
Today we are going to introduce the following:
- Database files
- intro to transaction logs
- The way data is stored in pages
- DBCC PAGE, IND
- And more
Note: some of DMVs, DMFs, or trace flags we use in our blogs either are undocumented so Microsoft would not be resposible for any use of it if it corrupts data or introduce performance issues. and some of it introduces too much overhead. so you should not use the first unless it is a testing enviroment, and you should not use the second one in a production enviroment without the proper testing.
Database Files And Filegroups
Each database has:
- one transaction log or more that records the operations, not the data so if we modify, like deleted, it records that we deleted the page…. but it does not store the row itself, its extension is .ldf
- one primary filegroup, which could contain data and the database objects its extension is .mdf
- non, one, or more secondary database files its extension is .ndf
so each database has at least one transaction log, one primary filegroup, one to record the data itself so the inserted row will be in the primary and secondary file, and the insertion operation will be logged in the transaction log
these are the physical files
now how group them makes the filegroups so if we put the customer's data in a different filegroup and the employee’s files in a different filegroup we are logically grouping the physical files.
Why do we have a transaction log?
for data consistency, so if a crash happens we could recover it to the last point of time without the need to write it to disk
so if we were inserting a row,
and suddenly the lights went off
if we were to restart the server it should not lose any modification
even if they have not been written to the physical disk
how do we do that? By keeping a log of the transactions
then we have the physical data itself which is the primary and secondary groups
now let’s take a look at that
we are going to create a database let’s call it TestDatabase
that has the primary file, that has only the objects(tables, views, and their definitions)
and secondary file for the types of products, let’s call that table ProductType,
and a secondary file that contains the orders of our products let’s call ProductOrder
and a transaction log with the logs in it, let’s call TestDatabase_Log.
CREATE DATABASE TestDatabase ON
PRIMARY
(NAME = N'TestDatabaseDB', FILENAME = N'D:\\sql server\\sql_server_DATA\\TDDB.MDF'),
FILEGROUP ProductType
(NAME = N'ProductType', FILENAME = N'D:\\sql server\\sql_server_DATA\\ProductType_F1.NDF'),
FILEGROUP ProductOrder
(NAME = N'ProductOrder_F1', FILENAME = N'D:\\sql server\\sql_server_DATA\\ProductOrder_F1.NDF'),
(NAME = N'ProductOrder_F2', FILENAME = N'D:\\sql server\\sql_server_DATA\\ProductOrder_F2.NDF'),
(NAME = N'ProductOrder_F3', FILENAME = N'D:\\sql server\\sql_server_DATA\\ProductOrder_F3.NDF')
LOG ON
(NAME = N'TestDatabaseDB_LOG', FILENAME = N'D:\\sql server\\sql_server_DATA\\TDDB_LOG.LDF')
So we have 4 secondary files 1 for the ProductType table
and 3 for the ProductOrder table
all in d
and we have the primary
and the log
so we have two logical filegroups,
why would we separate it that way?
if we had multiple physical drives, like let’s say 3 ssds
we could separate each file on one
so we could get better I/O performance depending on the storage
also in case of a failure of hardware, we don’t corrupt all the data, instead one physical part
this would simplify our process of managing the issue
on the other hand, transaction logs are used serially, so we can’t access all log files at once
once one of them is full we go to the second etc.

as you can see we have two filegroups in orange
one log in green
one primary in blue
which constitutes the database
now let’s create a few tables on them:
CREATE TABLE ProductType (
ID INT IDENTITY(1,1) PRIMARY KEY ,
Name NVARCHAR(50) NOT NULL
)
ON ProductType ;
CREATE TABLE ProductOrder(
ID INT IDENTITY(1,1) PRIMARY KEY,
ProductTypeID INT NOT NULL,
OrderDate smalldatetime NOT NULL)
ON ProductOrder;
now we have the ProductOrder spread between disks without bothering with splitting each
we have the type in one file
we have the primary that contains the database objects
and we have the log, all in our example on d, but obviously we can separate between disks in other devices
now when we create files we can control their growth options
for example:
ALTER DATABASE TestDatabase
modify filegroup ProductOrder
AUTOGROW_ALL_FILES ;
this will grow all files when one of them starts filling up
SQL server uses a proportional fill algorithm, meaning it will grow the one that has been used, but by this option, it will grow them all at once,
now if we set it to:
ALTER DATABASE TestDatabase
modify filegroup ProductOrder
AUTOGROW_SINGLE_FILE
It will go back to the default which is growing according to filling, so it will write to it until they are all full one by one, then when the last one gets filled to the limit it will grow him only, this would make this file have more data than the others, which could make the data divided between files redundant since it used one for most of the data, we should use autogrow_all_files for our files
ALTER DATABASE TestDatabase
modify filegroup ProductOrder
AUTOGROW_ALL_FILES ;
we could delete or add a filegroup, or we could make read-only, or read-write
we could also modify it on a file basis like:
alter database TestDatabase
modify file
(
name = N'ProductOrder_F1',
size = 500 mb,
filegrowth= 100mb,
maxsize = 1000 mb
);
so here it starts at 500 MB
it will grow once it is full another hundred, and each time it gets filled it will grow
until it reaches 1GB
we could do that in the create database statements as well like:
CREATE DATABASE TestDatabases
ON PRIMARY
(
NAME = N'TestDatabaseDB',
FILENAME = N'D:\\sql server\\sql_server_DATA\\TDDBs.MDF',
SIZE = 100MB,
FILEGROWTH = 100MB,
MAXSIZE = UNLIMITED
)
log on
(NAME = N'TestDatabaseDB_LOG', FILENAME = N'D:\\sql server\\sql_server_DATA\\TDDBs_LOG.LDF')
Now here it will grow to infinity it has one primary and that is it.
we should modify in MBS, which is the default in SQL server now,
we could do it in percentile,
but each time it grows it will have a different percentile
meaning variable growth between files
how many files should we create?
Dmitri Korotkevitch suggests as a rule of thumb, 4 files until 16 logical cores
so if we have 4 logical cores 4 files
16 4 files,
then after that, we divide 1/8, and take whichever is bigger
for example
20/8= 2,…. something so 4
24/8 =3 so 4
40/8 = 5 so 5 files for this one
and it goes on
before SQL Server 2016, we could enable trace flag 1117(https://techcommunity.microsoft.com/blog/sqlserver/sql-server-2016-changes-in-default-behavior-for-autogrow-and-allocations-for-tem/384692) for the growth of all files on the whole instance but since the fixes are applied on the engine there is no need for that anymore.
Instant file initialization(vs file zeroing)
now when we create a new file SQL Server puts zeros in the new files, this is what you call zeroing, it blocks other users from using the same file, and the system slows down
in order to avoid that we can enable instant file initialization
now in SQL server 2022, you can enable that for everything, even log files if they do not exceed 64 MB, after that only log files has to go the file zeroing.
Now first you have to give SE_MANAGE_VOLUME_NAME user rights in Windows Administrative Tools, Local Security Policy applet.
How could we do that? first in the search in Windows type local security policy
click on it
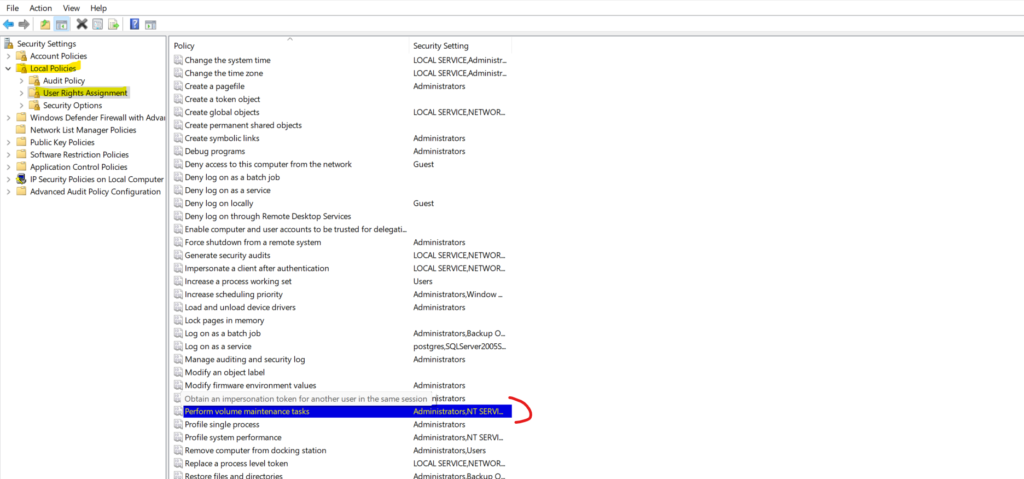
this would pop up(docs(https://learn.microsoft.com/en-us/sql/relational-databases/databases/database-instant-file-initialization?view=sql-server-ver16))
in local policies click on user rights assignment
then click Perform volume maintenance tasks
now from there, it is straightforward
you click on it
then add the users you want
click apply
and that is it
now how could we know if instant file initialization is enabled?
using trace flags 3004 and 3605 both add more information to the database error log
so let’s do that
dbcc traceon (3004,3605,-1)
Now let’s create a database called whatever and then query the database errorlog to see if the instant file initialization is enabled
create database whatever
Now query the error log
exec sp_readerrorlog
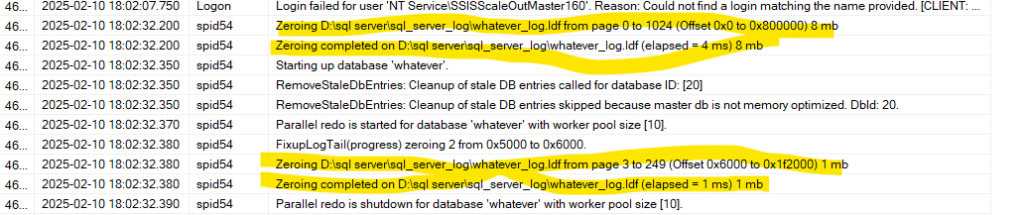
it is zeroing
so here it is not enabled
there was no zeroing for the primary
but there is for the log
so let’s apply for our local policies, restart the instance, and see where it goes.
So first let’s drop database whatever
drop database whatever
now let’s run the dbcc again, create the database again, and see if the zeroing is still there

non, so no zeroing not even for the log files unless we specify that the logs would exceed 64 MBs
so we are golden now
Data storage engines in SQL server
3 ways:
- Rowstore
- ColumnStore
- in memory
the first one stores each row for each column separately
this is the one that we will be diving into today
the second one stores it per column, we will cover it in future blogs
And the third one is the hekaton, in-memory OLTP, its stores the data in a physical disk, but while performing the operations, it does in memory, in RAM, it is the quickest we will cover that in future blogs.
But for now, let’s focus on rowstore.
Data Pages and Rows
SQL server stores the data in 8KB pages, so the minimal amount is 8KBs
the pages get numbered incrementally
it starts at 0 and it goes on
we can see their contents by providing file ID and page number using dbcc page
when SQL Server grows the number of pages it picks the highest one and adds to it
so if we had 10 and we need one more, it will add 1 so 11
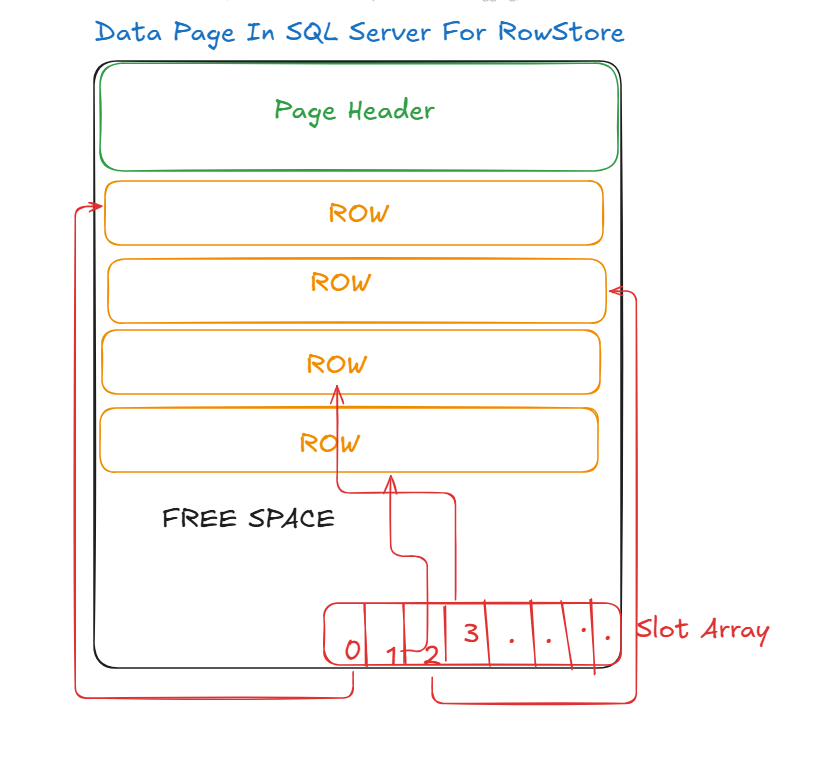
what makes this 8k page:
Page header
It contains information about the page like:
which object does this page belong to
how much free space there is in here
links to the previous and next page in an index
etc.
Data rows
the actual data, it does not have to follow the index’s order, it is stored as it suits itself
Free space
the place where there is nothing
Slot array
it stores the logical order of the data, so the data rows are stored as it fits, but their logical order is stored here, so here it fits the index’s order
it numbers it like the pages
0 for the first value so slot array 0 for the first row
1 for the second values so slot array 1 for the second value in the index or the row ID for the heap( more on it later)
and it goes on
There are a lot of data types in SQL server, but some of them are fixed length, and some of them are variable.
in the fixed length data type you store the exact amount of bytes at each row even if the value was NULL
so it uses the storage specified at each row no matter what
for example nchar(20) always uses 40 bytes
but variable length data uses as much as needed plus 2 bytes
so varnchar(20) the maximum of it is 40 but if we had a null it would use 2 bytes only
let’s explore the pages and rows in detail now
first, let’s create a table:
CREATE TABLE dbo.ExploringDBCCPAGE_IND_ALLOCATION_UNITS
(
ID INT NOT NULL,
COL1 VARCHAR(20) NULL,
COL2 VARCHAR(20) NULL
)
;
Now let’s populate it
insert into dbo.ExploringDBCCPAGE_IND_ALLOCATION_UNITS(ID,COL1,COL2)
VALUES(
1,
replicate('s',20),
replicate('e',20)
)
Then let’s insert something with nulls
insert into dbo.ExploringDBCCPAGE_IND_ALLOCATION_UNITS(ID)
VALUES(
2
)
now let’s check the first way of doing it
DBCC IND
the syntax would be like:
dbcc ind
(
'TestDatabase' /* database*/,
'dbo.ExploringDBCCPAGE_IND_ALLOCATION_UNITS(ID)'/* table name*/,
-1/* how much informatio do you want to see */
)

So:
- PageFID: File ID in the database
- PagePID: The page number in the file
- IAMFID: this is what you call an index allocation map(more on it later) now since 547 is the index allocation map it does not have one for itself, this fid = file id so the index allocation map’s file id
- and IAMPID: page id
- the object_id: the object_id for the page we are using
- indexId: is the id of the index, now since our table is a heap and we don’t have an index here it shows up as zero
- partition id: each table, even the one with no partitions, is treated as a partitioned table internally, so our table does not have a partition function or a schema, it is treated internally as one partition and its id is 720….. which our page belongs to
- partition number: the first partition
- iam_chain_type: what type of index allocation maps do we have here is in-row-data it fits in the 8k page is overflow, so some of it is outside, or is it a Large object page (https://techcommunity.microsoft.com/blog/sqlserversupport/sql-server-iam-page/1637065)(more on it later in this blog)
- Page Type: so we have these types (we will dive into them later in this blog):
- 1 data page as our second page = it stores our data
- 10 is an index allocation map or IAM page
- index level: if we had an index, at which level is this page, the leaf would be 0, and to an N level which is the root level( more on it in future blogs)
- the other columns are self-explanatory
Row structure
here we are going to explore the row structure
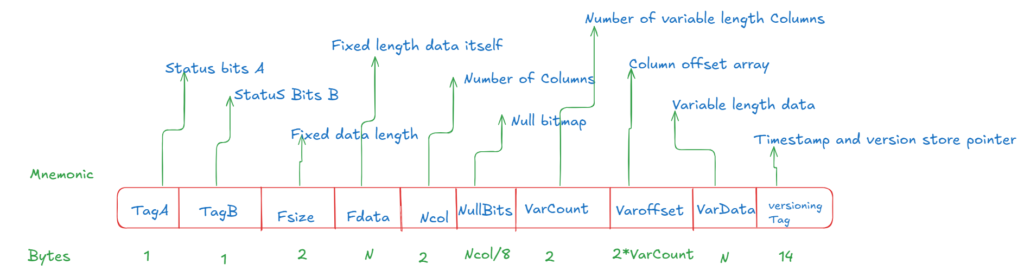
Let’s start with Status Bits A:
we have 8 bits each could be like this in binary = 000 000 00 s
each digit is presented by one of these
the first 0 is the first bit which is 0
the second 0 is the second bit which is bit 1
now if it was on it would be like = 00 00 00 10
now we know bit 1 is on
and we have hexadecimal values that has two in hex code
for example 10 = 0x10
so here we have
1
and
0
now
each hexadecimal value represents 4 binary values
so instead of writing the 8 values in binary
we write 2 values
so here we have 1 and 0
0 = 0000 so 4 values
and
1 = 0001
if we put them together side by side
0001 0000 or the 4th bit
or
0x01 = 0000 0001
which is the bit 0 or the first bit is on the other are off
another example:
0x02 = 0000 0010
which equals the first bit
Another example:
0x04 = 0000 0100 the bit 2
Another example:
0x08 = 0000 1000 the bit 3
Another example:
0x20 = 0010 0000 the bit 5
Another example:
0x40 0100 0000 the bit 6
Another example:
0x80 1000 0000 the bit 7
If the first byte for example:
10000800010000000
10 here is = 0x10 = 0001 0000 = the bit 4
bit 0 =equals row versioning information it is always 0 now
bit 4 = Is there a null bitmap internally it is always is
how could it do that?
it should be 000
i ran the following( more on the code later, for dbcc page but for the point of proving this point we are going to put it here, you can just skip it for now)
create table dbo.bit4_test(
id int not null
)
insert into bit4_test(id) values(1)
Then ran dbcc ind:
dbcc ind
(
'TestDatabase' /* database*/,
'dbo.bit4_test'/* table name*/,
-1/* how much information do you want to see */
)
the output was

then i ran dbcc page( more on it later this was just for proving this bit:
dbcc traceon (3604)
dbcc page(
'TestDatabase',
1, 576, 3)
The row was like:
10 00 0800 0100 0000 0
we are concerned with the 10
= 0x10 = 0001000 and it is the only on thing in here
so even though there are no nulls, there is a null bitmap
bit 5: 0010 0000 = 0x20 if it has a variable length column
now let’s prove that:
First, create a table that has a variable length column:
CREATE TABLE VAR_TEST
(
ID VARCHAR(4)
)
INSERT INTO VAR_TEST(ID) VALUES('50')
Then dbcc ind:
dbcc ind
(
'TestDatabase' /* database*/,
'dbo.VAR_TEST'/* table name*/,
-1/* how much informatio do you want to see */
)
The output was:

So we dbcc page it:
dbcc traceon (3604)
dbcc page(
'TestDatabase',
1, 584, 3)
And the row was like:
30000400 01000001 000d0035 30
we are concerned with 30 now
so it is 0x30 = 0011 0000 so
4 zeros no mystery
but we have two bits on
4 which means there is a null bitmap(always on)
and bit 5 = it is a variable column
bit 6: this indicates if we have row versioning on on this column
bit 7: it is not used, so always 0
now for bits 1 to 3:
now since bit 0 is always 0 we could focus on the next 4
if the next 3 bits were like 000 = primary record
if it was like 001 = forwarded record = heap that is moved
if it was like 010 = forwarding stub = placeholder in heap movements( more on it later)= heap record that has been moved and this points us to i
if it was like 100 = blob or overflow data
if it was like 101 = so two bits = a ghost index record, so i has been deleted, but the transaction is yet to be committed
if it was like 110 = so two bits = a ghost data record
if it was like 111 = 3 bits = a ghost version record = we enabled rcsi and updated the row and use row versioning and after that, this new row version got updated again and now it is ghosted
so status bits a is done we move on to the next byte which is
status bits b:
it could have two values 0x00 or 0x01 in our latest row:
30000400 01000001 000d0035 30
so the first 30 we talked about it
now 00 = 0x00 = 00000000 = it is not a ghost forwarded record if it was, it would have been 0x01
now for the fixed data length bytes the 3rd and the 4th or bytes 2 and 3 since it did start at 0
10000800 01000000 010000
10 was gone it just indicated we had a null bitmap
00 It is not ghosted
0800 in little-endian hexadecimal values it is stored the least significant first so = 0x0008 =
now for the actual fixed length data which is 01000000
now here we have 4 bytes because the integer has 4 bytes
it equals = 0x00000001= the first zeros means nothing and the last one means the data is 1 like we did
since we knew the column we knew it otherwise we have to guess
now the next bytes in our case 2 bytes is about the how many columns is there or NCOL
no, here we have 0100 or 0x0001 = we have one column
if we had two like:
use testdatabase
create table two_col_bitmap(
col int ,
col2 int
)
--- then we insert
insert into two_col_bitmap(col,col2) values(5,6)
dbcc ind(
'TestDatabase',
'dbo.two_col_bitmap',
-1)
dbcc traceon(3604)
dbcc page(
'TestDatabase',1,640,3)
One of the rows was like:
10000c00 05000000 06000000 020000
so we have 2, 4 bytes 5, and 6 a
and the next byte was 0200 or 2 columns = n columns
now if we had 200 cols like:
USE TestDatabase;
CREATE TABLE dbo.[200_col_bitmap] (
col1 INT,
col2 INT,
col3 INT,
--- it goes on
col199 INT,
col200 INT
);
then insert like we did before
then dbcc ind
then dbcc page(with 3604 on)
we get the following row
at the end of the page
02000000 c8000000
so after the last int 2 data itself, we should see C800 or 0x00C8 = 200
So a byte for the number of columns
now the next bytes for the null bitmap or nullbits it shows one byte in our example it is 00 or 0
now if we had a null like:
create table null_bitmap_test(
col int,
col1 int,
col2 int)
insert into null_bitmap_test(col,col2)values(11,12)
dbcc ind
('TestDatabase',
'dbo.null_bitmap_test',
-1)
dbcc traceon(3604)
dbcc page(
'TestDatabase',
1,,3)
Our row was like:
10001000 0b000000 f8440000 0c000000 030002
0b is 11
and the one after that 12
0300 is the number of columns
02 is the null bitmap = so the second column is the null
now if we have 2 columns as null like:
create table null_test(
col1 int,
col2 int,
col3 int
)
insert into null_test(col1) values(1)
dbcc ind
('TestDatabase',
'dbo.null_test',
-1)
dbcc traceon(3604)
dbcc page
(
'TestDatabase',1,672 , 3)
10001000 01000000 f8440000 00000000 030006
so we have 10 status A = 0x01= only null bitmap is on
00 = not a ghost status b
then the data length
then we have 4 bytes col1 integer
we are still in the rows
col2 has the next 4 bytes (another_tool) byte-swapped in this website it would show as a 0 which indicates null
then col3 = zeros means a null
ncol = 2 bytes = 0300 = 0x0003 which means 3 columns in here
then the null bitmap which is 1/8 of ncol in bytes now here it is 06 so one byte
this byte = 0x06 = 0000 0110 so the first row is 0
the second is 1 = it is null
the third is 1 = it is null meaning col3
and the others indicate there is no nulls in there
now here since we did not have any varbinary we could not see it but if we wanted to we could
use testdatabase
create table var_test
(col1 char(4),
col2 varchar(4),
col3 varchar(4)
)
insert into var_test (col1,col2,col3)values('s','t','stem')
dbcc ind
('TestDatabase',
'dbo.var_test',
-1)
dbcc traceon(3604)
dbcc page(
'TestDatabase',
1,584,3)
Now let’s explore the dbcc page:
0000000000000000: 30000800 73202020 03000002 00120016 00747374 0...s .........tst
0000000000000014: 656d em
Slot 0 Column 1 Offset 0x4 Length 4 Length (physical) 4
col1 = s
Slot 0 Column 2 Offset 0x11 Length 1 Length (physical) 1
col2 = t
Slot 0 Column 3 Offset 0x12 Length 4 Length (physical) 4
col3 = stem
30 = status bit a = 0011 0000 = it is a varchar and has a null bitmap
00 = status bit b = not ghosted
now we should have the fixed data size and the data itself
now we know the offset of the second 0x4
so it starts after the 4th byte
we know it takes 4 bytes no matter what so
between 4 and 8 we should find our value 73202020 = s in our tools according to our collation
now the bytes 0800 should equal the size =in binary 0000000000001000 = so it is 4 bytes since the 4th bit equals the size
now at 9, we should have two bytes that contain the ncol or the number of columns
0300 = 3
now after that, we should get nullbits or ncol/8 = 1 byte
it is 00 so 0 since all our stuff is full
now we have the varcount = number of variable columns for two bytes
0002 = 2 columns
now the next vardata is supposed to be at 0x11 or 17
and the one after that is supposed to be at 0x12 or 18
747374 656d = tstem the last bytes so for t we need 1 byte and for stem 4 so we should see 5
and we see it so after 17 until the end we see the vardata
now between them and the previous bytes we have 00120016 00
we should see varcount and varoffset
varcount needs two bytes
so 0012 now I don’t how to interpret this
now we have varoffset = 0016 = the variable offset starts at 16 so it is right since our previous discussion proved that adding two zeros would not change the outcome
this is for today’s part 1, in part 2 we will look into more data types in the dbcc page