
now here we are going to start introducing the basics of the iterative process of index tuning
at the start of development, the application code is being modified too frequently, and the queries needed the most are always changing
so we introduce the basics of indexing at this stage
primary keys,
constraints like uniqueness
referential integrity etc.
then at later stages when we know the workload, we can estimate the most requested queries and tune accordingly
when we try to simulate data in development we must meet these two conditions:
- enough representative data
- simulating workload
now in an existing system(beside emergencies):
- index analysis
- remove redundant and inefficient
- add new if necessary
analysis of current indexes: detecting the unused
now we have reads and writes
every select just reads
but insert, update, delete, merge all read a certain amount of rows, then modify
for example, delete locates the row = reads it
then it deletes it
now if we are just reading, indexes are golden
but once we modify a row, we have to modify it in every index that contains it, at least clustered, plus any nonclustered that includes it
now to track that we have two DMVs
sys.dm_db_index_operation_stats and sys.dm_db_index_usage_stats
now let’s try both:
create table dbo.index_usage_demo(
id int not null,
col1 int,
col2 int,
col_str char(2000)
);
create unique clustered index ix_index_usage_demo_id_CI on dbo.index_usage_demo(id);
create unique nonclustered index ix_index_usage_demo_col1_nci on dbo.index_usage_demo(col1);
create unique nonclustered index ix_index_usage_demo_col2_nci on dbo.index_usage_demo(col2);
with
n1(c) as (select 0 union all select 0),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
ids(id) as (select row_number() over (order by (select null)) from n3)
insert into dbo.index_usage_demo(id,col1,col2)
select id,id*2,id*20
from ids;
now here we created a table with 1 id, 2 col1 and col2, and one empty string
then we created indexes on the id
and 2 on the integers
then we inserted 16 values each
now let’s see sys.dm_db_index_usage_stats:
sys.dm_db_index_usage_stats:
select*
from sys.dm_db_index_usage_stats
where database_id = db_id()
And we would get the following:

Now here we see:
- database_id
- object_id
- index_id: only unique table-wise
- user_seek:s how many seek operators happened in each execution plan
- user_scans: how many scan operators happened per execution plan
- user_lookup: the same here
- user_updates: same here
- last_….: it shows timestamps for the last of each
- system…: for internal queries
- then it has the same timestamps for system
Now we can filter the output just for our table like:
use testdatabase
select
s.name +'.'+t.name as [schema.table],
i.name as index_name,
iu.user_seeks,
iu.user_scans,
iu.user_lookups,
iu.user_seeks + iu.user_scans+iu.user_lookups as total_user_reads,
iu.user_updates,
iu.last_user_seek,
iu.last_system_scan,
iu.last_user_lookup,
iu.last_user_update
from sys.tables t inner join sys.indexes i on
t.object_id = i.object_id
inner join sys.schemas s on
t.schema_id = s.schema_id
left outer join sys.dm_db_index_usage_stats iu on
iu.database_id = db_id()
and
iu.object_id = i.object_id
and
iu.index_id = i.index_id
where s.name = N'dbo' and t.name =N'index_usage_demo'
order by s.name,t.name,i.name;
now here we just added the schema, table, and index name so we could analyze in a more meaningful way, we excluded the system counters
now here we can evaluate the usage stats, how necessary each index is, why they were using it, is it seeks scans, whether we need a new one for key lookups, and how often they do happen

now here as you can see since we did one insert, we can see one update, and the timestamp for the last insertion
now this thing resets every time the server restarts, so we have to keep that in mind
plus, this DMV resets at every server restart
plus, since it only retains information since the last server restart, some indexes that are needed for monthly reports for example, can not be disregarded, since they are necessary but the DMV shows that they have not been used since the last month
now this index could be dropped every month for example
plus, it gets cleaned every time we detach or auto_close a database
plus, index rebuilds reset this DMV in SQL server 2012, 2014, this is a bug
plus,(paul white)it is per operator, not per operation
plus, generating an execution plan does not count
plus, even if the operator did not execute, but it was there during execution, it is counted
plus, index usage stats consider all seeks the same, which means singleton-lookup is counted the same as range-scan, even though they are totally different operations
also, range scans can scan the whole table except the first value, but that is still counted as one
now let’s give some examples:
Example 1: seeks, range-scan vs singleton-lookup
Now if we select like:
--- singleton-lookup
select col_str
from dbo.index_usage_demo
where id = 1
Now after this if we query the DMV:

Now if we do 5 singleton-lookups:
--- 5 singleton lookups counted as 1
select col_str
from dbo.index_usage_demo
where id in ( 1,2,3,4,5)
Now in the properties of the execution plan:

Then DMV:

So as you can see here it only counts one operator, now if we wanted to see how many times it got executed per row, we need to use sys.dm_db_index_operational_stats more on it later
Now if we range-scan like:
--- range-scan
select col_str
from dbo.index_usage_demo
where id >1

so it is 3 now because it was a seek, even though the range-scan scanned the whole table except one value
Example 2: index scans
now we can:
select*
from dbo.index_usage_demo with (index = 1);
DMV:

we have our scan now
now here as you can see we only used the clustered index
Let’s force the others in the previous queries:
Example 3: singleton-lookup with Key-lookup
select col_str
from dbo.index_usage_demo with(index =ix_index_usage_demo_col1_nci)
where col1 in (2,4,6,8,10)
now here we used it once, it chose to scan the clustered index first so we had to use the hint
now if we DMV:

Example 5: updates, nonclustered, counting the updates even though the transaction did not commit
--- this one did not execute
update dbo.index_usage_demo
set col2 = -20
--- now this one did
update dbo.index_usage_demo
set col2 = -20 where col2 = 20

Now as you can see it did show it twice even if we could not commit.
Now if an update statement does not execute, it would be counted as an update, and a read
this DMV shows an overview of indexes, if we want a more detailed outlook we should look at the other one:
sys.dm_db_index_operational_stats
Now first let’s select*:
select*
from sys.dm_db_index_operational_stats(db_id(),object_id(N'dbo.index_usage_demo'),NULL,NULL)
Now the last two parameters are for index_id and partition_id

so we have:
- database_id
- object_id
- index_id
- partition_number
- hobt_id
- leaf_insert_count how many inserts did happen on leaf level records row by row, unlike the other one usage stats since the last server restart
- leaf_delete_count
- leaf_update_count
- leaf_ghost_count
- nonleaf_……
- leaf_allocation_count: how many pages have been allocated to an index or a heap, if a heap, how many pages were added, if an index, how many page splits
- nonleaf…….

- now we start seeing singleton lookups,range-scans, and forwarded fetch
- lob_fetch, is how many times we retrieved
- the lob_orphan stuff is for bulk inserts

- now here we start to see the columns related to locks and latches

- now here we see compression and row-versioning columns

now as you can see, the amount of data is overwhelming
so whenever we use it, we have to tailor it to our specific needs
now here we are going to create a table to demonstrate the seek operations:
Example: singleton-lookups and range scans
create table seeks_demo(
id int not null,
col1 int,
col2 int,
col3 char(7000)
);
create unique clustered index ix_seeks_demo_id_ci on dbo.seeks_demo(id);
create nonclustered index ix_seeks_demo_col1_nci on dbo.seeks_demo(col1);
create nonclustered index ix_seeks_demo_col2_nci on dbo.seeks_demo(col2);
with
n1(c) as (select 0 union all select 0),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
ids(id) as (select row_number() over ( order by (select null)) from n3)
insert into dbo.seeks_demo(id,col1,col2)
select id, id*2,id*20
from ids
After that, we select with point-lookup and range-scan like:
--- range scan
select col1
from seeks_demo with ( index = ix_seeks_demo_col1_nci)
where col1>0
---- singleton-lookup with key-lookup
select *
from seeks_demo with(index = ix_seeks_demo_col1_nci)
where col1 = 2
Now if we index_operatinal_stats like:
select i.name as index_name,singleton_lookup_count,range_scan_count
from sys.dm_db_index_operational_stats(db_id(),object_id(N'dbo.seeks_demo'),NULL,NULL) op inner join
sys.indexes i on i.object_id = op.object_id
and i.index_id = op.index_id
We would get:
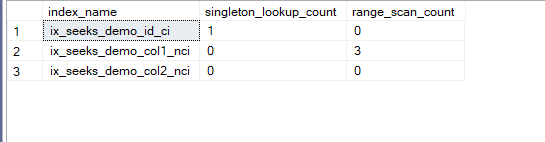
But if we point-lookup only:
select col1
from col1 with(index = ix_seeks_demo_col1_nci)
where col1 = 1
We get:
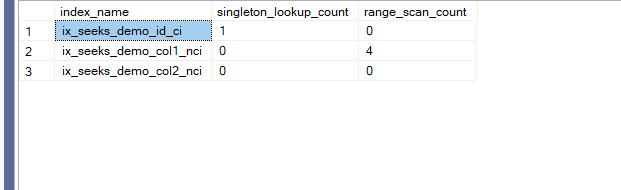
even though it was a point-lookup
why is that? because it is not unique, it can return any number of values
but the clustered index is unique
So if we select like:
select id
from seeks_demo
where id = 2
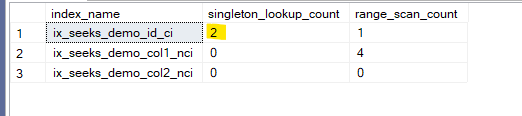
So it records it when it is unique only.
And with that, we are done with DMV for usage and operational index stats.