
In the previous blog, we introduced the first physical implementation of joins, nested loops. Today, we are going to introduce the second way of joining, the Merge Join.
Now, this algorithm needs two extras, sorting and equijoins
Intro
Now, A merge join works by comparing the first table to the second row by row, if the the second table’s row matches the first, then it is passed, if not then it moves to the next value, and we know that the values are sorted, since it is a requirement for this join, so once you pass a value you don’t comeback to it since you know it is not coming back
If we wanted to explore the algorithm’s pseudocode like Craig Freedman showed us:
Algorithm
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
return (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
So as you can see, it goes, gets the first sorted row, joins if there is a match, we are golden, if not, move on to the next row in r1 since the input is sorted, and the game is supposed to find one immediately, so:
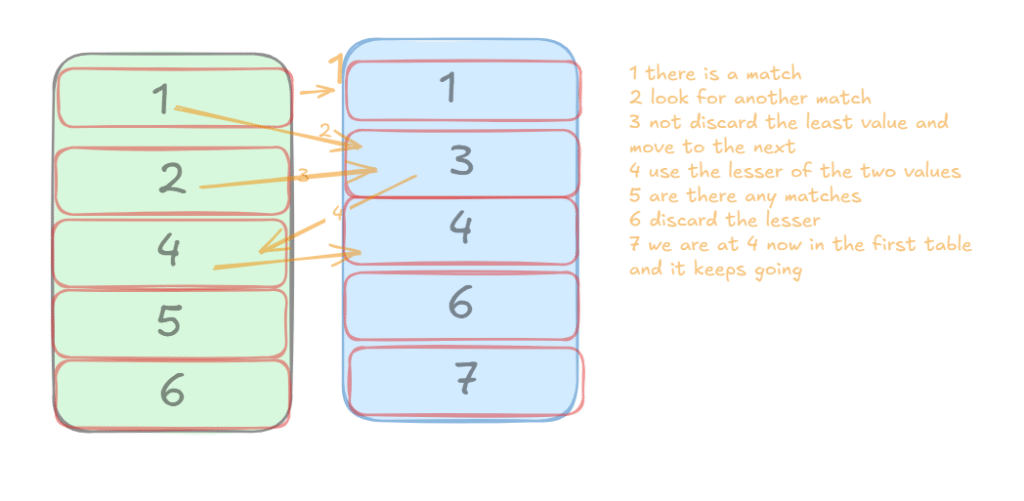
Since the input is sorted on both sides, when we dicard we don’t lose any rows if we dicard the lesser, and the next row must be a match, otherwise, if there is no match in the next row, and the lesser is discarded, then there is no way the next would be a match, so we can move on, and that is what a merge join does.
As you can see here, we read the rows once, unlike the nested loop, where you have to read the entire inner input for each outer row.
And the cost is the sum of the rows of inputs.
We can see that in here:
use adventureworks2022
go
select SalesOrderDetailID,soh.SalesOrderID
from sales.salesorderheader soh inner merge join
sales.salesorderdetail sod on sod.salesorderid = soh.salesorderid
go
We get:
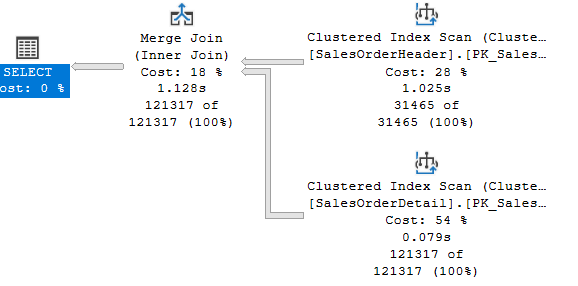
We don’t see a sort since the index has the input sorted,
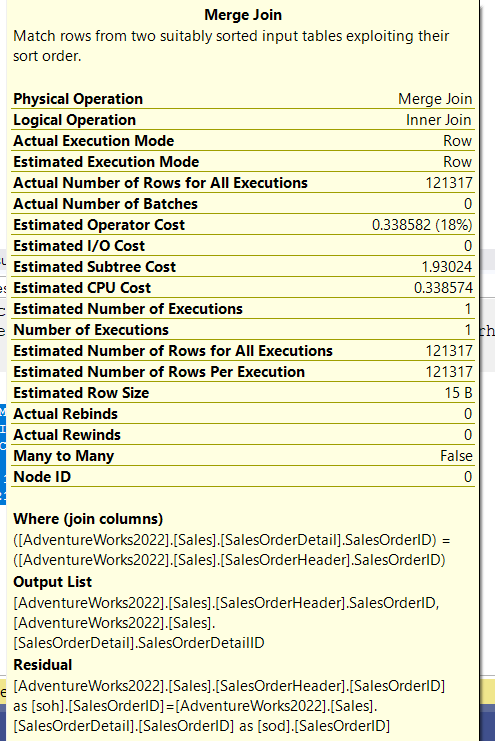
The residual is for internal purposes only, otherwise, we already know that the SalesOrderId = SalesOrderID since we have a fk-pk relationship, and we output the rows we want from the joined tables, nothing much, where we have the SalesOrderID matching.
And we see a property here, the many-to-many = false
Meaning here we are assuming that we will never encounter any other row from input one again, meaning, there are no duplicates from input, but we might have duplicates from input 2
But, what if we had duplicates? Then it is a many-to-many join; in that case, we keep a copy of whatever row we encounter in a match, so whenever we have a join, we keep a copy in a temp table
So far, so good, or maybe bad.
That way, if we find there is a duplicate, we can playback the rows again to compare if they match again.
If we realize that the next row is not a duplicate, and since we have a sort, we can discard the stored table row and move to the next until we realize there is no duplicate again.
The more duplicates we have in table 2, the more storage we need
Now, since we have to re-read and store in a temptable, it is slower than a one-to-many
And in order to use it, the optimizer needs to know that the rows it has are unique, like in our case, no duplicates.
Or a distinct operator, or a CTE expression that guarantees uniqueness, a subquery, or a group by.
We can sort merge join on multiple predicates:
select*
from sales.salesorderheader soh inner merge join
sales.salesorderdetail sod on sod.salesorderid = soh.salesorderid
and sod.rowguid = soh.rowguid

In the merge join:

The sort order does not matter:
go
select*
from sales.salesorderheader soh inner merge join
sales.salesorderdetail sod on sod.rowguid = soh.rowguid
and sod.SalesOrderID = soh.SalesOrderID
would still work
It supports full outer join and inequality predicates:
select*
from sales.salesorderheader soh full outer merge join
sales.salesorderdetail sod on sod.rowguid = soh.rowguid
and sod.SalesOrderID >soh.SalesOrderID
Now, if we look at the merge join:

Now, you can see that the join predicate is only the rowguid, so it can’t use the salesorderid in the merge since it is an inequality predicate, but we can see it in the residual, there we can see it satisfied our condition, but it was not used in the join
Instead, after matching each join column, it looked for the second predicate, does it evaluate true, if yes, output, do not discard
And, instead of not outputting nothing, meaning no output, here, since we want a full outer join, it just outputs a null.
We can also merge on no equijoin predicate like:
select*
from sales.salesorderheader soh full outer merge join
sales.salesorderdetail sod on
sod.SalesOrderID >soh.SalesOrderID
And we get the estimated as:
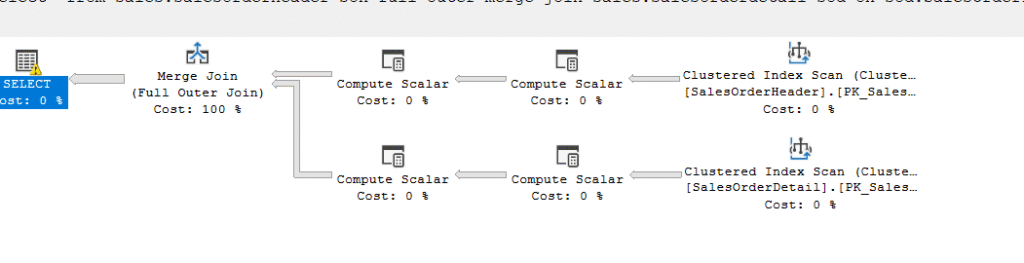
If we look at the properties:
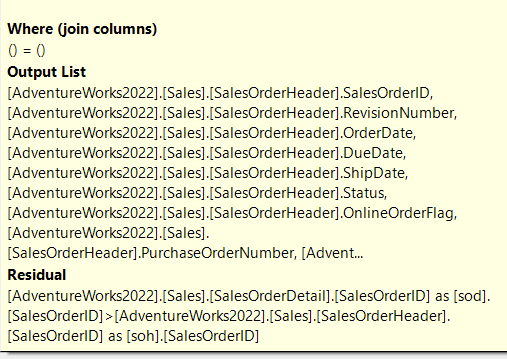
As you can see, no join predicate; it just filtered on the residual.
And with that, we finish this intro.
[…] the previous two blogs, we introduced two physical implementations of joins in SQL Server: nested loop join and a merge […]