
In the previous blog, we talked about stream aggregate and how it gets implemented
Here, we are going to explore the other physical operator alternative to implement aggregations, We’ll start with the algorithm and keep going
Algorithm
As presented by Craig Freedman, the pseudocode is:
for each input row
begin
calculate hash value on group by column(s)
check for a matching row in the hash table
if matching row not found
insert a new row into the hash table
else
update the matching row with the input row
end
output all rows in the hash table
So, for example:
use AdventureWorks2022
go
select TransactionType,count(*)
from Production.TransactionHistoryArchive
group by TransactionType
go
We got:
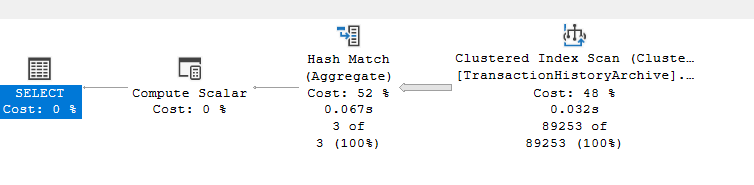
Here, the group by column, transaction type has 3 distinct values:
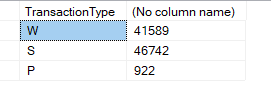
So it would generate 3 distinct hashkeys, then attach that to each row, and hash key is some calculation based on the row values,
So here we will have 3 different calculations, perfect, and it would give one of these for each row and compare them
If the keys match, then we are in the same group, then add that to the aggregation until you finish all the rows, so if the key is different, then match it to another one
So if it matches the same key,, and here for example,e it adds 1 to the count
Until you finish all the rows
So it goes for the first row, does it have W add it to the count, is it another value, then add it to the other hashkey, do we still have rows, yes, then we are not going to output any results until our operator finishes, once it is done we are going to give you the result, kind of like a carshop, if you need breaks, you have to wait until the end, unlike, let’s say KFC, there even if the first order is not finished, let’s say a family bucket, you can still get the other orders done, like a cheese burger, so one order does not block the other one, unlike the carshop who has one mechanic, one car at a time, so it would block the other customers, meaning it is a blocking operator
Unlike KFC = Stream aggregate = streaming = pipelined operator
Hash match properties:
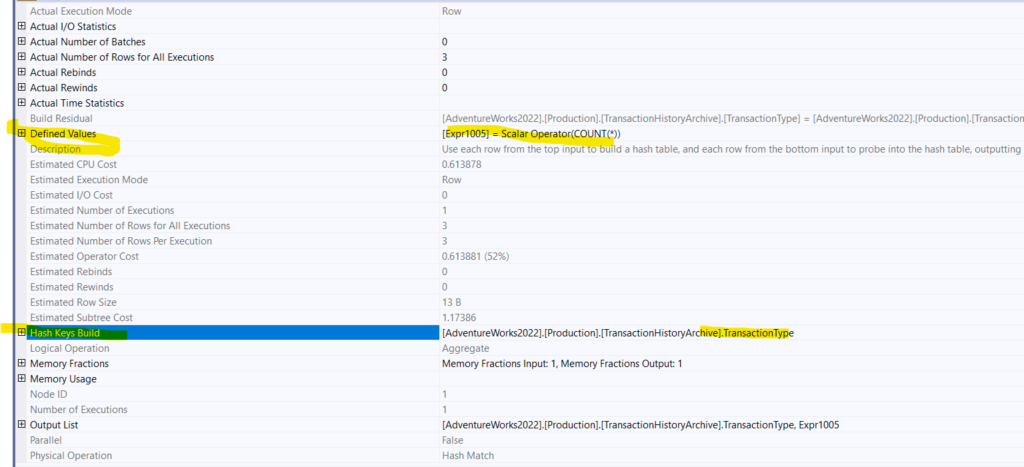
So, like we said before, it builds hash keys based on the group by columns TransactionType and count(). After that, it outputs them. The next operator is just a convert_implicit
Now, here there is no order by clause, implicit or explicit, since the Hash match algorithm does not guarantee any order, and that is why the optimizer might consider stream aggregates more efficient for such queries or it might introduce another sort operator after the hash aggregate.
Sorting after the Hash when we want an order by
For example:
use AdventureWorks2022
go
select TransactionType,count(*)
from Production.TransactionHistoryArchive
group by TransactionType
order by TransactionType
go
And the plan was like:
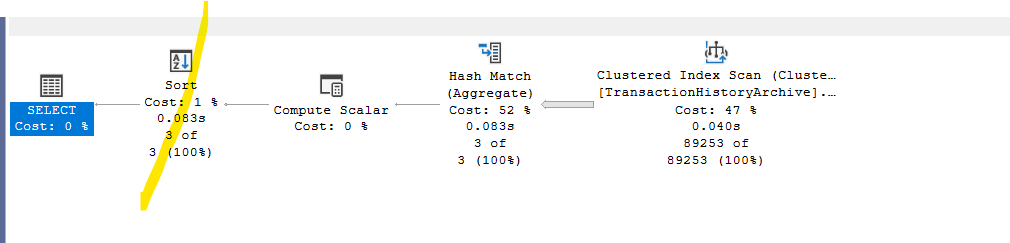
As you can see here, it is unlike the stream aggregate.
Also, our TransactionType has a lot of duplicates, in the sense that there are only 3 transaction types
Since it had to generate a hash key for each distinct value in the group by clause
Now 3 is nothing, but if we do the following:
use AdventureWorks2022
go
select ProductId,count(*)
from Production.TransactionHistoryArchive
group by ProductId
order by ProductId
go
We get:
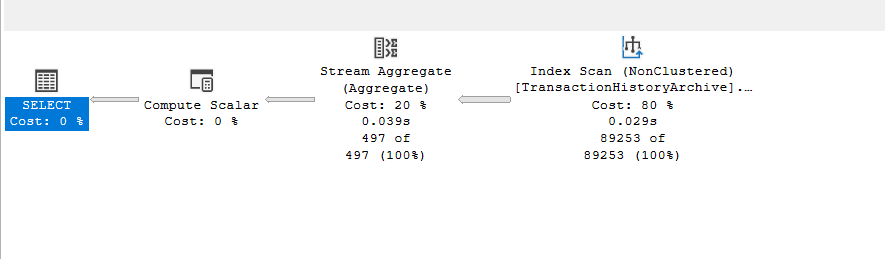
So, since there are a lot of ProductIds, it chose a stream aggregate, ‘cause generating a different hash key for each row is way more expensive than just aggregating them based on each ProductId
And there is an index that guarantees the order
So, if we disable the index, we would get a Hash aggregate
Now it sorts in memory, so it needs a lot of memory, and it might spill to tempdb, meaning
Hash aggregate writes its results while processing to a memory hash table, now if the memory grant is not as it is supposed to be, it has to process each bucket in memory first, so it process and spills whatever is not finished to tempdb, then it finishes the rows, since which one is finished first, it loads it to memory, outputs it, then it does the same for the other files in tempdb
Now we know that for each distinct group by row, it has to generate a different hash key
So the more duplicates, the easier it is to see a hash group, and that is why we grouped by TransactionType; there are only 3 distinct rows
So it chooses a hash aggregate if there is no index, a lot of rows, a lot of duplicates, and no need for an order
And we showed all that in the previous example
Simple select distinct
Or it could use it in a simple select distinct like:
select distinct(transactionType)
from production.transactionHistoryArchive
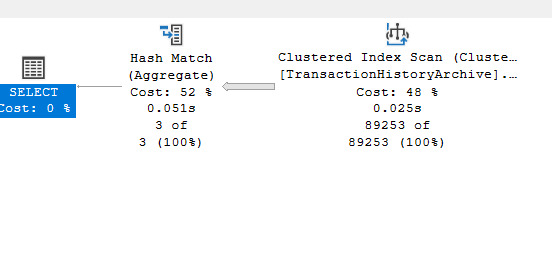
No order by, so basically we are saying: create a hash for each value, show me the distinct, and that is what it did
We know it would not make a difference if we specify the group by here:
select distinct(transactionType)
from production.transactionHistoryArchive
group by transactiontype
We get:
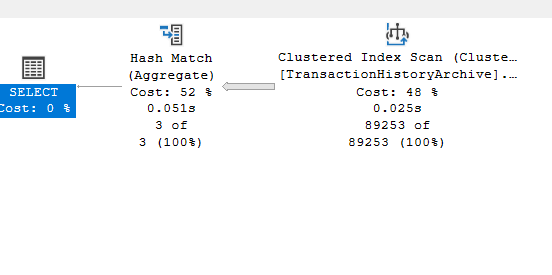
or
Hash with a stream when we want the order
It could be used like the others with distinct and an order by:
use AdventureWorks2022
go
select TransactionType,count(distinct(productid))
from Production.TransactionHistoryArchive
group by TransactionType
order by TransactionType
go
We get:
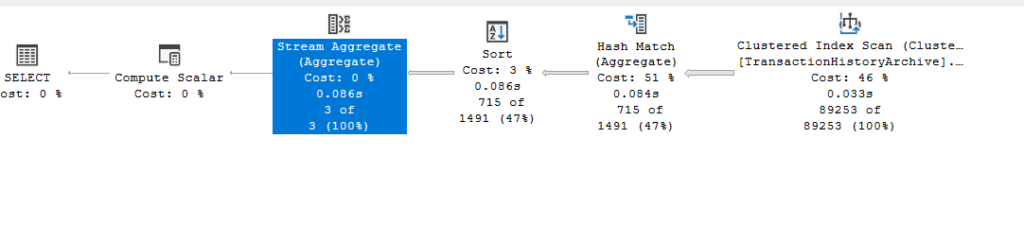
The textual is easier for the relevant parts:
|--Compute Scalar(DEFINE:([Expr1002]=CONVERT_IMPLICIT(int,[Expr1005],0)))
|--Stream Aggregate(GROUP BY:([AdventureWorks2022].[Production].[TransactionHistoryArchive].[TransactionType]) DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([AdventureWorks2022].[Production].[TransactionHistoryArchive].[TransactionType] ASC))
|--Hash Match(Aggregate, HASH:([AdventureWorks2022].[Production].[TransactionHistoryArchive].[ProductID], [AdventureWorks2022].[Production].[TransactionHistoryArchive].[TransactionType]), RESIDUAL:([AdventureWorks2022].[Production].[TransactionHistoryArchive].[ProductID] = [AdventureWorks2022].[Production].[TransactionHistoryArchive].[ProductID] AND [AdventureWorks2022].[Production].[TransactionHistoryArchive].[TransactionType] = [AdventureWorks2022].[Production].[TransactionHistoryArchive].[TransactionType]))
|--Clustered Index Scan(OBJECT:([AdventureWorks2022].[Production].[TransactionHistoryArchive].[PK_TransactionHistoryArchive_TransactionID]))
So first, it builds a hash key based on TransactionType and ProductId, meaning it creates groups based on both, meaning it groups them. After that, it sorts them on TransactionType, since we want the order by, and counts based on that, grouping by transaction type. Now, since hashkeys guarantees uniqueness, we did not need a distinct in the operators, so the stream aggregate just counts grouping by transaction type.
Hash only without order by
Or
If we did not specify an order by:
use AdventureWorks2022
go
select TransactionType,count(distinct(productid))
from Production.TransactionHistoryArchive
group by TransactionType
go
We get:
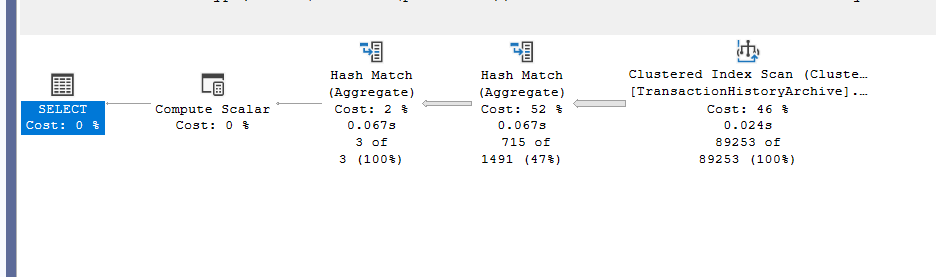
Here we don’t need the sort for the TransactionType, so it figured we would output the rows based on a new hash key created on TransactionType on the older output that is grouped by TransactionType, ProductId, no need for the stream aggregate
Or
Multiple distincts
It could be used for multiple distinct like:
use AdventureWorks2022
go
select TransactionType,
count(distinct(productid)) as product_count,
count(distinct(ReferenceOrderLineID)) as some_count
from Production.TransactionHistoryArchive
group by TransactionType
go
We get:
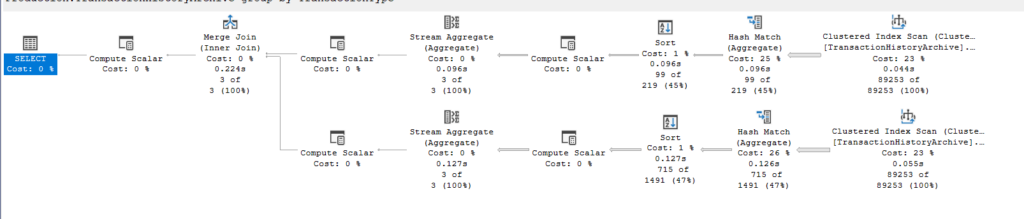
From the left:
The first two hash aggregates aggregate by building hashkeys on TransactionType and the other column, so no duplicates, no need for the distinct, since the hashing guarantees that
There are 3 compute scalars that relate to the hash join, we did not see these before in this series, more on them in the joins blog
After that, it counts grouping by transactiontype, convert_implicits, join, and output, the hash-join works as a glue between them
And the other compute scalars guarantee that we are joining based on TransactionType
And with this, we finish the blog