
Intro
now every time we update a clustered index
we are moving the key to a different page
and with that we are moving the row-id= clustered index key = physical location of the row
which causes an update in every nonclustered index out there
which costs a lot in terms of I/O
so it is better to design a static one
and if this one changes in size, it is going to cause a lot of fragmentation
which degrades performance
now every clustered key = row-id for the nonclustered
which means if we choose a wide one, we are increasing the size of every index out there
which increases i/o
plus if we are going to seek nonclustered
we are going to buffer
which means more memory consumption
so tight and static
we also know that if we did not add the unique in the creation
SQL server will add a uniquifier for each non-unique clustered index key
Uniquifier in clustered indexes
each one will be added to the leaves of the nonclustered
that would cause an increase of key size in each one
plus will decrease the amount we can store on each page
plus will increase the intermediate levels of the index
even though they are in cache
they consume memory and CPU
and are less scalable in the future, since at a certain point you have to tune your queries
so what is a uniqufier?
if we had a non-unique clustered index
and we wanted to store it
SQL server makes it unique
by adding NULL for the first occurrence
we saw that in the previous blogs
it is a uniquifier added for non-unique clustered indexes, and since most of our keys were ever-increasing we only saw nulls
now what happens if we had two duplicate keys? it increases it from there as an ever-increasing value
let’s do a demo:
create table uniquifier(
id int
col1 int)
create clustered index ix_uniquifier on uniquifier(id)
go
insert into uniquifier(id,col1)values(1,1),(1,1),(1,1),(1,1),(1,1),(1,1),(1,1),(1,1)
go 20001
Now let’s dbcc ind:
dbcc ind('testdatabase','dbo.uniquifier',1)
We get the following:


Now if we dbcc page the root page like:
dbcc traceon(3604)
dbcc page('testdatabase',1,51531,3)
We would get the following:
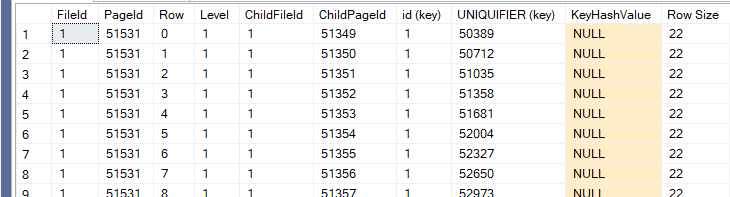
As you can see we have the uniquifier in each, since the key can not be unique SQL server added that to it
Now if we look at the output:
Slot 0 Offset 0x60 Length 22
Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 22
Memory Dump @0x0000007C83BF6060
0000000000000000: 36010000 0095c800 00010001 00000100 1600d5c4 6....È...........ÕÄ
0000000000000014: 0000 ..
you see this d5c4000 = 0000C4D5 = the first uniqufier =50389 we talked about the others in previous blogs
Testing the overhead of uniqufiers(this was inspired by Dmitri Korotkevitch)
now here we are going to create 3 tables
the first one is going to be unique
the second one will be the same, but it is not unique, at the same time no duplicates
the third one will be different, it won’t be unique, and it will have duplicates
use testdatabase
create table unique_uniqufier_CI(
id int not null,
id1 int not null,
col1 char(986) null,
col2 varchar(32) not null
constraint placeholder_default_unique
default 'SSSS'
);
create unique clustered index ix_uniqueCI
on dbo.unique_uniqufier_CI(id);
create table nonunique_uniqufier_CI(
id int not null,
id1 int not null,
col1 char(986) null,
col2 varchar(32) not null
constraint placeholder_default_non_unique
default'SSSS'
);
create /* the unique should be here*/ clustered index ix_non_uniqueCI
on dbo.nonunique_uniqufier_CI(id);
create table nonunique_uniqufier_with_duplicates_CI(
id int not null,
id1 int not null,
col1 char(986) null,
col2 varchar(32) not null
constraint placeholder_default_non_unique_with_duplicates
default 'SSSS'
);
create /* the unique should be here*/ clustered index ix_non_unique_with_duplicates_CI
on dbo.nonunique_uniqufier_with_duplicates_CI(id);
---- now we are going to insert our values
with n1(c) as (select 0 union all select 0),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select ROW_NUMBER() over (order by( select null)) from n5)
insert into dbo.unique_uniqufier_CI(id,id1)
select id,id from ids;
--- that was the first clustered
--- now the second
with n1(c) as (select 0 union all select 0),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select ROW_NUMBER() over (order by( select null)) from n5)
insert into dbo.nonunique_uniqufier_CI(id,id1)
select id,id from ids;
---- that was the second all unique, ever-increasing
---- here we are going to inlude the remainder of dividing by 10
insert into dbo.nonunique_uniqufier_with_duplicates_CI(id,id1)
select id%10 , id1 from dbo.unique_uniqufier_CI
select*
from dbo.nonunique_uniqufier_with_duplicates_CI
now that we created our tables, let’s compare their sizes
select
index_level,
page_count,
min_record_size_in_bytes,
max_record_size_in_bytes,
avg_record_size_in_bytes
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.unique_uniqufier_CI'),1,null,'Detailed')
----
select
index_level,
page_count,
min_record_size_in_bytes,
max_record_size_in_bytes,
avg_record_size_in_bytes
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.nonunique_uniqufier_CI'),1,null,'Detailed')
----
select
index_level,
page_count,
min_record_size_in_bytes,
max_record_size_in_bytes,
avg_record_size_in_bytes
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.nonunique_uniqufier_with_duplicates_CI'),1,null,'Detailed')
And this was the output:
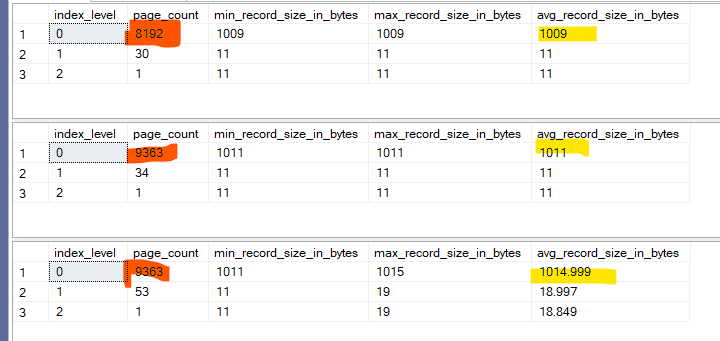
Now as you can see, in the non_unique with no duplicates we had two extra bytes for the uniquifier that says it is null
Now in the one with duplicates, we have 4 bytes just like we saw in our first example, plus the two that are supposed to be in every uniquifier
now as you can see we have so many duplicates that our intermediate level pages have extras in the duplicates since the size of each key is more by 4 bytes and the row size is already more, so we have more pages, bigger size in the clustered, etc. Now let’s see how that would affect nonclustered indexes:
now let’s see how that would affect nonclustered indexes:
The effect of non-unique clustered on nonclustered
Now let’s create the same nonclustered on each:
--- creating nonclustered on unique
create nonclustered index ix_unique_uniqufier_nci on dbo.unique_uniqufier_CI(id1);
---the non_unique no duplicates
create nonclustered index ix_nonunique_uniqufier_nci on dbo.nonunique_uniqufier_CI(id1);
--- the non_unique with duplicates
create nonclustered index ix_nonunique_uniqufier_with_duplicates_nci on dbo.nonunique_uniqufier_with_duplicates_CI(id1);
Now let’s check out index physical stats for each.
----
select
index_level,
page_count,
min_record_size_in_bytes,
max_record_size_in_bytes,
avg_record_size_in_bytes
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.unique_uniqufier_CI'),2,null,'Detailed')
----
select
index_level,
page_count,
min_record_size_in_bytes,
max_record_size_in_bytes,
avg_record_size_in_bytes
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.nonunique_uniqufier_CI'),2,null,'Detailed')
-----
select
index_level,
page_count,
min_record_size_in_bytes,
max_record_size_in_bytes,
avg_record_size_in_bytes
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.nonunique_uniqufier_with_duplicates_CI'),2,null,'Detailed')
And we would get:
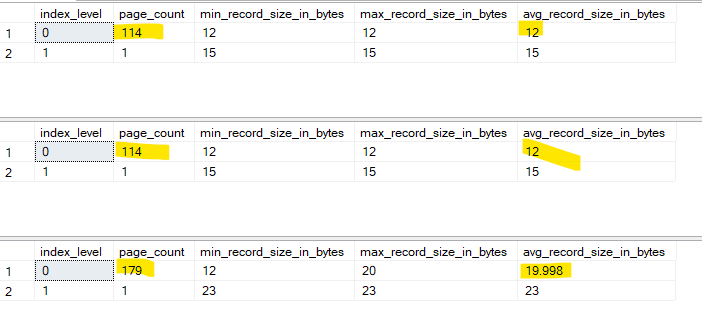
now, as we knew before, we store each clustered key as row-id in each nonclustered index
so we have to store the uniqueidentifier if it is there
now since in the non-unique non-duplicate, we don’t have any overhead, but in the case with duplicates we do
Why?
the overhead of storing 4 bytes for uniquifier
and 4 bytes for the variable columns
but how does that play out, I don’t know
and why do we have it only in the duplicate one?
SQL server just chooses not to store it if it is unique on its own and the uniqufier is unnecessary for that specific row
now the key takeaway here is don’t create clustered indexes that have duplicates, or non-unique
since SQL server has to make it unique on its own and it is going to cost the same storage or even more,
instead, we can create one surrogate key like identity(1,1) ever-increasing and unique
or make a composite one based on both, we will talk about this later in this blog
storing nonclustered with null in variable plus duplicates allows null but totally full:
create table nonunique_uniqufier_with_duplicates_CI_variable_null(
id int not null,
id1 int not null,
col1 char(986) null,
col2 varchar(32) null
constraint placeholder_default_non_unique_with_duplicates_with_null
default 'SSSS'
)
create /* the unique should be here*/ clustered index ix_non_unique_with_duplicates_CI_vn
on dbo.nonunique_uniqufier_with_duplicates_CI_variable_null(id);
---- now let's insert
insert into dbo.nonunique_uniqufier_with_duplicates_CI_variable_null(id,id1)
select id%10 , id1 from dbo.unique_uniqufier_CI
---- now let's create the nonclustered
create nonclustered index ix_nonunique_uniqufier_with_duplicates_with_variable_null_nci on dbo.nonunique_uniqufier_with_duplicates_CI_variable_null(id1);
Now if we check the physical stats of the nonclustered:
select
index_level,
page_count,
min_record_size_in_bytes,
max_record_size_in_bytes,
avg_record_size_in_bytes
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.nonunique_uniqufier_with_duplicates_CI_variable_null'),2,null,'Detailed')
we would get

so the same 8 bytes
the same but without the constraint of default, so all null variables:
---------
create table nonunique_uniqufier_with_duplicates_CI_variable_null_not_full(
id int not null,
id1 int not null,
col1 char(986) null,
col2 varchar(32) null
)
--- create the clustered
create clustered index ix_nonunique_uniqufier_with_duplicates_CI_variable_null_not_full_ci on dbo.nonunique_uniqufier_with_duplicates_CI_variable_null_not_full(id)
------ insert
insert into dbo.nonunique_uniqufier_with_duplicates_CI_variable_null_not_full(id,id1)
select id%10 , id1 from dbo.unique_uniqufier_CI
---- create the nonclustered
create nonclustered index ix_nonunique_uniqufier_with_duplicates_CI_variable_null_not_full_nci on dbo.nonunique_uniqufier_with_duplicates_CI_variable_null_not_full(id1)
----- check physical stats
select
index_level,
page_count,
min_record_size_in_bytes,
max_record_size_in_bytes,
avg_record_size_in_bytes
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.nonunique_uniqufier_with_duplicates_CI_variable_null_not_full'),2,null,'Detailed')
we would get
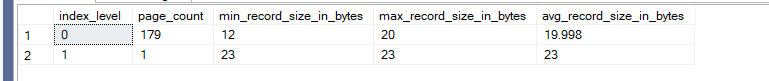
side heading, the fact that you would store null char columns as their original byte size even if they are null
now here we created the following table:
use testdatabase
create table test_null_in_char(
id int not null,
col1 char(20)
)
insert into test_null_in_char(id) values(1),(2)
insert into test_null_in_char(id,col1) values(3,'m')
so we have two nulls and one that has a value
now if we dbcc ind like:
dbcc ind ('testdatabase','dbo.test_null_in_char',-1)
We would get:

Now if we dbcc page like:
dbcc traceon(3604)
dbcc page('testdatabase',1,59792,3)
We would get the following:
Slot 0 Offset 0x60 Length 31
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP Record Size = 31
Memory Dump @0x0000007C877F6060
0000000000000000: 10001c00 01000000 8b004000 00000000 c0d07ce7 .........@.....ÀÐ|ç
0000000000000014: ea010000 00000000 020002 ê..........
Slot 0 Column 1 Offset 0x4 Length 4 Length (physical) 4
id = 1
Slot 0 Column 2 Offset 0x0 Length 0 Length (physical) 0
col1 = [NULL]
Slot 1 Offset 0x7f Length 31
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP Record Size = 31
Memory Dump @0x0000007C877F607F
0000000000000000: 10001c00 02000000 8b004000 00000000 c0d07ce7 .........@.....ÀÐ|ç
0000000000000014: ea010000 00000000 020002 ê..........
Slot 1 Column 1 Offset 0x4 Length 4 Length (physical) 4
id = 2
Slot 1 Column 2 Offset 0x0 Length 0 Length (physical) 0
col1 = [NULL]
Slot 2 Offset 0x9e Length 31
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP Record Size = 31
Memory Dump @0x0000007C877F609E
0000000000000000: 10001c00 03000000 6d202020 20202020 20202020 ........m
0000000000000014: 20202020 20202020 020000 ...
Slot 2 Column 1 Offset 0x4 Length 4 Length (physical) 4
id = 3
Slot 2 Column 2 Offset 0x8 Length 20 Length (physical) 20
col1 = m
now if you compare each you can see that each has the same size, so if you put CHAR it would store the whole thing that is why we did not insert into the char column in our example
ever-increasing clustered index issues
now if we designed and index as identity(1,1) for example, it will always be insert at the end of the page
what happens if we have high activity?
Multiple people are trying to insert, what would each insert would do?
Get an X lock on at least a row, what would that do?
Block other queries, and what would that do in our ever-increasing rows?
It would block other queries from locking the page, and what would that do?
decrease performance, increase lock_waits, and potential ‘the system is slow here’ problem
so that is one issue
this is what you call a hot spot issue where multiple insert statements compete on the same row, page, etc. causing blocking
the second one relates to statistics, and we talked about it before here as ‘ascending key statistics’(https://suleymanessa.com/statistics-in-sql-server/#Ascending_Key_Statistics)
but the main point is until the inserted values match the auto-update stats in the old cardinality estimator, the newly inserted values are not accounted for in the histogram
so the cardinality estimator will mess up
so we might get suboptimal plans
now the fix now is some traceflags or the new cardinality estimator
for more details check out the blog
last piece of advice
we can create a clustered index based on the most frequently executed queries like we did in the composite or in the included, make it covering using the clustered instead of a nonclustered
since even if we created a nonclustered it would be too wide
and if we did an update on the clustered we have to update the most important index anyway
so instead of that
just update the clustered
now these were some headers to help the design, but they are not absolute truths, so always test and see what fits your load
Types of clustered index designs
now people could use the following:
- identity(1,1) ever-increasing
- Sequence Noww both introduce ever-increasing values like we saw in identity before and we can do the same with sequence like:
now both introduce ever-increasing values like we saw in identity before and we can do the same with sequence like:
go
create sequence our_sequence
start with 1
increment by 1;
create table sequence_demo(
id int not null
constraint pk_sequence_demo primary key
default(next value for dbo.our_sequence),
col1 int)
---- now let's insert some
go
insert into dbo.sequence_demo(col1) values(1)
go 10
Now if we select* like:
select* from dbo.sequence_demo
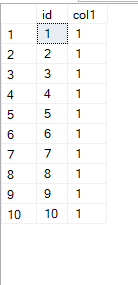
so it is the same here, obviously, there are other differences like you can use sequences across tables, etc.(for more details check out the docs)
but the main point is, generally speaking, we can generate auto-incrementing, ascending, ever-increasing clustered keys using both
now they might be less efficient in the case of highly active transactional system because of the hotspot contention, but as a stable primary key this is the best practice
now there is a third option, we touched on in fragmentation(here )
which is the newid() function
this one tries to generate instance-wise unique values, so there are no duplicates in the application
but these values could be anything
so there is no way to know what the next value could be
this could lead to random insertions and updates to the clustered key on any page at any time
which could lead to page splits, internal and external fragmentation
now let’s compare them:
Comparing ever-increasing clustered key to newid() uniqueidentifier function
Now first let’s create the tables:
use testdatabase
create table ever_increasing_demo(
userid int identity(1,1) not null,
purchase_amount int
);
----
create clustered index ix_userid on ever_increasing_demo(userid)
with( fillfactor = 100, pad_index =on);
----
create table not_ever_increasing_demo(
UserID uniqueidentifier not null default newid(),
purchase_amount int);
----
create clustered index ix_userid on not_ever_increasing_demo(userid)
with( fillfactor = 100, pad_index =on);
After that let’s do our inserts, with execution plans and statistics time on:
SET STATISTICS TIME on;
go
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into not_ever_increasing_demo(purchase_amount)
select id*20
from ids;
go
SET STATISTICS TIME off;
go
SET STATISTICS TIME on;
go
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into ever_increasing_demo(purchase_amount)
select id*20
from ids;
go
SET STATISTICS TIME off
go
now first in the not_ever_increasing
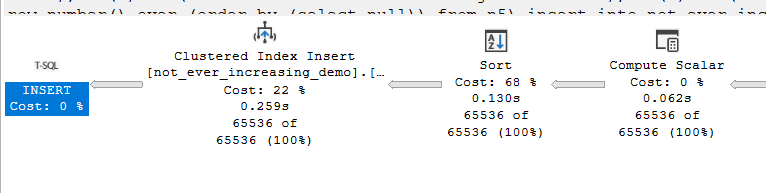
so it had to sort before insertion since the values are random and the index has a certain order
so it has to sort them and then pass them
on the other hand in the ever-increasing:
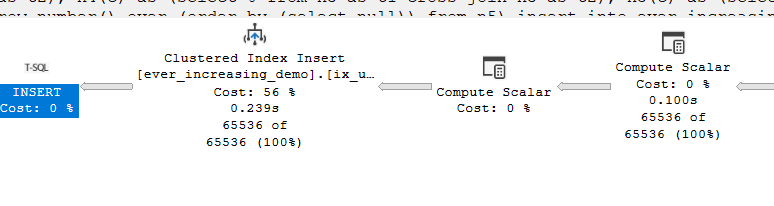
No sort, plus if we look at the execution times:
(1 row affected)
SQL Server Execution Times:
CPU time = 234 ms, elapsed time = 275 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 11 ms, elapsed time = 11 ms.
(65536 rows affected)
(1 row affected)
SQL Server Execution Times:
CPU time = 219 ms, elapsed time = 256 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
you can see it took less at the bottom the ever-increasing and more at the top the not-ever-increasing
so even in insertions it beats it
then let’s check index_physical_stats:
select
index_level,
page_count,
avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.ever_increasing_demo'),1,null,'Detailed')
---
select
index_level,
page_count,
avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.not_ever_increasing_demo'),1,null,'Detailed')
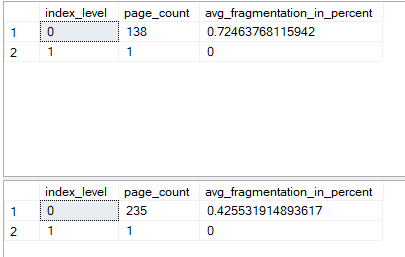
Neatly new created, other than the bigger page count since it requires more storage, we don’t see much, but what happens if we insert again like:
----
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into not_ever_increasing_demo(purchase_amount)
select id*20
from ids;
------
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into ever_increasing_demo(purchase_amount)
select id*20
from ids;
Then check physical stats again:
select
index_level,
page_count,
avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.ever_increasing_demo'),1,null,'Detailed')
---
select
index_level,
page_count,
avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.not_ever_increasing_demo'),1,null,'Detailed')
We get:
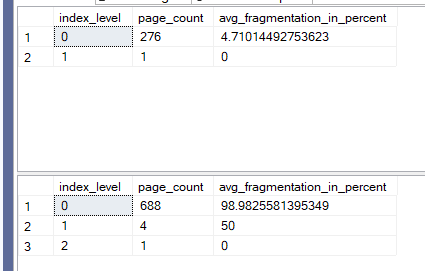
It is fragmented like would not believe so that is one reason for not using it.
Now in this we introduced the ways of designing in the next one we are going to introduce some ways to use the newid() function or replaces, with similar values, or using newid() itself but using a nonclustered that would enhance performance
see you in the next blog.