
Indexes with included columns:
now before, we talked about creating composite indexes, there we provided two columns as keys for an index
we saw it had to store the keys and their ranges in the intermediate and root pages, plus the leaves
What if we just wanted to store them in the leaves, not in the upper levels?
we can use indexes with included columns, thus providing a new way to avoid key or RID-lookup
when we avoid key-lookup, by including some columns in the nonclustered definition,
we are making a query covering since it does not need to process any clustered index pages or levels
now if we need a key-lookup SQL server tends to favor an index scan of the clustered instead, since it has sequential i/o and would get all the rows, instead of running the results of the nonclustered with a nested loop join.
now if we implement the covering queries technique we are golden, only leaves need to be modified and we don’t need to read the intermediate and root pages again
but if we include as the rightmost key in composite indexes we have to include them there too
which means bigger storage, and heavier reads of intermediate and root pages
plus we have a size limitation in composite which was 1700 bytes
plus we can’t store LOB storage as a key
but in included columns, we can do both
plus if we modify the included column definition, we only have to add it the data pages, meaning we don’t need to modify the root and intermediate, meaning fewer page splits and fragmentation
let’s try it
use TestDatabase
go
create table inc_ix_ex(
col1 int,
col2 int,
col3 int);
with
n1(c) as (select 0 union all select 0),
n2(c) as (select 0 from n1 as f1 cross join n1 as f2),
n3(c) as ( select 0 from n2 as f1 cross join n2 as f2),
n4(c) as (select 0 from n3 as f1 cross join n3 as f3),
n5(c) as (select 0 from n4 as f1 cross join n4 as f2),
ids(id) as (select row_number()over(order by(select null)) from n5)
insert into inc_ix_ex
select id,id*2,id*4
from ids
Now let’s create our nonclustered:
create nonclustered index ix_include_e on inc_ix_ex(col1)
Now if we select like:
select*
from inc_ix_ex
where col1 = 20
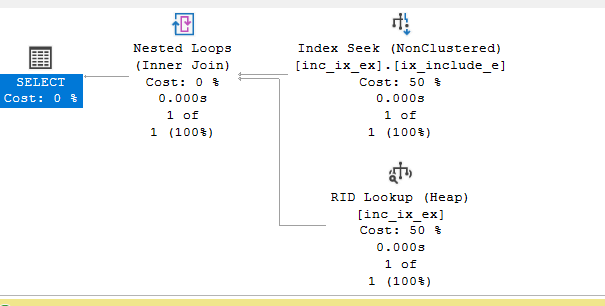
we get a RID-lookup
now we have already tried the composite index before, now let’s try the include option
create nonclustered index ix_include_e on inc_ix_ex(col1) include(col2,col3) with(drop_existing = on)
Now let’s run the select again:
select*
from inc_ix_ex
where col1 = 20
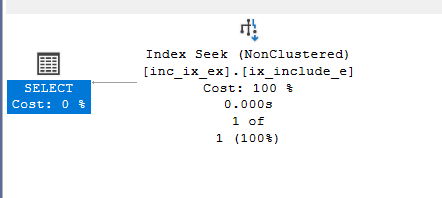
now no RID-LOOKUP
now if we dbcc ind the index with its id(we can get it from sys.indexes but the index_id for the first nonclustered index is always 2):
dbcc ind('TestDatabase','dbo.inc_ix_ex',2)
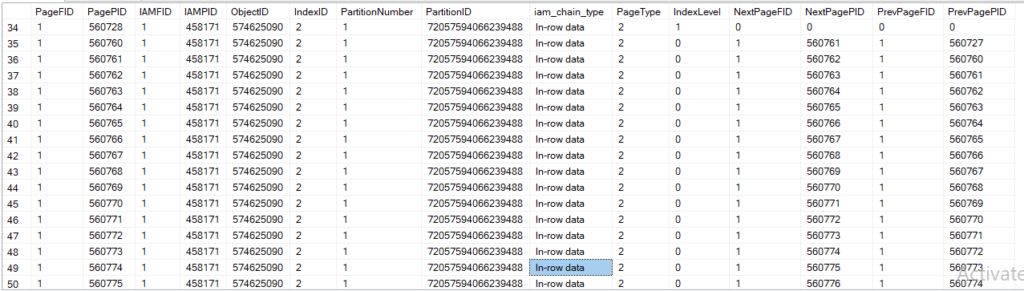
now as you can see we have one root page and no intermediate pages
now if we dbcc page the root:
dbcc traceon(3604)
dbcc page('TestDatabase,560728,1)
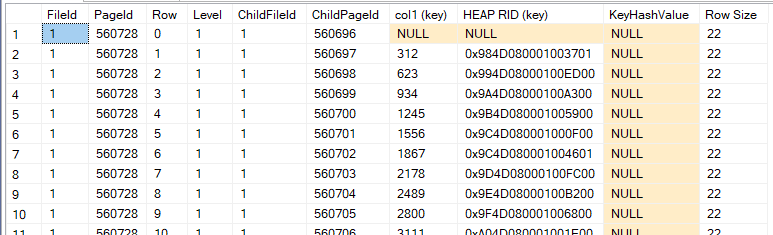
now you can see it only stores the first column or col1 in the root page unlike the composite
and since it is a heap it stores its physical location as RID or row id now if we check the output:
Allocation Status
GAM (1:511232) = ALLOCATED SGAM (1:511233) = NOT ALLOCATED PFS (1:558072) = 0x40 ALLOCATED 0_PCT_FULL
DIFF (1:511238) = CHANGED ML (1:511239) = NOT MIN_LOGGED
Slot 0 Offset 0x60 Length 22
Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP Record Size = 22
Memory Dump @0x00000031E3376060
0000000000000000: 16010000 00984d08 00010000 00388e08 00010002 ......M......8.....
0000000000000014: 0000 ..
Slot 1 Offset 0x76 Length 22
Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP Record Size = 22
Memory Dump @0x00000031E3376076
0000000000000000: 16380100 00984d08 00010037 01398e08 00010002 .8....M....7.9.....
0000000000000014: 0000 ..
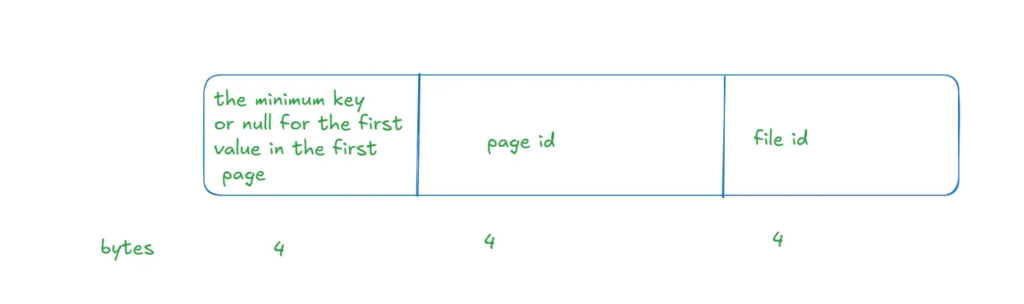
Now we have two slots:
00088E38 = 388e0800= page id in the first and 00088E39 = 398e08 00 = page id for the second
the last are for the file id
0138 is the 2-byte presentation of 317 which is the second’s key and the first has the null with 16 for the first byte
rid should be stored which in hex was 0x984D080001003701 for the first which is equal to 00984d08 00010037 01 same for the second
and that is it, so it only stores the col1’s value and RID
now if we look into the first index page like:
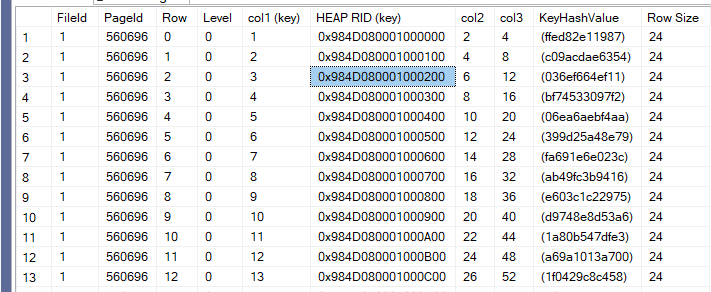
Slot 0 Offset 0x60 Length 24
Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP Record Size = 24
Memory Dump @0x00000031DADF6060
0000000000000000: 16010000 00984d08 00010000 00020000 00040000 ......M.............
0000000000000014: 00040000 ....
Slot 1 Offset 0x78 Length 24
Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP Record Size = 24
Memory Dump @0x00000031DADF6078
0000000000000000: 16020000 00984d08 00010001 00040000 00080000 ......M.............
0000000000000014: 00040000 ....
so we have the RID in the 4th to the 12th byte 0x984D080001000000 and 1
we have 4 bytes for col1 1 in the after 16 the first byte, col2 2, col3 4 as we expected
we have the 16 at the first
and I don’t know what 16 means
or 4 at the end
so it stored the whole thing, it stored the col1 and row id first then the columns as we expected
what about SARGability:
Example 1
SELECT *
FROM inc_ix_ex WITH
WHERE col2 = 4;
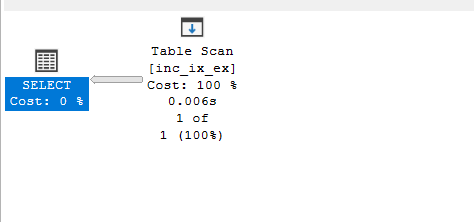
so it scans here as in the composite, so without the leftmost we can’t
we can prove that by hinting like this:
SELECT *
FROM inc_ix_ex WITH (INDEX (ix_include_e), FORCESEEK)
WHERE col2 = 4;
We would get the following error:
Query processor could not produce a query plan because of the hints defined in this query.
Resubmit the query without specifying any hints and without using SET FORCEPLAN.
Use it but:
Example 2
If we use inequality predicates in all of them in any order like:
select*
from inc_ix_ex with(index = ix_include_e)
where col2<>2 and col3<> 4 and col1<> 1
and col1> 4
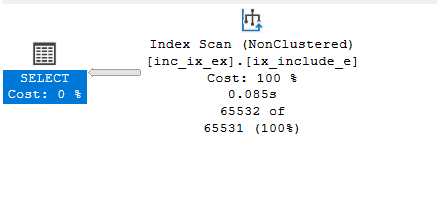
it still uses the clustered no need for RID lookups
so just like the composite in terms of SARGability just with fewer index pages
we can prove that by forcing the seek hint:
select*
from inc_ix_ex WITH (INDEX (ix_include_e) FORCESEEK)
where col2<>2 and col3<> 4 and col1<> 1
and col1 >4
And we would get the following:
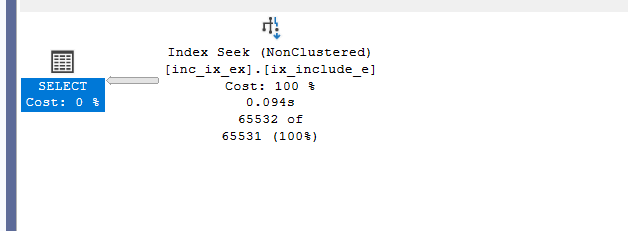
so it seeks in ranges, but it still seeks
for comparing performance hits between an index scan and the range scan in index seeks go to our blog( ways to read indexes )
However, there is a difference in predicates:
Difference in seeking between included and composite indexes
Now if we look at the properties of our previous seek:

you can see, it seeks on col1>4 operator first, then it sees in the output rows of the seek predicate if the predicate( the upper stuff, the other stuff in the where clause) if they fit that, then it outputs them
now if we set statistics i/o on
Now if we try another example like:
select*
from inc_ix_ex
where col1 = 1 and col2 = 2
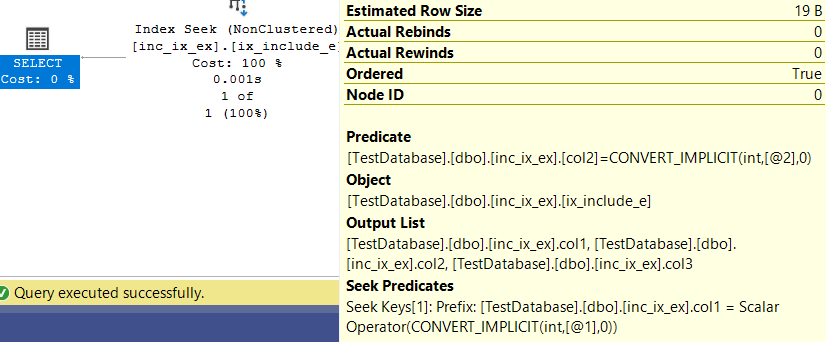
we can see the same problem
now if we set statistics i/o on:
go
set statistics io on;
go
select*
from inc_ix_ex
where col1 = 1 and col2 = 2
go
set statistics io off;
go
Table 'inc_ix_ex'. Scan count 1,
logical reads 2, physical reads 2,
page server reads 0, read-ahead reads 0,
Now let’s drop the index and create a composite one:
drop index ix_include_e on dbo.inc_ix_ex
Now let’s create a composite one:
create nonclustered index not_inc on dbo.inc_ix_ex(col1,col2,col3)
Then do the same select:
go
set statistics io on;
go
select*
from inc_ix_ex
where col1 = 1 and col2 = 2
and 1 = (select 1)
go
set statistics io off;
go
Table 'inc_ix_ex'. Scan count 1, logical reads 2, physical reads 0,
now here we might not notice the difference, so we are going to do another select
a bigger table
, but before that, we can look into the seek predicates: Now as you can see here it seeks on both keys right away unlike the included columns which had to compare the predicates after seeking on the first, which make them better for a single query
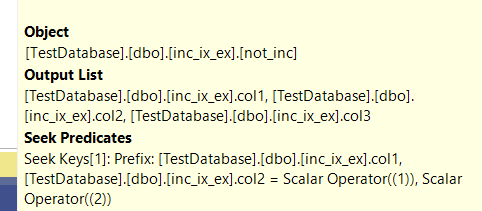
now as you can see here it seeks on both keys right away unlike the included columns which had to compare the predicates after seeking on the first, which make them better for a single query
now if we select like this:
go
set statistics io on;
go
select*
from inc_ix_ex with(index(not_inc) forceseek)
where col1 between 1 and 10000
and col2 = 2
and 1 = (select 1)
go
set statistics io off;
go
this is using the composite:
we get:
Table 'inc_ix_ex'. Scan count 1, logical reads 35, physical reads 0
the output was like:
drop index not_inc on inc_ix_ex
now recreate the including like:
create nonclustered index ix_include_e on inc_ix_ex(col1)
include(col2,col3)
now reselect:
go
set statistics io on;
go
select*
from inc_ix_ex with(index(ix_include_e) forceseek)
where col1 between 1 and 10000
and col2 = 2
and 1 = (select 1)
go
set statistics io off;
go
we get:
Table 'inc_ix_ex'. Scan count 1, logical reads 35,
now it is still the same, but the seek predicates differ in each, so if we had a value that had a col1 not selective enough it would have blown off the results since it can’t filter by col2, it just compares it afterward
Filtered indexes
now if we wanted to index a subset of column or columns related data, not the whole thing, we can use filtered indexes
for example:
create table fi_demo(
id int,
col1 varchar(50)
);
with
n1(c) as (select 0 union all select 0),
n2(c) as ( select 0 from n1 as f1 cross join n1 as f2 ),
n3( c) as ( select 0 from n2 as f1 cross join n2 as f2),
n4( c) as ( select 0 from n3 as f1 cross join n3 as f2) ,
n5( c) as ( select 0 from n4 as f1 cross join n4 as f2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into fi_demo(id,col1)
select id, replicate('s',20)
from ids
and you wanted an index on customers that has an id between 50 000 and 60 000 since they were the ones with most of the money(😄)
you can create a filtered index like:
create nonclustered index ix_filtered_id_col1 on fi_demo(id)
include(col1)
where id>=50000 and id<=60000
now if we select like:
select*
from fi_demo
where id = 50000
and 1 = (select 1)
we would get the following
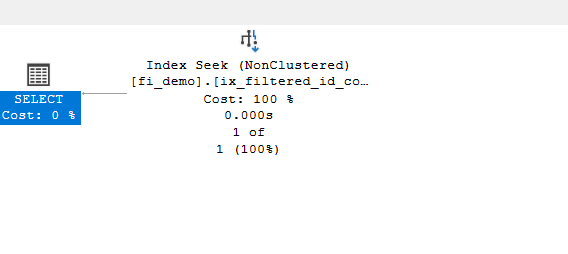
now if the query got parameterized by the engine like:
select*
from fi_demo
where id = 50000
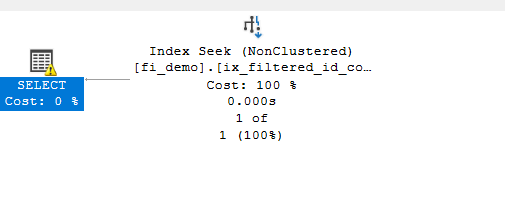
we would get the unmatched indexes warning

as you can see in the statement, we have @1 parameter since the plan is simply parameterized by the engine,it is not supposed to use the index, but if we use (USEPLAN) hint or compare both plans, or run dbccs that shows us the optimizer’s work, we did not see a difference in plans anywhere in the process except in the warning now we feel here that the engine uses the index, but it warns us that this plan could not be cached so we have to recompile it each time we use it
otherwise, we don’t have an explanation for this warning here other than this, you could check our tests on this in methods used in troubleshooting queries
now when the plan is not a candidate for simple parameterization, we don’t see the warning, like we saw before,
but if we do it manually:
declare @idv int
set @idv = 50000
select*
from fi_demo
where id= @idv
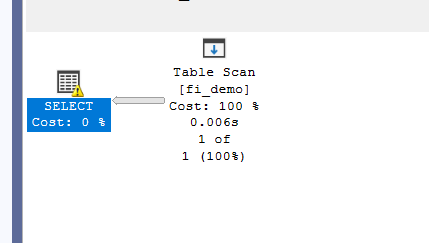
it had to go and scan and it shows us the same warning, but here, or in the traces we can see that it does not use the index seek, unlike in simple parameterization
why it does this?
let’s assume instead of 50000 we passed the value 2
would the index be used? the answer is no
so we can’t use this plan twice
so the optimizer chooses to ignore the index and see any other alternative, in this case it was the scan
how could we solve it? option(recompile):
declare @idv int
set @idv = 50000
select*
from fi_demo
where id= @idv
option(recompile)
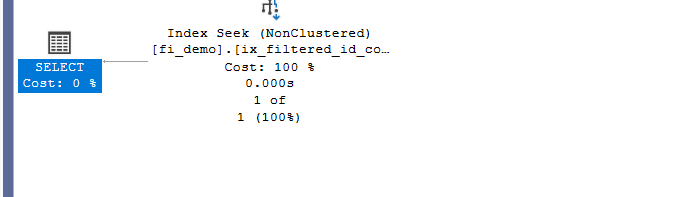
we can see the seek
now filtered statistics( we mentioned it in statistics blog)
does not get affected by updates
for example:
update fi_demo
set id = 2
where id >=50000 and id <=60000now if we query the previous query:
declare @idv int
set @idv = 50000
select*
from fi_demo
where id= @idv
option(recompile)
--- with out recompile
declare @idv int
set @idv = 50000
select*
from fi_demo
where id= @idv
option(recompile)
we would get the following:
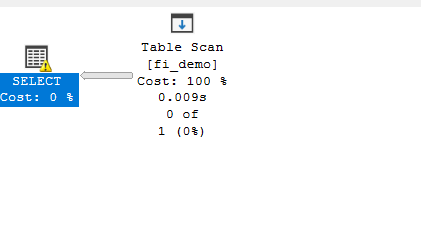
for the second
and
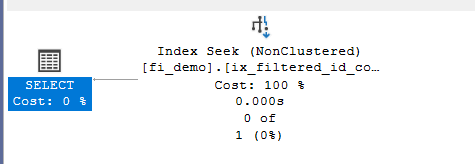
which means SQL server still thinks we have the rows since the index has not been updated
even though the stats are:
select name, stats_id, has_filter,auto_created,auto_drop
from sys.stats
where object_id=OBJECT_ID('dbo.fi_demo')
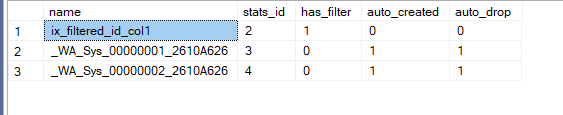
we can see that the stats has been dropped once in auto_drop
now if we dbcc show statistics for the index and the last auto stats:
dbcc show_statistics('dbo.fi_demo',ix_filtered_id_col1)
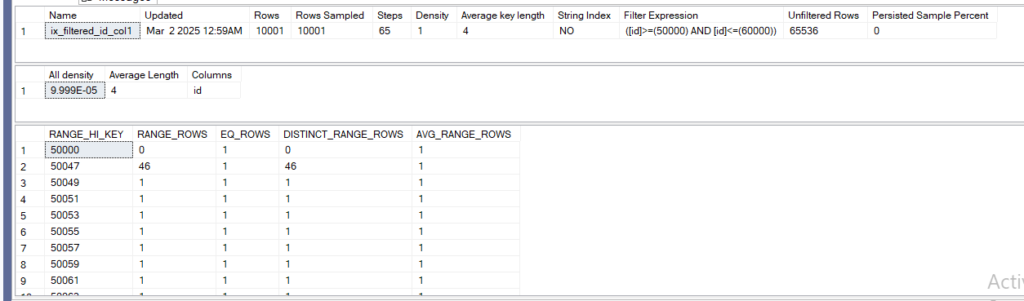
we can see it still thinks we have the rows, even though we met the update threshold
but in the new one:
dbcc show_statistics('dbo.fi_demo',_WA_Sys_00000001_2610A626)
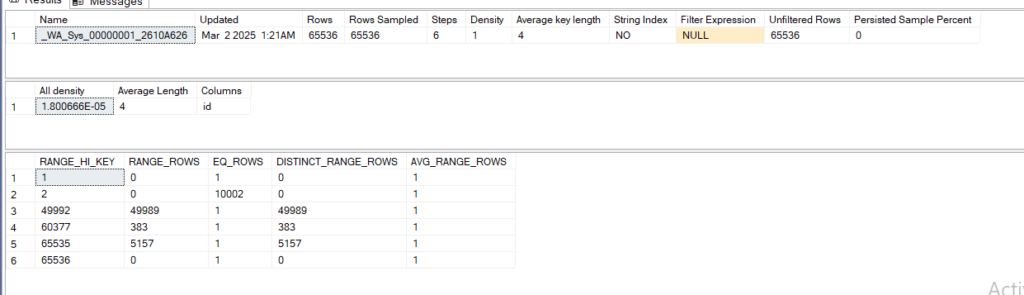
we can see it dropped our rows from distinct_range_rows
now we still have them, since they all are 2 as we can see from the first two ranges
but they have 2 = id not what the filtered shows, now if we update the filtered manually:
update statistics fi_demo ix_filtered_id_col1
the dbcc again
dbcc show_statistics('dbo.fi_demo',ix_filtered_id_col1)
We get:
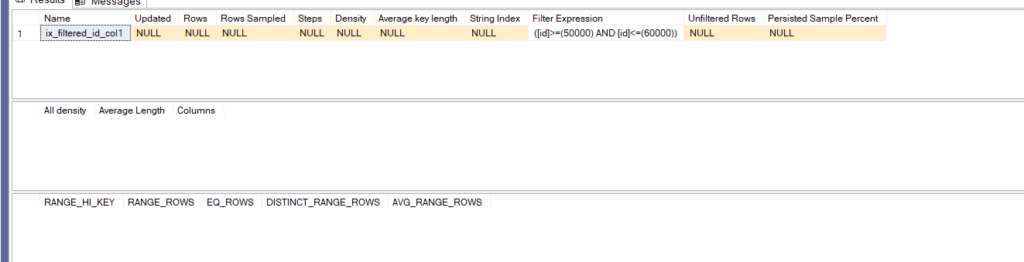
Now if we select with option recompile:
select id
from fi_demo
where id= 50000
option(recompile)
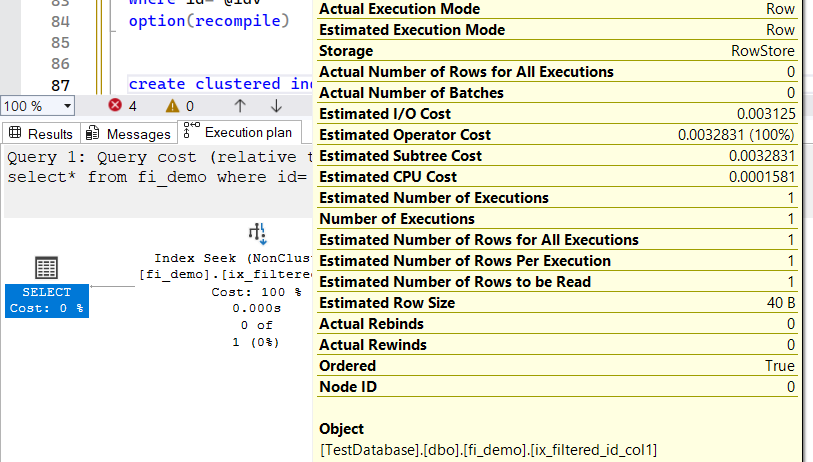
now it knows there is nothing in the index so it does not read it, but still shows us the index
now if we had a clustered index like:
create clustered index ix_id on fi_demo(col1)
And we did the select like:
declare @idv int
set @idv = 50000
select*
from fi_demo
where id= @idv
option(recompile)
It still favors the index seek, but noncosty, dummy operator, since the index has only one page, that has nothing in it,
so as you can see, we should manually update the stats on the filtered to get the desired result.
With that, we finish this blog, see you in the next one.