
In the previous two blogs, we introduced two arguments that could have a different way of aggregating ROLLUP, and CUBE.
Today, grouping sets can do both functions, and with some extra functionality:
Query
In the pivoted previous examples:
go
select SalesGuy,SalesDate,sum(sales)as total_sales
from dbo.SalesOrderW
group by rollup(SalesGuy,SalesDate)
---- for pivoting check out the previous blog
select SalesGuy,SalesDate,sum(sales)as total_sales
from dbo.SalesOrderW
group by cube (SalesGuy,SalesDate)
go
The results were:
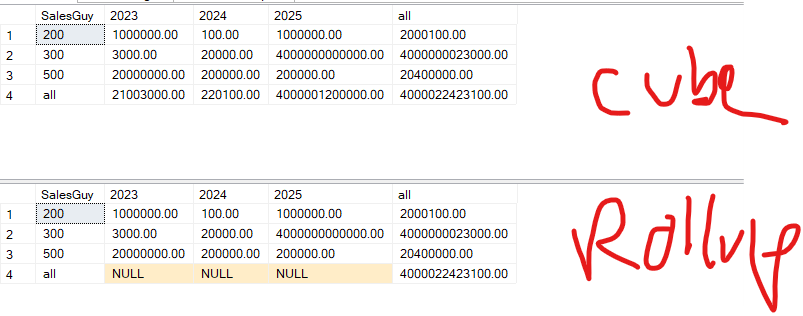
So, if we want to calculate the sum of all the years, we can use the sum
But, since we want to calculate the totals grouped by year and sales guy, we used rollup
But, we realized that we did not get the subtotals of SalesDate by rollup, so we added CUBE to calculate the totals by year,
Compared to rollup and cube, examples 1 and 2
Now, we have this alternative:
go
--- for cube
SELECT SalesGuy, SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS((SalesGuy, SalesDate), (SalesGuy),(SalesDate), ())
go
--- rollup
SELECT SalesGuy, SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS((SalesGuy, SalesDate), (SalesGuy),())
go
We get:
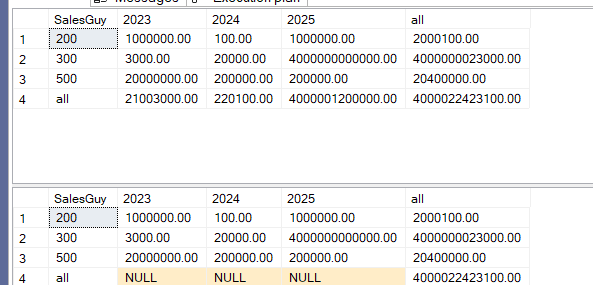
So what it did here:
For the following grouping sets, for example: (SalesGuy, SalesDate), calculate the sum grouped by them. If you do not find any set, or an empty set, then you get a sum like you had no group by, or like you are grouping by the whole table
In the first one, it was calculated by both, then it calculated the SalesGuy, then the SalesDate, and no grouping sets
In the second, it skipped the SalesDate since we did not specify it
Now, if we look at the grouping sets that have the rollup levels with no pivot:
go
--- rollup
SELECT SalesGuy, SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS((SalesGuy, SalesDate), (SalesGuy),())
go
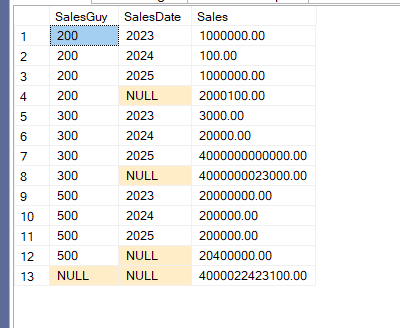
You can see, it looks exactly as the rollup, and for the execution plan:

We see the same execution plan in the second stream aggregate:

We can see, it got implemented as a rollup stream aggregate, and the sort is necessary since the stream aggregate can not function without it, and we get a stream aggregate for the first because the row count is low.
And if we look at the rules:
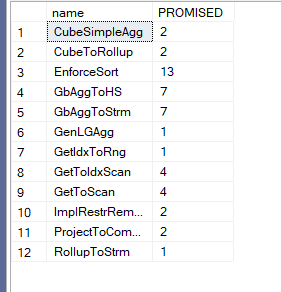
We can see, it got implemented as we asked for a rollup, and in the traces:
*** Converted Tree: ***
LogOp_Project QCOL: [AdventureWorks2022].[dbo].[SalesOrderW].SalesGuy QCOL: [AdventureWorks2022].[dbo].[SalesOrderW].SalesDate COL: Expr1003
LogOp_Cube OUT(QCOL: [AdventureWorks2022].[dbo].[SalesOrderW].SalesGuy,QCOL: [AdventureWorks2022].[dbo].[SalesOrderW].SalesDate,COL: Expr1003 ,) BY(QCOL: [AdventureWorks2022].[dbo].[SalesOrderW].SalesGuy,QCOL: [AdventureWorks2022].[dbo].[SalesOrderW].SalesDate,) GROUPING SETS(0x3 0x1 0x0 )
LogOp_Project
LogOp_Get TBL: dbo.SalesOrderW dbo.SalesOrderW TableID=3d491139 TableReferenceID=0 IsRow: COL: IsBaseRow1001
AncOp_PrjList
AncOp_PrjList
AncOp_PrjEl COL: Expr1003
ScaOp_AggFunc stopSum Transformed
ScaOp_Identifier QCOL: [AdventureWorks2022].[dbo].[SalesOrderW].Sales
AncOp_PrjList
*******************
It was treated logically the same, so even when it is parsed, maybe at an earlier level, that we can’t see without attaching a debugger, and even then maybe not, it recognized it is a grouping set, then it got converted to a cube, or maybe it was directly converted to a cube, and then to a rollup like we sawe in the rollup blog, either way, they are both logically and physically equivalent now.
And, the same goes for the cube, so we are going to omit its explanation here.
Benefits
As you have realized by now, this feature allows a lot more flexibility. Now we can choose different options, like whether we want the totals for all or not:
Example 3, excluding the total sum:
go
SELECT SalesGuy, SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS((SalesGuy, SalesDate), (SalesGuy),(SalesDate))
go
We get:
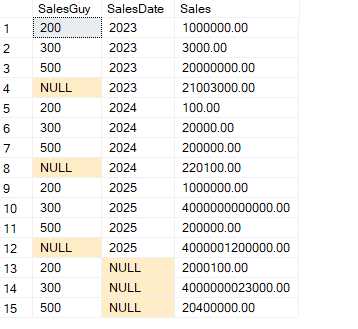
No two nulls at the end, that represent the fact, that we did not group by anything while doing this, our grouping function’s output was not 0, our grouping set here is not ().
Or we can just skip the intermediate results like:
Example 4, no intermediate results:
go
SELECT SalesGuy, SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS((SalesGuy, SalesDate),())
go
We get:
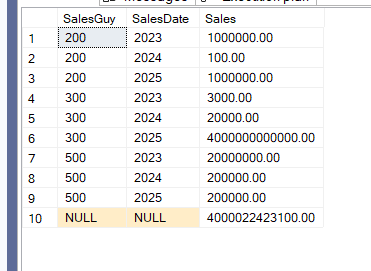
The execution plans in all of them are very similar, sometimes you don’t see some rollup levels like here:

Or we can compute uncorrelated dimensions:
Example 5, uncorelated dimensions:
go
SELECT SalesGuy, SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS((SalesGuy),(SalesDate))
go
We get:
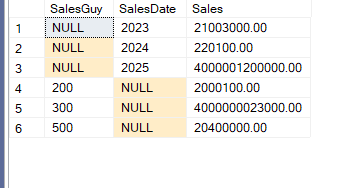
This is like contacting:
go
SELECT SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS((SalesDate))
union all
SELECT SalesGuy, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS((SalesGuy))
go
No rollup in here, and the execution plan:
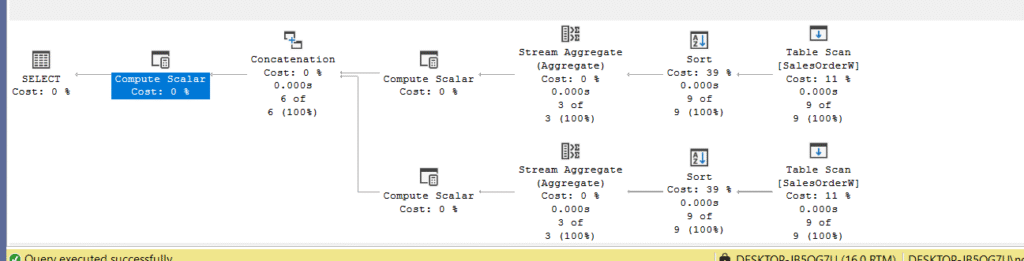
For the first query, the only difference here, since there is no null for the grouping in the output of each query, we don’t get the extra compute scalar that we highlighted here.
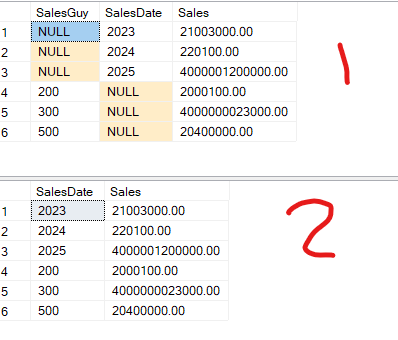
Some considerations
Now, when computing the values, the order does not matter, in which we mention the grouping sets we want, so:
go
go
SELECT SalesGuy, SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS((SalesGuy, SalesDate), (SalesGuy),(SalesDate),())
go
-- is the same as
SELECT SalesGuy, SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS((SalesGuy),(SalesDate),(),(SalesGuy, SalesDate))
go
We get:
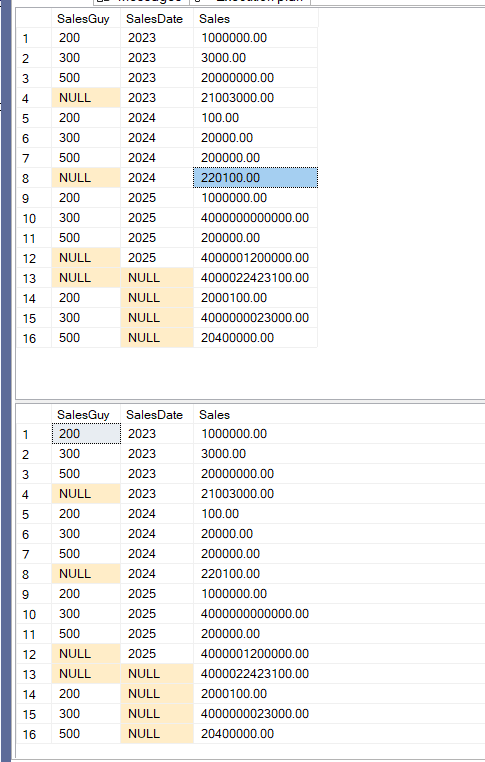
And the output is not guaranteed in order, so if we want it to be ordered by a certain column, we have to explicitly say so, like:
go
SELECT SalesGuy, SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS((SalesGuy, SalesDate), (SalesGuy),(SalesDate),())
ORDER BY SalesDate;
go
We get:
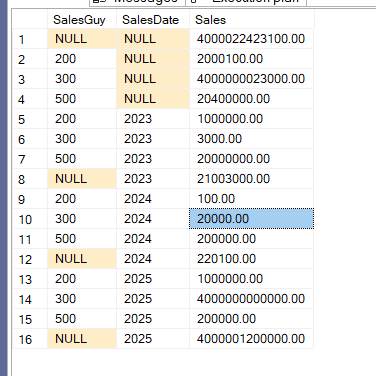
And we get an extra sort:
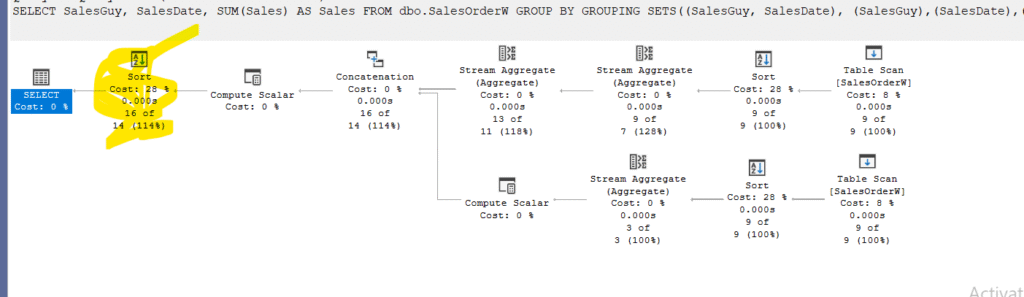
Also, even though we did not specify whether we want a rollup or not, we can do it simply like:
go
SELECT SalesGuy, SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS(rollup(SalesGuy, SalesDate))
go
Which is equivalent to a rollup, for a cube:
go
SELECT SalesGuy, SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS(rollup(SalesGuy, SalesDate))
go
Here we get the cube or the rollup we want, no difference in output between syntaxes
But if we do the following:
go
SELECT SalesGuy, SalesDate, SUM(Sales) AS Sales
FROM dbo.SalesOrderW
GROUP BY GROUPING SETS(cube(SalesGuy, SalesDate),(SalesGuy),(SalesDate),())
go
We get the results plus the stuff we asked for:
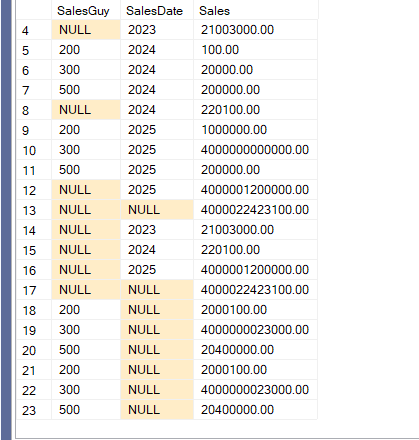
And the execution plan shows that too:
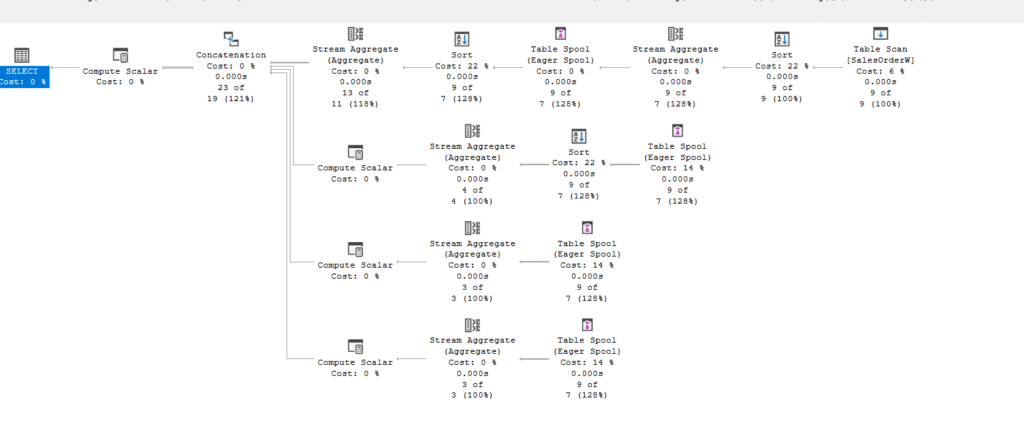
The spool here because it had to do the same aggregations multiple times, so it scanned them once and gave them back to us to reduce the amount of reads, like we said before
And with that, we finish this blog. See you in the next one.