
Introduction
hi there, today we’re going to explore what a transaction is, describe concurrency models introduce isolation levels, and explain how to handle uncommitted transactions so tag along.Transactions
as with any other product of data, SQL server is designed to deal with multiple users issuing workable units at the same time, each one could be called a transaction, dealing with them without compromising consistency is what relational engines excel at, so they have modes(models) that deal with that (will be described later), to maintain this condition certain properties should be met and theses are ACID properties :- Atomicity: each unit is treated as an undividable unit, one unit, no half-stepping in here you are either in or out, meaning it’s either executed as a whole ( committed ) or rejected (rolled back) for example you have a hotel room and a guy trying to book it, now this guy wants the room and hotel wants the cash so for this transaction to be committed you need the money and the hotel room, if the client does not provide the transfer the transaction would be rolled back since there is part of it that is invalid which is the money if the hotel gave him the room without the money atomicity would be invalidated in this transaction, on the other hand if the hotel does not book the room for the client this transaction would be rolled back too since the second condition in the transaction is not met which is what atomicity is all about, which guarantees the money and the room
- Consistency: the not violation thing we mentioned previously equals this property which is ensuring that the data comes out exactly as requested and none of the constraints were violated.
- Isolation: means that each transaction is insulated from the other, going back to our hotel room guy if this guy decided he needs chips in the morning and this website has chips and hotel rooms for some reason but he did not have enough credit, SQL server will ensure that these two were executed as if they were on top of each other you know serially so one of his transactions would be rolled back, particularly the one with lower CPU cost which in this particular case is the chips even if he tried to do them simultaneously. now this level could be controlled or changed it depends on the kind of data you are dealing with.
- Durability: means that after the data has been committed SQL server will maintain it in the case of a crash which is achieved by write-ahead logging. meaning that SQL server maintains a log of each transaction before it is committed to the physical disk(SSD etc. ) ( it writes copies of what is the transaction was doing at the time of the crash so it can redo it for more information check this out ****docs )
- Dirty Reads: when you read data before it is committed which means there is a chance this stuff will never get committed, which screws up consistency. Assume we have an account with 1000 $ in balance and you tried to book the room and the room is 200$, if you view the data before it is accepted you will see the balance as 800 $ now if the hotel finds out that the room is already booked it will return the money and the balance could be 1000 $ again. now if you read the data before it is committed you 800$ will be a dirty read. even though it might get committed at some point.
- Non-Repeatable Reads: if the transaction would have been canceled you read a Non-Repeatable Read it happens when someone tries to read data between modifications
- phantom read: let's assume that a receptionist is trying to find out how many bookings there are and you are trying to book the hotel before you commit your transaction he had like 5 bookings and then you came in and booked and he tries to read it again now he has 6 bookings. So it is about having different reads each time you view the same data.
Concurrency Models: Pessimistic And Optimistic
As we said when SQL server tries to read the data it uses different ways, modes, and models to deal with ACID properties each has its uses the first one is : Pessimistic = everybody is trying to update the data so we should protect it : here it assumes everybody is going to compete with everybody write-write ( DDL data modification statements like update insert delete etc.) write-read (select stuff) and read-read. as it sounds it introduces a lot of overhead and slows down the system since every transaction is blocking the others from using the data. and the second one is Optimistic = only some people (not me (Joe Pesci)(Irishman)) are trying to update the data: only write-write will be rolled back sometimes we all just read the data let's get back to our hotel room 1000$ if a guy is trying to read something while we are booking pessimistic will block him optimistic will allow him, in optimistic he will see 1000 a first while the gut is trying to book then 800 at the end, pessimistic on the other hand will block him if the transaction is not committed yet and he will only see the 800.Isolation Levels :
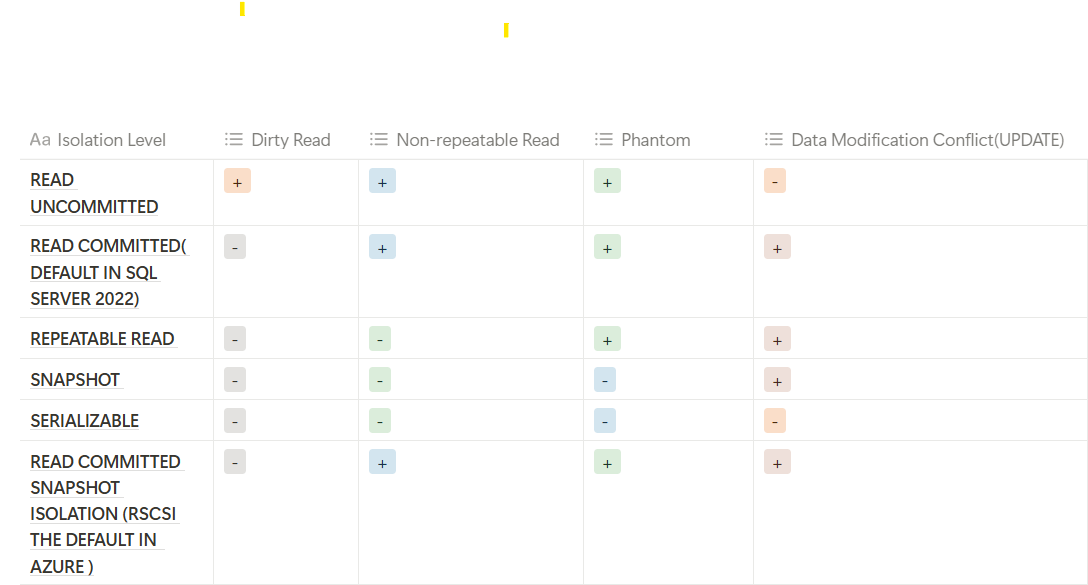
- In READ_UNCOMMITTED you basically don’t stop any data consistency you read everything dirty, clean you don’t care if the transaction is committed or not committed. it is the worst of all and should never be enabled unless you don’t have a problem with some mistakes.
- READ_COMMITTED you don’t read dirty data, the ones that have not been written to physical disk yet and you can’t modify over modification, meaning you can’t INSERT, UPDATE, DELETE on something that is already being updated and this is the same for all other isolation levels except READ_UNCOMMITTED
- REPEATABLE_READ The difference between it and the previous isolation level is the name you can’t read while modifying your own transaction otherwise if somebody else does it on the row that you read and left you might have some data inconsistency ( phantom read )
- SERIALIZABLE is the ACID itself some industries expect you to have that kind of standard it does not allow you to touch anything until we are done
- SNAPSHOT it fixes the pessimistic performance problems, which is not reading the stuff, by keeping the old version of data as readable in tempdb, so it keeps a copy of the old data that you can touch while allowing you to do whatever you want with the data this method is called row versioning, you keep an old version of your stuff read it however you want, but you can’t modify over modification, meaning there is a write_write conflict, meaning you can’t INSERT UPDATE the same row while is it being updated
- READ_COMMITTED_SNAPSHOT (RCSI) is the optimistic version of READ_COMMITTED here you can’t modify what is being modified like everybody else but you can read whatever you want since we have an old version or row_version in tempdb, you read that, so it relies on locking in writes and row_version in reads.
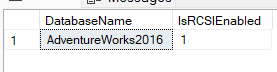
USE MASTER;
GO
ALTER DATABASE AdventureWorks2016 SET READ_COMMITTED_SNAPSHOT ON;
GO
USE master;
GO
ALTER DATABASE AdventureWorks2016 SET OFFLINE WITH ROLLBACK IMMEDIATE;
GO
ALTER DATABASE AdventureWorks2016 SET READ_COMMITTED_SNAPSHOT ON WITH NO_WAIT;
GO
ALTER DATABASE AdventureWorks2016 SET ONLINE;
GO
SELECT
name AS DatabaseName,
is_read_committed_snapshot_on AS IsRCSIEnabled
FROM
sys.databases
WHERE
name = 'AdventureWorks2016';
GO
Transaction Types
we talked about models of dealing with concurrent transactions now we’ll discuss their types : there are 3 types , the first one is the explicit one : you explicitly say BEGIN TRAN and you end it with COMMIT or ROLLBACLK in the code . if you did not explicitly code it SQL server will treat each statement as an independent transaction and it will be called autocommitted. lets look at some diagrams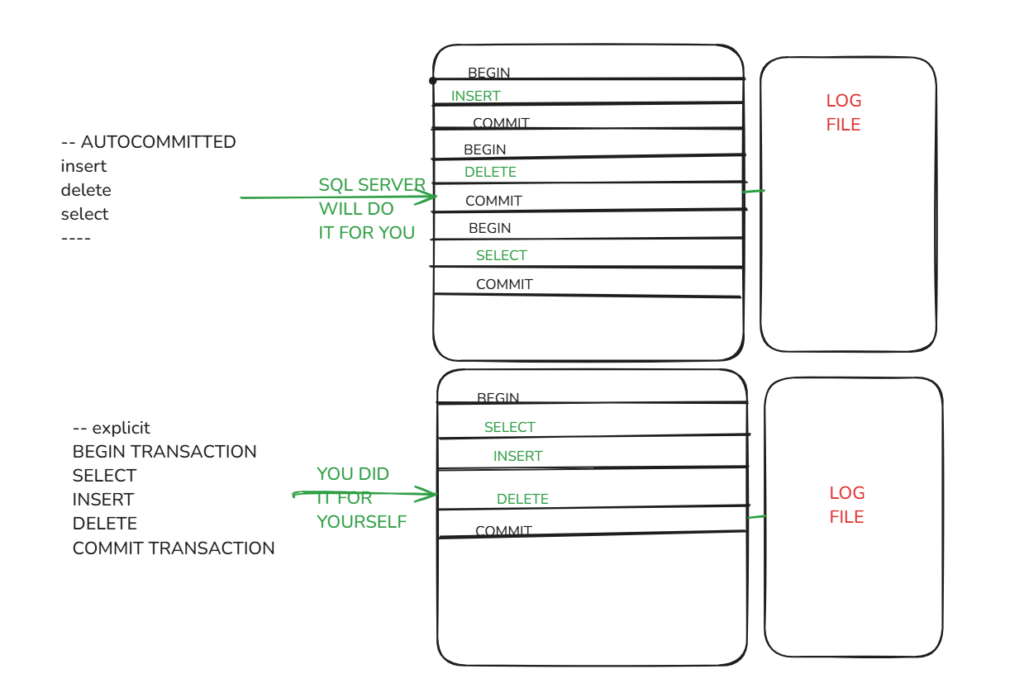 you can see from there that it takes extra effort to process implicit transactions, plus you can actually ROLLBACK your transaction cause if you did not say, in the implicit, SQL serve will not do it for you.
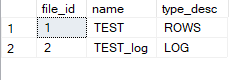
let's see that in action we will create a table that has three columns SalesId, Col1, and Col2 then we will insert 20,000 rows in there then we will query this DMV sys.dm_io_virtual_file_stats You need the database id and the log file number in order to do that you need to use DB_ID() function that will return the current database id and depending on your log file organization it will have different numbers in our case it is 2 and our database name here is TEST so first we will :
you can see from there that it takes extra effort to process implicit transactions, plus you can actually ROLLBACK your transaction cause if you did not say, in the implicit, SQL serve will not do it for you.
let's see that in action we will create a table that has three columns SalesId, Col1, and Col2 then we will insert 20,000 rows in there then we will query this DMV sys.dm_io_virtual_file_stats You need the database id and the log file number in order to do that you need to use DB_ID() function that will return the current database id and depending on your log file organization it will have different numbers in our case it is 2 and our database name here is TEST so first we will :
SELECT
file_id,
name,
type_desc
FROM
sys.master_files
WHERE
database_id = DB_ID('TEST');
 then we will do AUTOCOMMITTED VS EXPLICIT transactions :
then we will do AUTOCOMMITTED VS EXPLICIT transactions :
-- Create the table dbo.Sales with a primary key on SalesId
CREATE TABLE dbo.Sales
(
SalesId int NOT NULL,
Col1 char(50) NULL,
Col2 char(50) NULL,
CONSTRAINT PK_Sales PRIMARY KEY CLUSTERED(SalesId)
);
GO
-- Autocommitted transactions with batching
DECLARE
@SalesId int = 1,
@BatchSize int = 1000,
@StartTime datetime = GETDATE(),
@num_of_writes bigint,
@num_of_bytes_written bigint;
SELECT
@num_of_writes = num_of_writes,
@num_of_bytes_written = num_of_bytes_written
FROM
sys.dm_io_virtual_file_stats(DB_ID(), 2);
WHILE @SalesId < 20000
BEGIN
DECLARE @BatchEnd int = @SalesId + @BatchSize;
WHILE @SalesId < @BatchEnd AND @SalesId < 20000
BEGIN
INSERT INTO dbo.Sales(SalesId, Col1, Col2) VALUES(@SalesId, 'J', 'L');
UPDATE dbo.Sales SET Col1 = 'K', Col2 = 'M' WHERE SalesId = @SalesId;
DELETE FROM dbo.Sales WHERE SalesId = @SalesId;
SET @SalesId += 1;
END
END;
SELECT
DATEDIFF(millisecond, @StartTime, GETDATE()) AS EXEC_TIME,
s.num_of_writes - @num_of_writes AS number_of_writes,
(s.num_of_bytes_written - @num_of_bytes_written) / 1024 AS bytes_written_KB
FROM
sys.dm_io_virtual_file_stats(DB_ID(), 2) s;
GO
-- Explicit Tran with batching
DECLARE
@SalesId int = 1,
@BatchSize int = 1000,
@StartTime datetime = GETDATE(),
@num_of_writes bigint,
@num_of_bytes_written bigint;
SELECT
@num_of_writes = num_of_writes,
@num_of_bytes_written = num_of_bytes_written
FROM
sys.dm_io_virtual_file_stats(DB_ID(), 2);
WHILE @SalesId < 20000
BEGIN
BEGIN TRANSACTION;
DECLARE @BatchEnd int = @SalesId + @BatchSize;
WHILE @SalesId < @BatchEnd AND @SalesId < 20000
BEGIN
INSERT INTO dbo.Sales(SalesId, Col1, Col2) VALUES(@SalesId, 'J', 'L');
UPDATE dbo.Sales SET Col1 = 'K', Col2 = 'M' WHERE SalesId = @SalesId;
DELETE FROM dbo.Sales WHERE SalesId = @SalesId;
SET @SalesId += 1;
END
COMMIT TRANSACTION;
END;
SELECT
DATEDIFF(millisecond, @StartTime, GETDATE()) AS EXEC_TIME,
s.num_of_writes - @num_of_writes AS number_of_writes,
(s.num_of_bytes_written - @num_of_bytes_written) / 1024 AS bytes_written_KB
FROM
sys.dm_io_virtual_file_stats(DB_ID(), 2) s;
GO
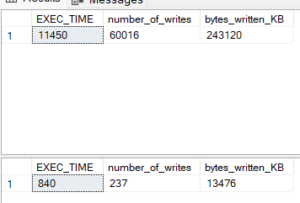 obviously the explicit required a lot less writes, storage, and execution time which is great.
the third type of transactions is implicit one , you can enable it by this :
obviously the explicit required a lot less writes, storage, and execution time which is great.
the third type of transactions is implicit one , you can enable it by this :
SET IMPLICIT_TRANSACTIONS ON;
GO
INSERT INTO dbo.Sales(SalesId, Col1, Col2) VALUES(1, 'J', 'L');
UPDATE dbo.Sales SET Col1 = 'K', Col2 = 'M' WHERE SalesId = 1;
-- Commit the transaction
COMMIT TRANSACTION;-- this is necessary
GO
-- Disable implicit transactions
SET IMPLICIT_TRANSACTIONS OFF;
GO
Expert SQL Server Transactions and Locking: Concurrency Internals for SQL Server Practitioners by Dmitri Korotkevitch Pro SQL Server Internals by Dmitri Korotkevitch SQL Server Advanced Troubleshooting and Performance Tuning: Best Practices and Technique by Dmitri Korotkevitch SQL Server Concurrency by Kalen Delaney Microsoft SQL Server 2012 Internals by Kalen Delaney
[…] from the same select while somebody else is updating for more details check out our first blog here) so it locks everything in the range of the update, this is what you call Key_Range lock. this will […]
[…] out our previous article to learn about them here(here), and for some demos check out […]