
Hi everyone, in the last blog, we explored the indexing method for Jason Strate and Edward Pollack
there we explored how to capture PerfMon counters using T-SQL, specifically sys.dm_os_performance_counters
we stored the data in a table
we stored baseline or normal_hours information
we recorded the data over time
we looked at it when we wanted to review the overall state of the instance
and we tried to pinpoint the date that the index performance degraded
and to prove our theory we needed a general metric for the entire SQL server instance
this was PerfMon
now we picked the date we suspected
and then compared it to the baseline
now if we feel that the problem here could be because of indexes
we should investigate more, we can use some DMOs related to indexing
now as you all know, all the indexing DMV resets at server restart
but sometimes we need to persist this information to compare trends
today we are going to discuss how to store DMVs like we stored PerfMon counters to monitor indexes with more granularity
Persisting sys.dm_db_index_usage_stats
now we introduced it before here
we said it shows a general overview of the server’s index state
and it is a good starting point while tuning indexes
so let’s store it
first, we create a table that holds the information
insert what we want on a regular basis
compare the dates we want to compare using the inserted data
each snapshot inserted would present a different set
we should record a baseline, normal_hours table
and compare it to whatever we want
to create the table that holds all the DMO data:
go
create database index_dmo
go
use index_dmo
go
so this is the name of the database we want to persist the data in:
create table dbo.index_usage_stats_everything
(
id int identity(1,1),
recording_date datetime2(0),
database_id smallint not null,
object_id int not null,
index_id int not null,
user_seeks bigint not null,
user_scans bigint not null,
user_lookups bigint not null,
user_updates bigint not null,
last_user_seek datetime,
last_user_scan datetime,
last_user_lookup datetime,
last_user_update datetime,
system_seeks bigint not null,
system_scans bigint not null,
system_lookups bigint not null,
system_updates bigint not null,
last_system_seek datetime,
last_system_scan datetime,
last_system_lookup datetime,
last_system_update datetime,
constraint pk_index_usage_stats_everything
primary key clustered (id),
constraint uq_index_usage_stats_everything
unique(recording_date,database_id,object_id,index_id)
)
;
create table dbo.index_usage_stats_copies
(
id int identity(1,1),
recording_date datetime2(0),
database_id smallint not null,
object_id int not null,
index_id int not null,
user_seeks bigint not null,
user_scans bigint not null,
user_lookups bigint not null,
user_updates bigint not null,
last_user_seek datetime,
last_user_scan datetime,
last_user_lookup datetime,
last_user_update datetime,
system_seeks bigint not null,
system_scans bigint not null,
system_lookups bigint not null,
system_updates bigint not null,
last_system_seek datetime,
last_system_scan datetime,
last_system_lookup datetime,
last_system_update datetime,
constraint pk_index_usage_stats_copies
primary key clustered (id),
constraint uq_index_usage_stats_copies
unique(recording_date,database_id,object_id,index_id)
)
nothing much here, we created two tables that had the columns the DMV had
plus added a clustered index on id and a unique nonclustered on the other unique combination
the other stuff are the same DMV columns and their structure you can find it in the docs here
now let’s insert some data:
INSERT INTO dbo.index_usage_stats_copies
SELECT
GETDATE(),
database_id,
object_id,
index_id,
user_seeks,
user_scans,
user_lookups,
user_updates,
last_user_seek,
last_user_scan,
last_user_lookup,
last_user_update,
system_seeks,
system_scans,
system_lookups,
system_updates,
last_system_seek,
last_system_scan,
last_system_lookup,
last_system_update
FROM sys.dm_db_index_usage_stats;
now if we query copies:
select*
from dbo.index_usage_stats_copies
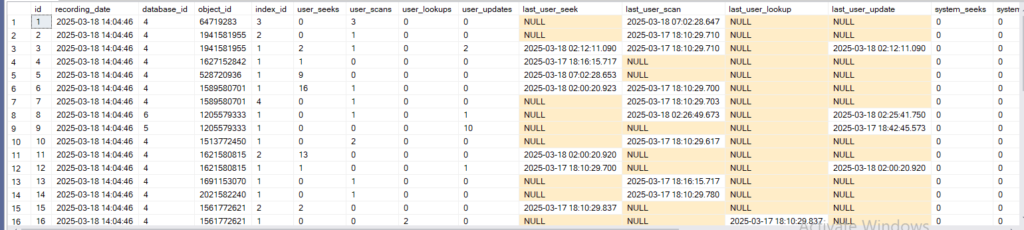
now as you can see here it has all the information that we would have from the DMV plus datetime
plus the id
now if we do some tests like:
use test_database
go
select*
from dbo.new_id_demo
go 10
select*
from dbo.new_id_demo
where UserID = 'B630F50E-9AFC-4652-92CE-000019765E4E'
go 200
--- now we did mention the setup in previous blogs but for completion sake
--- both the creation and the selects might take sometime
--- now this is the setup
--- before the setup to get the same results you should have created this before this operation
=--- the results does not matter much but
go
use test_database
create table new_id_demo(
UserID uniqueidentifier not null default newid(),
purchase_amount int);
go
create clustered index ix_userid on new_id_demo(userid)
with( fillfactor = 100, pad_index =on);
go
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into new_id_demo(purchase_amount)
select id*20
from ids;
create clustered index ix_userid on new_id_demo(userid)
with( fillfactor = 100, pad_index =on);
go 10
--- like we said this is only necessary if you did not follow us in the previous blog
and insert into copies again:
INSERT INTO dbo.index_usage_stats_copies
SELECT
GETDATE(),
database_id,
object_id,
index_id,
user_seeks,
user_scans,
user_lookups,
user_updates,
last_user_seek,
last_user_scan,
last_user_lookup,
last_user_update,
system_seeks,
system_scans,
system_lookups,
system_updates,
last_system_seek,
last_system_scan,
last_system_lookup,
last_system_update
FROM sys.dm_db_index_usage_stats;
and select* again:
select*
from dbo.index_usage_stats_copies
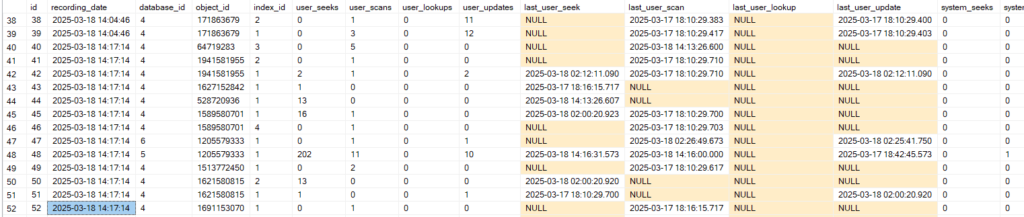
now as you can see, it has the new snapshot copy information
but here it collected both values
so what we are looking at here is both combined,
now obviously if we wanted to analyze this we should not use the combined
getting the difference would be a better way to do this
plus here we have to look manually for each datetime
what if it is collected snapshots each day for a year
or more every hour or 10 seconds
how could we go manually through all that!!
the solution is to subtract the values from each other
but where?
in the history or everything table
now there we are going to include the differences, the deltas between each
and with that we can monitor the difference between intervals as much as we want
without getting overwhelmed
to do that:
with index_usage_deltas
as(
select
dense_rank() over (order by recording_date desc) as id,
recording_date,
database_id,
object_id,
index_id,
user_seeks,
user_scans,
user_lookups,
user_updates,
last_user_seek,
last_user_scan,
last_user_lookup,
last_user_update,
system_seeks,
system_scans,
system_lookups,
system_updates,
last_system_seek,
last_system_scan,
last_system_lookup,
last_system_update
from
dbo.index_usage_stats_copies)
insert into dbo.index_usage_stats_everything
select
d1.recording_date,
d1.database_id,
d1.object_id,
d1.index_id,
d1.user_seeks - coalesce(d2.user_seeks,0),
d1.user_scans - coalesce(d2.user_scans,0),
d1.user_lookups-coalesce(d2.user_lookups,0),
d1.user_updates - coalesce(d2.user_updates,0),
d1.last_user_seek,
d1.last_user_scan,
d1.last_user_lookup,
d1.last_user_update,
d1.system_seeks- coalesce(d2.system_seeks,0),
d1.system_scans - coalesce(d2.system_scans,0),
d1.system_lookups - coalesce(d2.system_lookups,0),
d1.system_updates - coalesce(d2.system_updates,0),
d1.last_system_seek,
d1.last_system_scan,
d1.last_user_lookup,
d1.last_user_update
from index_usage_deltas d1
left outer join index_usage_deltas d2 on d1.database_id = d2.database_id
and d1.object_id = d2.object_id
and d1.index_id = d2.index_id
after that we select like:
select*
from dbo.index_usage_stats_everything
we get:
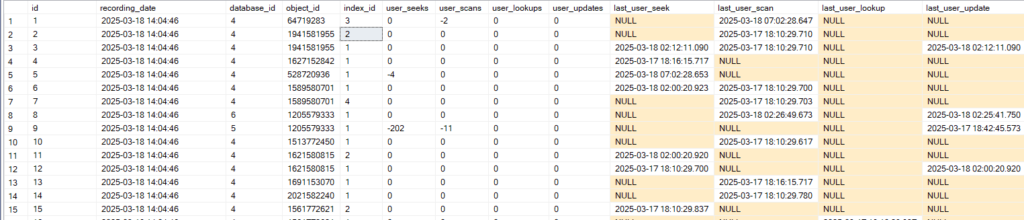
use see the minus out there
now we don’t want that
so if you drop the table everything and then recreate like this:
with index_usage_deltas
as(
select
dense_rank() over (order by recording_date desc) as id,
recording_date,
database_id,
object_id,
index_id,
user_seeks,
user_scans,
user_lookups,
user_updates,
last_user_seek,
last_user_scan,
last_user_lookup,
last_user_update,
system_seeks,
system_scans,
system_lookups,
system_updates,
last_system_seek,
last_system_scan,
last_system_lookup,
last_system_update
from
dbo.index_usage_stats_copies)
insert into dbo.index_usage_stats_everything
select
d1.recording_date,
d1.database_id,
d1.object_id,
d1.index_id,
d1.user_seeks - coalesce(d2.user_seeks,0),
d1.user_scans - coalesce(d2.user_scans,0),
d1.user_lookups-coalesce(d2.user_lookups,0),
d1.user_updates - coalesce(d2.user_updates,0),
d1.last_user_seek,
d1.last_user_scan,
d1.last_user_lookup,
d1.last_user_update,
d1.system_seeks- coalesce(d2.system_seeks,0),
d1.system_scans - coalesce(d2.system_scans,0),
d1.system_lookups - coalesce(d2.system_lookups,0),
d1.system_updates - coalesce(d2.system_updates,0),
d1.last_system_seek,
d1.last_system_scan,
d1.last_system_lookup,
d1.last_system_update
from index_usage_deltas d1
left outer join index_usage_deltas d2 on d1.database_id = d2.database_id
and d1.object_id = d2.object_id
and d1.index_id = d2.index_id
and d2.id = 2
---- exclude the '-' as the opposite of '+' like +1 and -1 values that are less than 0
and not
(
d1.system_seeks - coalesce(d2.system_seeks,0)<0
and d1.system_scans - coalesce(d2.system_scans,0)<0
and d1.system_lookups - coalesce(d2.system_lookups,0)<0
and d1.system_updates- coalesce(d2.system_updates,0)<0
and d1.user_seeks - coalesce(d2.user_seeks,0)<0
and d1.user_scans - coalesce(d2.user_scans,0)<0
and d1.user_lookups - coalesce(d2.user_lookups,0)<0
and d1.user_updates - coalesce(d2.user_updates,0)<0
)
where d1.id = 1
--- now we get what we want
and
(
d1.system_seeks - coalesce(d2.system_seeks,0)>0
or d1.system_scans - coalesce(d2.system_scans,0)>0
or d1.system_updates- coalesce(d2.system_updates,0)>0
or d1.user_seeks - coalesce(d2.user_seeks,0)>0
or d1.user_scans - coalesce(d2.user_scans,0)>0
or d1.user_lookups - coalesce(d2.user_lookups,0)>0
or d1.user_updates - coalesce(d2.user_updates,0)>0
)
;
and then select from everything:
select *
from dbo.index_usage_stats_everything
we would get:

so as you can see here it shows the id based on the date, and it only shows the difference
so here it increased by these values
how did we get that?
in coalesce we get rid of the null by putting 0 instead
and in the ‘and not’ subquery we get rid of the values that are -
and with ‘and’ after the ‘where’ clause
and the snapshots inserted here present the last two dates represented by the id based on date by the dense_rank window function that does not skip anything
and we filter by the ids
so we get the value of the last date represented by the last date as 1 and the one before that as 2 and then subtract id(1)-id(2)
and we get our values up here
and with that, we end this blog, see you in the next one