
now in the previous blogs we discussed how to store the performance counters, index usage, and operational stats, today we are going to discuss how to store index physical data
as we mentioned before we are trying to explore the Indexing Method suggested by Jason Strate and Edward Pollack
Persisting sys.dm_db_index_physical_stats
now here the logic would be a little bit different
collecting fragmentation information requires actual reading of the pages of the index
now this could have 3 modes
meaning if wanted to collect it to improve performance we might degrade it
plus the difference in fragmentation over time would be irrelevant and little to non
since 30 to 35 percent fragmentation would not mean much
so there is no need for calculating deltas
we should get all the information in one table
and that would be the ‘everything’ table
now first show the table definition
which is derived from the docs
so:
use index_dmo
go
create table dbo.index_physical_stats_everything
(
id int identity(1,1),
recording_date datetime2(0),
database_id SMALLINT NOT NULL,
object_id bigint not null,
index_id bigint not null,
partition_number bigint not null,
index_type_desc nvarchar(60),
alloc_unit_type_desc nvarchar(60),
index_depth tinyint,
index_level tinyint,
avg_fragmentation_in_percent float,
fragment_count bigint,
avg_fragment_size_in_pages float,
page_count bigint,
avg_page_space_used_in_percent float,
record_count bigint,
ghost_record_count bigint,
version_ghost_record_count bigint,
min_record_size_in_bytes int,
max_record_size_in_bytes int,
avg_record_size_in_bytes float,
forwarded_record_count bigint,
compressed_page_count bigint,
hobt_id bigint null,
columnstore_delete_buffer_state tinyint null,
columnstore_delete_buffer_state_desc nvarchar(60) null,
version_record_count bigint,
inrow_version_record_count bigint,
inrow_diff_version_record_count bigint,
total_inrow_version_payload_size_in_bytes bigint,
offrow_regular_version_record_count bigint,
offrow_long_term_version_record_count bigint,
constraint pk_index_physical_stats_everyhing
primary key clustered (id),
constraint uq_index_physical_stats_everything
unique(recording_date,database_id,object_id,index_id,partition_number,alloc_unit_type_desc,index_depth,index_level)
)
;
now, we need to populate it, as we said before, it is heavier and slower than the other DMVs since it has to sample, and depending on the sampling rate it would have different results
now here it is going to get data from each database independently,
so instead of collecting the whole system’s data, we divide the effort between databases
thus reducing blocking
and this query acquires physical locks so it should be executed during noncritical business hours
and it should be done before the defragmentation efforts, since those would make the data look perfect for us
now, since this data is for defragmentation purposes like we talked about here , generally the last piece of advice is always followed
go
declare @database_id int;
declare database_s cursor FAST_FORWARD FOR
select database_id
from sys.databases
where state_desc ='online'
and database_id > 4 ;
open database_s
fetch next from database_s
into @database_id;
while @@FETCH_STATUS = 0
begin
insert into dbo.index_physical_stats_everything(
recording_date,
database_id,
object_id,
index_id,
partition_number,
index_type_desc,
alloc_unit_type_desc,
index_depth,
index_level,
avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages,
page_count,
avg_page_space_used_in_percent,
record_count,
ghost_record_count,
version_ghost_record_count,
min_record_size_in_bytes,
max_record_size_in_bytes,
avg_record_size_in_bytes,
forwarded_record_count,
compressed_page_count,
hobt_id,
columnstore_delete_buffer_state,
columnstore_delete_buffer_state_desc,
version_record_count,
inrow_version_record_count,
inrow_diff_version_record_count,
total_inrow_version_payload_size_in_bytes,
offrow_regular_version_record_count,
offrow_long_term_version_record_count
)
select GETDATE(),
database_id,
object_id,
index_id,
partition_number,
index_type_desc,
alloc_unit_type_desc,
index_depth,
index_level,
avg_fragmentation_in_percent,
fragment_count,
avg_fragment_size_in_pages,
page_count,
avg_page_space_used_in_percent,
record_count,
ghost_record_count,
version_ghost_record_count,
min_record_size_in_bytes,
max_record_size_in_bytes,
avg_record_size_in_bytes,
forwarded_record_count,
compressed_page_count,
hobt_id,
columnstore_delete_buffer_state,
columnstore_delete_buffer_state_desc,
version_record_count,
inrow_version_record_count,
inrow_diff_version_record_count,
total_inrow_version_payload_size_in_bytes,
offrow_regular_version_record_count,
offrow_long_term_version_record_count
from sys.dm_db_index_physical_stats(@database_id,null,null,null,'sampled')
fetch next from database_s
into @database_id;
end;
close database_s;
deallocate database_s;
so we declared a cursor and a variable
the variable is database_id it gets the id for us from system databases not much
the cursor fetches it from the variable
then it goes to sys.dm_dn_index_physical_stats
supplies the value as a parameter
until there are no rows
now in there, we insert the values from the DMF into our everything table
and it closes and deletes from memory the database_id
and deallocates the definition
now if we select like:
select*
from dbo.index_physical_stats_everything
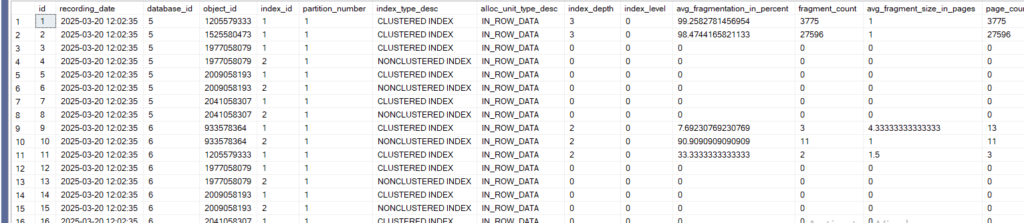
now the first database’s clustered index has almost 100 percent of fragmentation
now here we have the recording_date as a plus
plus the id as a clustered
Persisting sys.dm_os_wait_stats for indexing
now in troubleshooting locking and blocking blog we mentioned how to use the DMV
and we said it was a starting point suggested by Microsoft’s white paper in 2005
now today we are going to show how to persist information relevant to indexing on disk
using this, we can decide that the reason for the ‘system is slow’ issue is actually the indexes
so we could dig deeper through the other tools we provided to know if the performance degradation is actually caused by it, through performance counters, usage, operational, and physical stats
and maybe even run some extended events
some of the waits:
- CXPACKET, CXSYNC_PORT, CXSYNC_CONSUMER, CXCONSUMER: all of these track parallelism and whether some worker is being blocked by another process or some inner worker in the same query more information on these is in another blog
- IO_COMPLETION: means we are waiting to make a physical request, one of them could be a blocking query that is making us wait for the resource, or an index rebuild
- LCK_M_*: we talked about it in the mentioned blog at the start of this heading
- PAGEIOLATCH_*: latches are locks but in memory, and they are designed for data integrity, not ACID, when we wait on them we get this, same issues mentioned before
now we here we are going to do the same logic
first, we are going to create a table that holds the copies
and one that contains the deltas that contains everything
for the definition, we used the docs(https://learn.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/sys-dm-os-wait-stats-transact-sql?view=sql-server-ver16):
use index_dmo
go
create table dbo.index_wait_stats_copies
(
id int identity(1,1),
recording_date datetime2(0) ,
wait_type nvarchar(60) ,
waiting_tasks_count bigint ,
wait_time_ms bigint,
max_wait_time_ms bigint ,
signal_wait_time_ms bigint ,
constraint pk_index_wait_stats_copies
primary key clustered (id)
)
;
create table dbo.index_wait_stats_everything
(
id int identity(1,1),
recording_date datetime2(0) ,
wait_type nvarchar(60) ,
waiting_tasks_count bigint ,
wait_time_ms bigint ,
max_wait_time_ms bigint ,
signal_wait_time_ms bigint ,
constraint pk_index_wait_stats_everything
primary key clustered (id)
)
;
go
after creation, we insert like:
go
insert into dbo.index_wait_stats_copies
(
recording_date,
wait_type,
waiting_tasks_count,
max_wait_time_ms,
signal_wait_time_ms
)
select
GETDATE(),
wait_type,
waiting_tasks_count
wait_time_ms,
max_wait_time_ms,
signal_wait_time_ms
from sys.dm_os_wait_stats
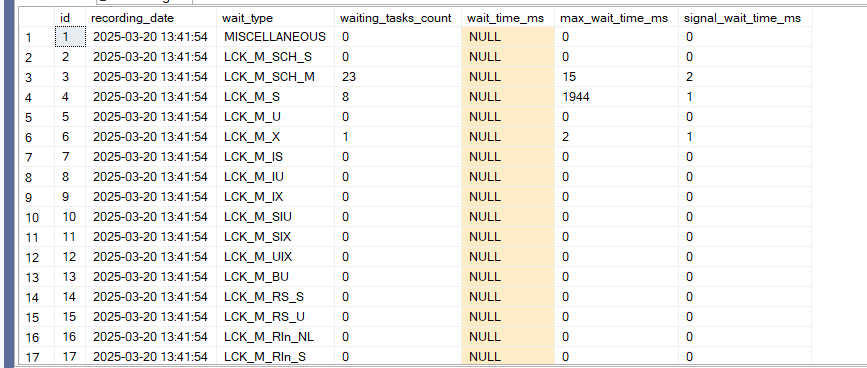
Now if we select like the following:
go
select*
from dbo.index_wait_stats_copies
We would get:
Now i am going to introduce blocking through two queries through two sessions:
---first session
use test_database
begin tran
select*
from new_id_demo with( tablockx)
/*don't commit ,
only commit after waiting for a while so we could have a differnce in this wait type
lck_m_**/
--- don't commit
commit tran
--- now in anothe session select and wait for a while:
begin tran
select*
from new_id_demo
commit tran
--- now commit the first transaction
Now after that, if we query sys.dm_os_wait_stats like:
select*
from sys.dm_os_wait_stats
where
wait_type like 'LCK_M_%'
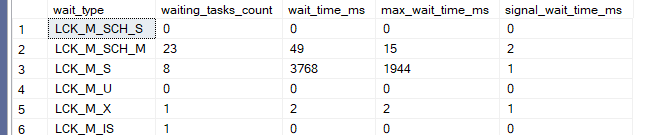
we see an increase in lck_m_s
now we can commit if we want
after that, we can insert the snapshot again like:
insert into dbo.index_wait_stats_copies
(
recording_date,
wait_type,
waiting_tasks_count,
max_wait_time_ms,
signal_wait_time_ms
)
select
GETDATE(),
wait_type,
waiting_tasks_count
wait_time_ms,
max_wait_time_ms,
signal_wait_time_ms
from sys.dm_os_wait_stats
now if we select we can see the two dates
now we should calculate the deltas to insert them into the everything table
we use coalesce to exclude nulls
and not logic with < 0 to exclude ‘-’ values
and >0 to exclude 0
so we would get the value that is positive
we use common table expressions to compare the snapshots in the table
and we use dense_rank to add an id to each different date
so:
go
with wait_stats_deltas
as
(
select
DENSE_RANK() over(order by recording_date desc) as id,
recording_date,
wait_type,
waiting_tasks_count,
wait_time_ms,
max_wait_time_ms,
signal_wait_time_ms
from dbo.index_wait_stats_copies
)
insert into dbo.index_wait_stats_everything
select
d1.recording_date,
d1.wait_type,
d1.waiting_tasks_count - coalesce(d2.waiting_tasks_count,0),
d1.wait_time_ms - coalesce(d2.wait_time_ms,0),
d1.max_wait_time_ms- coalesce(d2.max_wait_time_ms,0),
d1.signal_wait_time_ms -coalesce(d2.signal_wait_time_ms,0)
from wait_stats_deltas d1 left outer join wait_stats_deltas d2 on
d1.wait_type = d2.wait_type
and d1.waiting_tasks_count >= coalesce(d2.waiting_tasks_count,0)
and d2.id = 2
where d1.id = 1
and d1.waiting_tasks_count - coalesce(d2.waiting_tasks_count,0)>0;
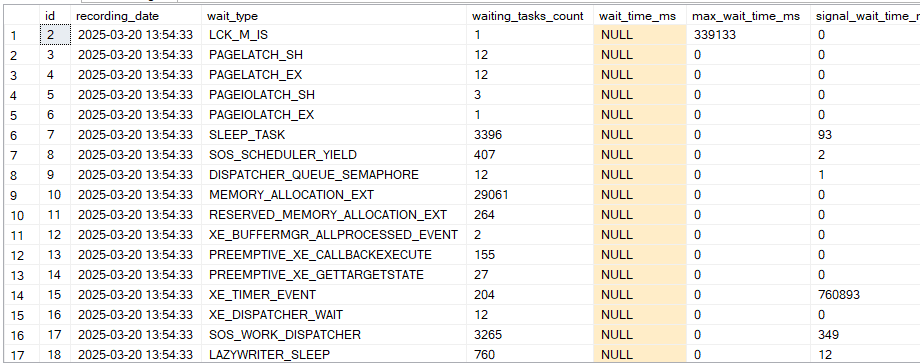
Now if we select*:
select*
from dbo.indx_wait_stats_everything
And with that, we finish our blog