
Intro
we know that SQL server allocates data in extents, 8 8kb pages,
each page has a pointer to the next and previous page
now in indexes, pages are sorted on index key value
we know that SQL server can not modify data on disk, it has to get it to memory, read it there, modify it there, while modifying it logging it in the log file, then after that, it writes the changes in memory, then a lazy writer process writes it some time to disk, and then the change would be passed to disk
now reading from disk causes physical reads
reading from memory causes logical reads
now reading logical reads requires CPU so even though, the pages are cached and are quick to read, we have a resource that we must spend to get the pages, plus memory is limited at some point
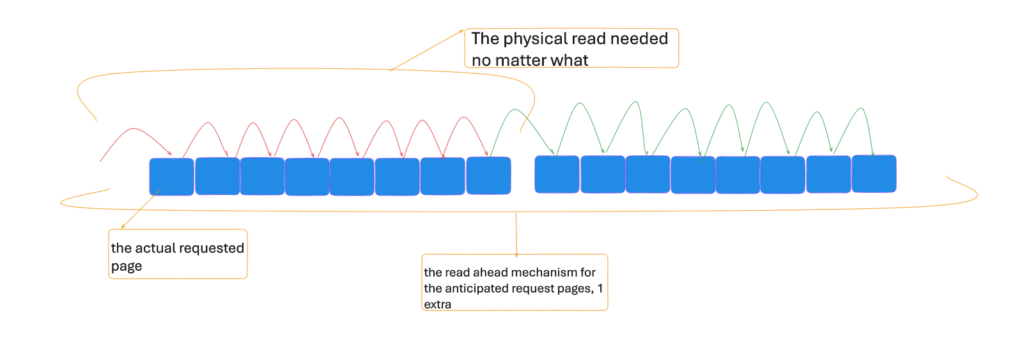
one way that SQL server try to make queries quicker, is by read-ahead pages, or reading physical pages that have not been requested by the current query, but it might be needed in the next one, so instead of random I/O it reads sequential ones, thus it reads ahead of request.
This makes more logical reads, since most of potentially needed pages are cached in memory.
now it does that depending on the fact that we have no fragmentation in our system
since the index key is the sorting order, and we need to read based on that
let’s assume we wanted to add a row to the 9th page, what would SQL server do?
first, it would see if the page fits such value, if it could then it would add it
if not:
- it would allocate a new extent for the page
- split the page in half
- add some of the data from the old page to the new page
- point toward the new page to maintain logical order
now why would it need to insert it there? the index key,
our value fits in there
no place
new extent
and page split
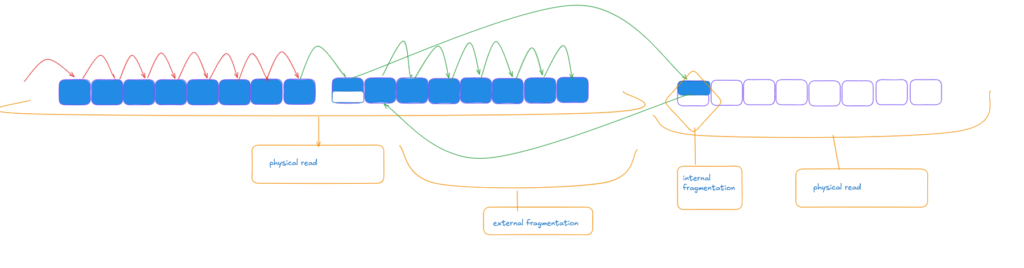
same could happen while updating a varchar row in place if it increases its size we showed that before.
So we have two kinds:
internal = we have free space = fill factor = pad index
and external = a page split happened that moved our key to another extent, so we have to introduce another physical read to read that page, thus increasing overhead, and logical consistency could only be maintained if we go get it and come back and keep going
so we have two orders now
physical order, which is how the pages are laid out in the files like the 13th page in the file which is half-filled = has internal fragmentation
and logical order, which is the index’s order, which has our pointers
now here 13th page has 9th page keys
now internal fragmentation is not entirely a bad thing, actually, it could be good, like for example, if we had free space in the page, our split could have been avoided if our row was there in the VARCHAR but since it could not, we had to move it somewhere else
however, if we add that to an ever increasing value like surrogate key id in our examples, since the values would always be inserted at the end, always increasing, we can’t use the free space, so we end up with wasted space and more reads, more CPU, more memory.
Now let’s see that in action:
create table frag_demo(
id int,
col1 varchar(1700));
create nonclustered index ix_col1 on frag_demo(col1);
insert into frag_demo(id,col1) values
(1,replicate('a',1000)),
(2,replicate('b',1000)),
(3,replicate('c',1000)),
(4,replicate('d',1000)),
(6,REPLICATE('f',1000)),
(7,REPLICATE('g',1000)),
(8,REPLICATE('h',1000));
dbcc ind('TestDatabase','dbo.frag_demo',2);
We get the following:

Now as you can see we have one index page that fits the whole thing, contains all our values
What happens if we insert e in the stream?
insert into frag_demo(id,col1) values (5,replicate('e',1700))
Then dbcc ind the index again:
dbcc ind('TestDatabase','dbo.frag_demo',2);
We would get the following:

so, we see our split, and we see that the root page has been created since our index is no longer fitting on one page
this is what you call external fragmentation
Now if we dbcc page the first page like:
dbcc traceon(3604);
dbcc page('testdatabase',1,456,3)
We would get the following:

so we no longer have f,g, and h, on this page they are on another page
now here the logical order is still maintained since, so no logical pointers, but still we have our split
now, it is impractical to monitor fragmentation using dbcc page and dbcc ind
So we have some DMVs:
sys.dm_db_index_physical_stats
Now this DMF provides us with the following:
select*
from sys.dm_db_index_physical_stats(
db_id(),
object_id(N'dbo.frag_demo'),
2,
null,
'DETAILED');
now the first parameter is our database id, no surprise, that function gets the current database id if not provided,
the second one is like the first one,
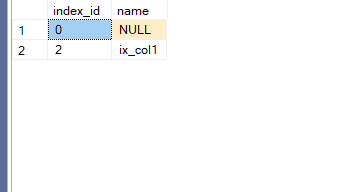
2= index_id= now here since it is the first nonclustered index in our table, it is always 2, if we did not know that we can query sys.indexes like:
select index_id,name
from sys.indexes
where object_id= object_id(N'dbo.frag_demo')
now after index_id, we have partition id
then after that, we have the mode of sampling
there are 3:
- detailed: samples all the table
- sampled: samples 1 percent of the table, if the table has less than 10 000 pages it is the same as detailed
- limited: if it is an index, it does not sample the actual pages, it only goes through the non-leaf pages, then estimates based on some algorithm, for heaps it scans some pages, plus IAM and PFS page information
now in our query, the output was like this:

:
- database_id
- object_id
- index_id
- partition_number
- index_type_desc
- alloc_unit_type
- index_depth: now here we only have two levels, root and leaf so 2
- index_level: 0 is our first nonclustered index page and 1 is the root page
- avg_fragmentation_in_percent: now here as you can see we are 50 percent fragmented= meaning here in all pages we have 50 percent fragmentation in leaf pages,
- fragment_count: how many pages have been fragmented in our case it was 1
- avg_page_space_used_in_percent: how much of a page in this level is full ours was 54

- record_count: how many rows
- ghost: delete marked but yet to be deleted
- version_ghost_record_count: here if we had RCSI or SI on
- min and max record size = size
- forwarded_record_count: only in heaps here, we have index levels and they point us in the true direction
- compressed_page_count: we did not enable it here so 0
- hobt_id: now since each table, even the one without partition on is treated as a partition, this is the hobt_id of that partition
- columnstore_delete_buffer_state: this is a rowstore index

- same goes here
- version_record_count: how many records have been created for this specific index since the last modification, only applies in accelerated database recovery mode
- in_version_record_count: how many are there to get selects fast
- diff: how many of them are kept in terms of differences from the main version
- total_inrow_version_payload_size_in_bytes: size of the total
- offrow_regular_version_record_count: how many version rows are there for the rows that are not kept inside the row of the original data row
- offrow_long_term_version_record_count: count of records in the online index rebuild where RCSI or SI is enabled
now here we might only need:
select page_count, avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(db_id(),
object_id(N'dbo.frag_demo'),
2,null,'detailed')
FILLFACTOR and PAD_INDEX
fill factor = free space until insertion = internal fragmentation
on leaf-level pages,
now the default = 100 = 0 = which means no free space
now if we don’t specify it SQL Server uses server-based configuration
now we can overrule that, for example:
Now if we create a table like:
use testdatabase
create table fill(
col1 int,
col2 int);
with
n1(c) as (select 0 union all select 0),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select ROW_NUMBER() over( order by (select null)) from n5)
insert into dbo.fill
select id,id*2
from ids
create nonclustered index ix_col2_fill_test on dbo.fill(col2) with (fillfactor = 70)
Now after that if we query the following:
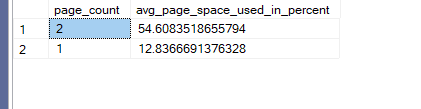
select index_level,page_count,avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.fill'),2,null,'detailed')
We get:
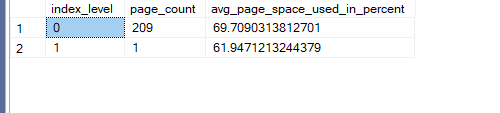
as you can see it filled 70 percent of each page even after creation instead of filling the first to 100 and the second to whatever……
now assume we inserted more rows into the table, like:
go
with
n1(c) as (select 0 union all select 0),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select ROW_NUMBER() over( order by (select null)) from n5)
insert into dbo.fill
select id,id*2
from ids
go 12
now here we inserted the same thing 12 times
we know that SQL server only uses fill factor while creating an index or rebuilding it, not while doing actual insertions, actual workload Paul Randal
then we query the DMF again:
select index_level,page_count,avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.fill'),2,null,'detailed')
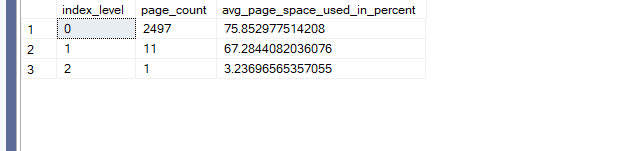
we can see that the fillfactor has been exceeded by 5 percent,
now if we rebuild the index like this:
alter index ix_col2_fill_test on dbo.fill rebuild with(fillfactor = 70)
And query our DMF again like:
select index_level,page_count,avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.fill'),2,null,'detailed')
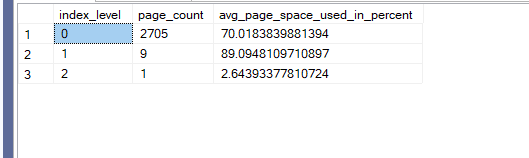
We can see the 70 percent fill factor being adhered to.
Now if we increase the fill factor as we did here, we reduce the chance of page splits, as you can see, we had to insert the same amount of rows 12 times to get a 5 percent bump in filling, now this reduces external fragmentation a lot, thus reducing logical and physical reads.
but at the same time, it increases our index’s size by 30 percent, thus increasing logical and physical reads from another angle, figuring out the right balance depends on the production load, so we need to test this fillfactor in production, until we reach the hot spot,
but generally speaking, ever increasing values do not benefit from internal fragmentation since, it adds the rows at the end of each page and does not need a fill factor because an old id was altered, we can’t do that, only new ones are inserted on that key
more on patterns that introduce fragmentation later
we have the other fill factor option, which is the pad index
now as you can see in the last DMF results, we did not have a fill factor in intermediate or high-level pages, now if we want to do that we can simply:
alter index ix_col2_fill_test on dbo.fill rebuild with(fillfactor = 70, pad_index = on)
And if we query our DMF:
select index_level,page_count,avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.fill'),2,null,'detailed')
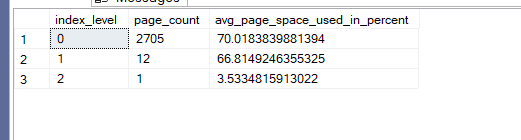
as you can see now all the stuff has the 70 percent thing
Index Maintenance
now we have two options to reduce fragmentation, index rebuild or index reorganize
now index reorganize( or defragment) is an online operation, that can be interrupted without losing progress, it reorders the leaf-level pages into their logical order and tries to compact the results by reducing internal fragmentation,
it could be done like this:
alter index ix_col2_fill_test on dbo.fill reorganize
now we can use this to regain space from LOB data deletions, since these pages are not re-owned unless we order that manually
or we can index rebuild like we did before
now the thing is with index rebuilds, they are not all online, as a matter of fact, it is only an enterprise edition feature,
offline index rebuild takes time, and they acquire Sch-m modification locks(more on them here )
which is the least compatible lock, while doing that no one can do anything
index rebuild is an all-or-nothing operation, so even an online one, would roll back if interrupted.
enterprise edition has the ability to allow online index rebuilds,
online operations use row-versioning and do not acquire Sch-M locks until the end
this could cause blocking in a very active system
we could solve that by low-priority locks, but even then we might have to rollback the transactions
in offline index rebuild, it takes the old index, and builds a new copy
in the online one, it has copies, if modifications happen during the process,
this means that an offline operation would need the same amount of space
an online one would need at least the same and 30% more
meaning it needs a lot of space
finally, index reorganize does not update statistics while index rebuild does
for now, this is a nice intro to the world of index rebuild and reorganize, see you in the next blog