINT,sq.current_value))
when 52 then convert(decimal(38),convert(smallint,sq.current_value))
when 56 then convert(decimal(38),convert(int,sq.current_value))
when 127 then convert(decimal(38),convert(bigint,sq.current_value))
when 108 then convert(decimal(38),sq.current_value)
when 106 then convert(decimal(38),sq.current_value)
end as current_value,
case dt.datatype_id
when 48 then convert(decimal(38),convert(TINYINT,sq.maximum_value))
when 52 then convert(decimal(38),convert(smallint,sq.maximum_value))
when 56 then convert(decimal(38),convert(int,sq.maximum_value))
when 127 then convert(decimal(38),convert(bigint,sq.maximum_value))
when 108 then convert(decimal(38),sq.maximum_value)
when 106 then convert(decimal(38),sq.maximum_value)
end as max_value
from sys.sequences sq inner join sys.schemas s on sq.schema_id = s.schema_id
inner join @id_datatype dt on dt.datatype_id = sq.system_type_id
)
select*,convert(decimal(10,3),current_value/max_value*100.) as percent_used
from sequence_limits
where convert(decimal(10,3),current_value/max_value*100.) >@tipping_percent
order by percent_used;
Let’s break it down:
- So we declared table variables that have the datatype_id, its name, and its maximum value
- Then declared the percentage that we want to monitor, Now here it is 1 for testing purposes, but we can set it to 50 while monitoring
- Then we want the sequence datatypes, and their ids that we want to compare to so we selected from sys.sequences, schemas, and the table variables we declared
- Now for each datatype, we converted the current value to its original value, then we converted it to decimal to perform explicit conversions with our eyes, not to let SQL server do it on its own
- Then we select all the columns we created, plus we asked how much is used if the filter percentage we declared is passed, which in our case is 1 percent
And this was the output:

as you can see(we ran the inserts twice) 15 percent from the sequence is used
Now unless we cycle it or alter it, or create a new one, it would raise the overflow error at some point
Now, what about other index keys that is not covered in the previous scripts, what should we do?
Index keys running on the limit: all datatypes
now first let’s create the script:
go
use contosoretaildw
go
declare @id_datatype table
(
datatype_id int not null primary key,
datatype_name sysname not null,
max_entry decimal(38) not null
)
insert into @id_datatype(datatype_id,datatype_name,max_entry)
values
(48,'TINYINT',255),
(52,'SMALLINT',32767),
(56,'INT',2147483647),
(127,'BIGINT',9223372036854775807),
(108,'NUMERIC',99999999999999999999999999999999999999),
(106,'DECIMAL',99999999999999999999999999999999999999);
declare @sql nvarchar(max),
@table_name nvarchar(512),
@column_name nvarchar(256),
@maximum_key decimal(38),
@maximum_value decimal(38),
@tipping_percent decimal(10,3) = 0.01,
@table_cursor cursor
set @table_cursor = cursor static for
select
quotename(s.name )+ '.' + QUOTENAME(t.name )as table_name,
c.name as column_name,
dt.max_entry as maximum_value
from sys.tables t inner join sys.schemas s on s.schema_id = t.schema_id
inner join sys.columns c on c.object_id = t.object_id
inner join @id_datatype dt on dt.datatype_id = c.system_type_id
where exists(
select*
from sys.indexes i inner join sys.index_columns ic on i.object_id = ic.object_id
and i.index_id = ic.index_id
and ic.key_ordinal = 1
where i.object_id = t.object_id
and ic.column_id = c.column_id
and(i.is_primary_key = 1 or i.is_unique_constraint = 1 )
and i.is_hypothetical = 0
and not exists
(
select*
from sys.index_columns ic2
where ic2.object_id = ic.object_id
and ic2.index_id = ic.index_id
and ic2.key_ordinal>1
)
)
order by 1
open @table_cursor
while 1 =1
begin
fetch @table_cursor into @table_name, @column_name, @maximum_value
if @@FETCH_STATUS <> 0
break
select @sql = 'select @maximum_value = max('+@column_name+') from ' + @table_name
print @sql
exec sp_executesql @sql , N'@maximum_value decimal OUTPUT' , @maximum_key OUTPUT
IF @maximum_key >@tipping_percent *@maximum_value
select @table_name as table_name, @column_name as column_name, @maximum_key as maximum_key
end
let’s break it down:
- so first table variables are the same, nothing to worry about
- but we added some scalar variables
- so one for the dynamic sql statement
- one for the maximum key and the maximum could be value
- one for table name
- column name
- and one for the tipping percent, now here it is 1 percent for testing purposes, otherwise we should adjust accordingly like 50 percent
- and for the cursor
- now here we declared a static one that does not get affected by the change of the data after the fetch, since we are trying to look at one snapshot
- now here it gets the table, schema, and column name from their views
- and it joins them with our declared variables so it could fetch into them
- filtering by the index catalog views where we have an index that is either a primary or unique key
- and it is the first
- and not a hypothetical one
- and filters out the second keys
- After that it starts fetching into the variables, but when?
- When the executed dynamic sql which selects the maximum of certain column that matches our filters
- and if that condition matches the tipping percent
- Then we should get them
- and see how much is used
- Then it ends
Now the output was like:
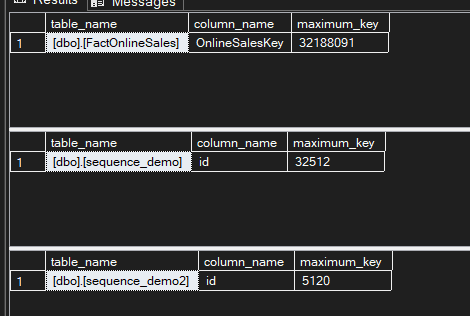
So here, as you can see, it combined most of the previous scripts, but there is one flaw
which assumes that all the decimal matches the max, the default maximum value, but we all know that it could be dynamic
But we introduced the logic to get around that in another blog, so we encourage the reader to go back there as an exercise.
And with that, we finish this blog.