
The Structure of composite
now sometimes we can define indexes with two keys in the definition
for example
create table comp_in(
col1 int not null,
col2 int not null)
create clustered index ix_com on comp_in(col1,col2)
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as(select row_number() over(order by (select null))from n5)
insert into comp_in(col1,col2)
select id , id*2 from ids
stats gets created with the index
Now if we check the stats:
dbcc show_statistics('dbo.comp_in',ix_com)
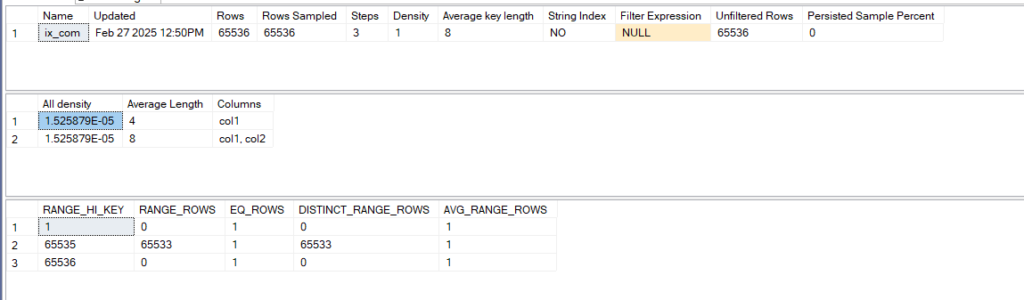
now as you can see here it created stats on the leftmost column
and then created combined stats for both, nothing for col2 only
and the histogram is only for the leftmost(for more details on this check out our statistics blog)
so we only have all_density for the second
now since we have auto_create_stats on that would not be a problem, but we should keep that in mind while querying, since SQL server would create them for us if we select col2 like
select col2
from comp_in
wher col2>1
select*
from sys.stats
where object_id = OBJECT_ID('dbo.comp_in')
We would see our column stats auto_created:

Now how does SQL server store this index
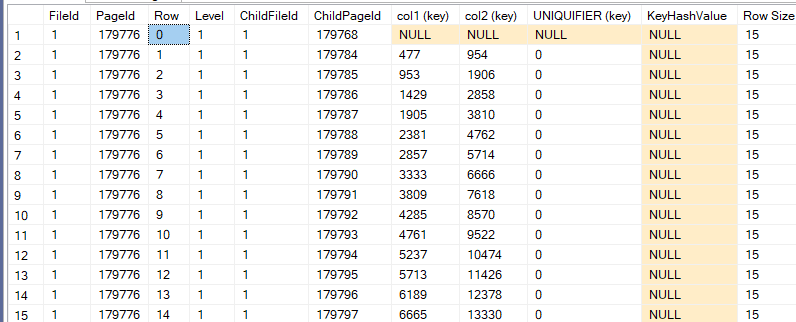
Let’s dbcc ind, dbcc page it:
dbcc ind('testdatabase','dbo.comp_in',-1)

Now let’s dbcc page the root page:
use TestDatabase
-- dbcc page the root
dbcc traceon(3604)
dbcc page('testdatabase',1,179768,3)
now here since one root page could fit all the index data, it did not need any intermediate levels
so we got the whole data pages type 1 as child pages with their ranges
now if we look at the page:
PAGE HEADER:
Page @0x0000013717DEA000
m_pageId = (1:179776) m_headerVersion = 1 m_type = 2
m_typeFlagBits = 0x0 m_level = 1 m_flagBits = 0x8000
m_objId (AllocUnitId.idObj) = 534 m_indexId (AllocUnitId.idInd) = 256 Metadata: AllocUnitId = 72057594072924160
Metadata: PartitionId = 72057594065453056 Metadata: IndexId = 1
Metadata: ObjectId = 286624064 m_prevPage = (0:0) m_nextPage = (0:0)
pminlen = 15 m_slotCnt = 138 m_freeCnt = 5750
m_freeData = 2166 m_reservedCnt = 0 m_lsn = (80:12736:335)
m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0
m_tornBits = 0 DB Frag ID = 1
Allocation Status
GAM (1:2) = ALLOCATED SGAM (1:3) = NOT ALLOCATED PFS (1:177936) = 0x40 ALLOCATED 0_PCT_FULL
DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED
Slot 0 Offset 0x60 Length 15
Record Type = INDEX_RECORD Record Attributes = Record Size = 15
Memory Dump @0x00000031D5DF6060
0000000000000000: 0670a978 f97f0000 6038be02 000100 .p©xù...`8¾....
Slot 1 Offset 0x6f Length 15
Record Type = INDEX_RECORD Record Attributes = Record Size = 15
Memory Dump @0x00000031D5DF606F
0000000000000000: 06dd0100 00ba0300 0048be02 000100 .Ý...º...H¾....
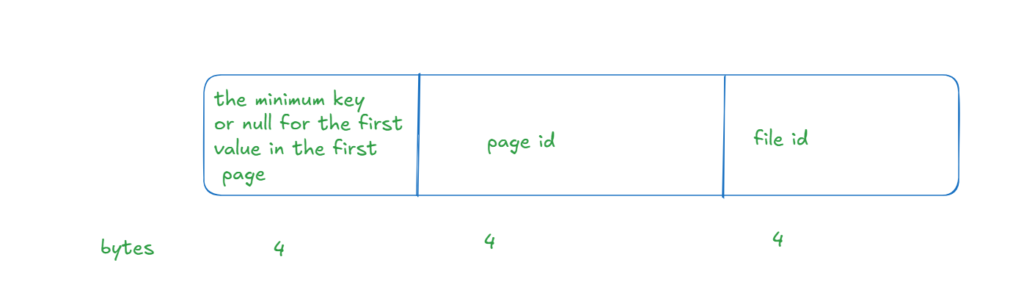
Now:
the last 4 bytes are file id in each
the first 8 bytes contain the minimal values for our range
in slot 0 they were nulls
in the second excluding 06 dd0100 00 = 477
and in the next 4 bytes ba0300 00 = 954
so we see it points out to the page and the columns
so it stored them in the index pages, in the primary key
so this is how composite indexes look like
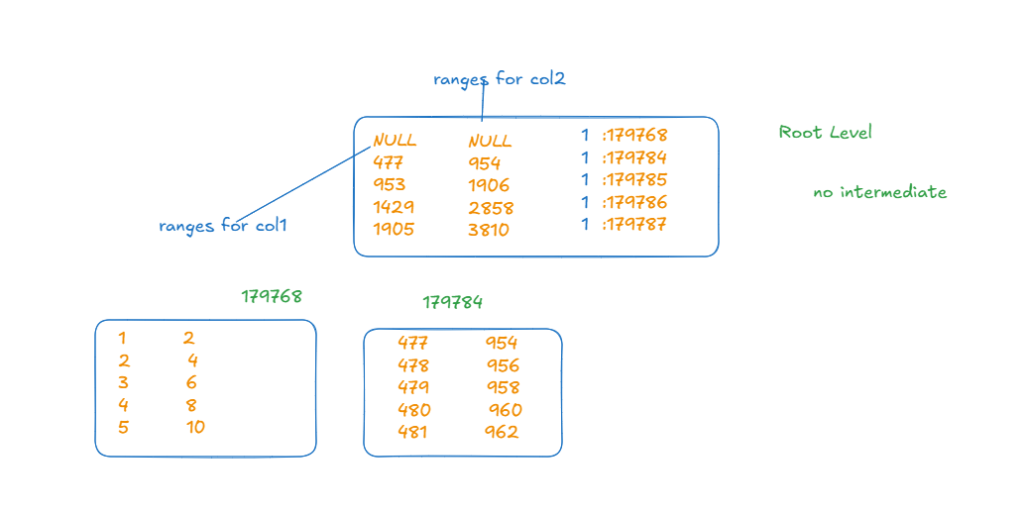
now the difference here is in the root page, it does not just store col1, it also stores col2 values
But what happens to SARGability in here?
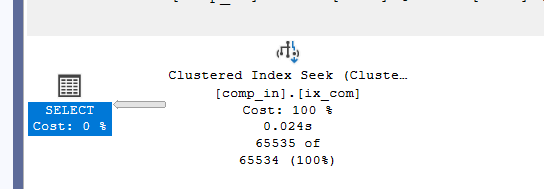
Example 1
if we select with both columns as predicates like:
select*
from comp_in
where col1>1
and
col2>2 we get a seek
Example 2
if we select with the first key only:
select*
from comp_in
where col1>1
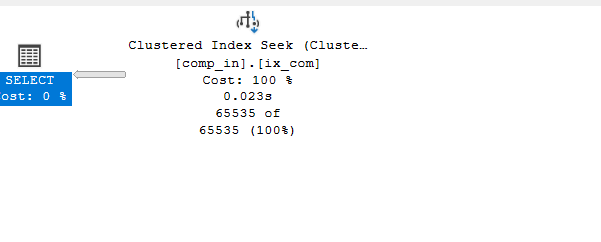
we get a seek
Example 3
if we select with only the second:
select*
from comp_in
where col2 = 6
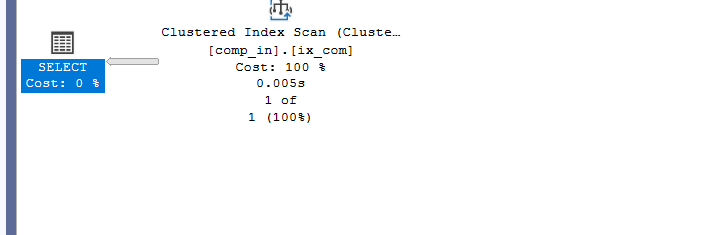
we get a scan since it is not the first key in the index and the index is structured from leftmost
and the leftmost has to be included in order to get one
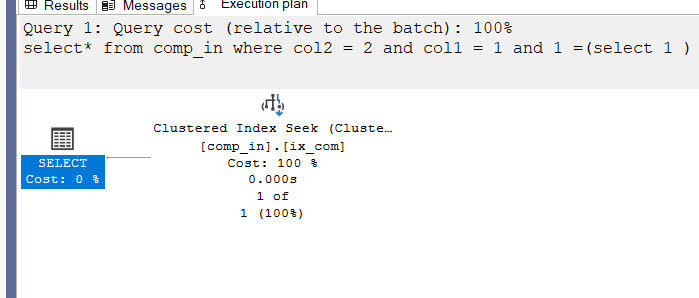
Example 4
if we select with both but reverse the keys like:
select*
from comp_in
where col2 = 2 and col1 = 1
and 1 =(select 1 )
it seeks
Example 5
if we used <> in the first key like:
select*
from comp_in
where col1 <> 1 and col2 =6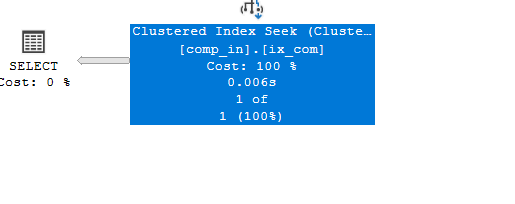
it seeks
Example 6
if we use <> in the second key
select*
from comp_in
where col1 = 1 and col2 <>6still seeks
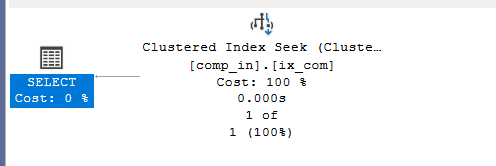
Example 7
if we use it in both like:
select*
from comp_in
where col1<>1 and col2<>2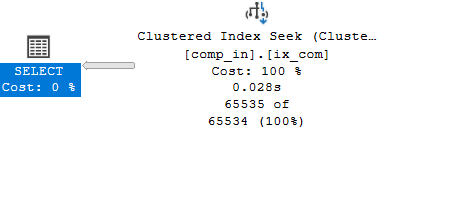
Or reverse it like
select*
from comp_in
where col2<>2 and col2<> 1 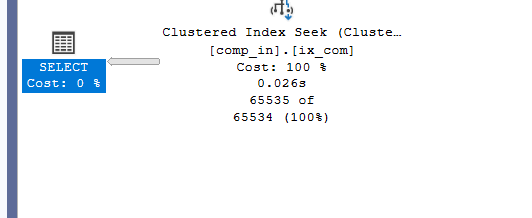
we still get a seek, so as long as we include both keys, the order does not matter
and inequality predicate is fine
but we can’t use the col2 alone
however, we can use the leftmost alone
the SARGability rules for other indexes apply here
NonClustered index
now clustered indexes store the actual data, pointing to each page
for example, if we look up a book, it is structured based on its pages
so the index would be the page number
and the data would be there when you go to the page
but nonclustered stores just a subset of it
but if the books had the terms mentioned in it in alphabetical order, and the pages that these terms stored in
so it has just the terms and points to the clustered index or the actual data through the clustering key
we would have the a nonclustered since it only stores a subset of columns or column
this would be way quicker if we just needed the terms, so we don’t have to read the entire page to get to our data
since we don’t know where the terms are stored, we have to read the entire book
but here we have them and a pointer to extras, meaning the data not included in our nonclustered, meaning the clustering key
now let’s try it:
create table nonc_tr(
id int,
col1 varchar(50),
constraint cl_p primary key clustered (id)
);
with
n1(c) as (select 0 union all select 0),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2 ),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into nonc_tr(id,col1)
select id ,replicate('w',3)
from ids
After that let’s create a nonclustered on col1 like:
create nonclustered index ix_col1 on nonc_tr(col1)
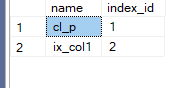
Okay now let’s get our index ids:
select name,index_id
from sys.indexes
where OBJECT_ID('dbo.nonc_tr')=object_id
So if we dbcc ind like this:
dbcc ind('testdatabase','dbo.nonc_tr',2)
We would get the following:

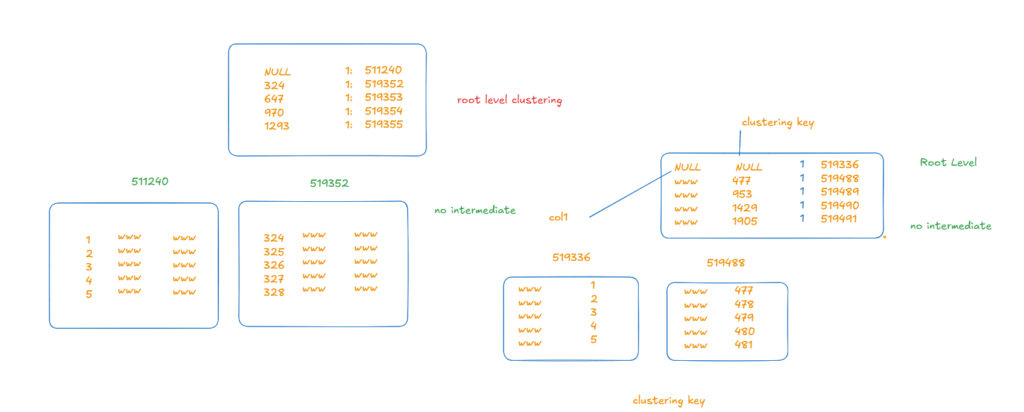
now as you can see we have 1 root page and no intermediate
and we have all index pages, no data pages (data page type = 2)
so it stores all its data in a separate place on index pages
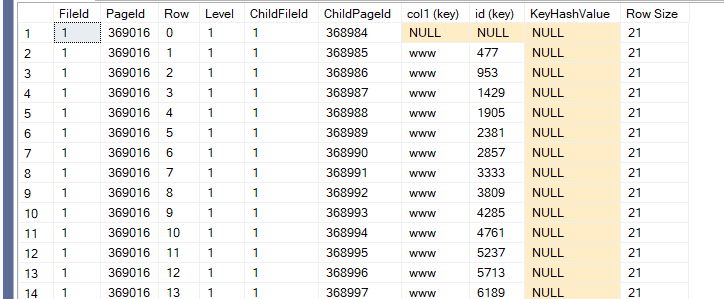
But the structure does not differ much, now if we dbcc page the root page like:
dbcc traceon(3604)
dbcc page('TestDatabase',1,369016,3)
we would get
and
Slot 0 Offset 0x60 Length 21
Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 21
Memory Dump @0x00000031E5776060
0000000000000000: 36010000 0058a105 00010002 00000100 15007777 6....X¡...........ww
0000000000000014: 77 w
Slot 1 Offset 0x75 Length 21
Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 21
Memory Dump @0x00000031E5776075
0000000000000000: 36dd0100 0059a105 00010002 00000100 15007777 6Ý...Y¡...........ww
0000000000000014: 77 w
77is w so the last 3 bytes are this, here it is presenting the range
pages 5A158 = 0058a105 = the first page
same 0059a105 = the second page
00000100 = file id
dd0100 00 = 477 the first in the second page clustering key the pointer to the actual data
00010002 I don’t know what it means
but as you can see it includes file id page id ranges and data
so if we construct it like that
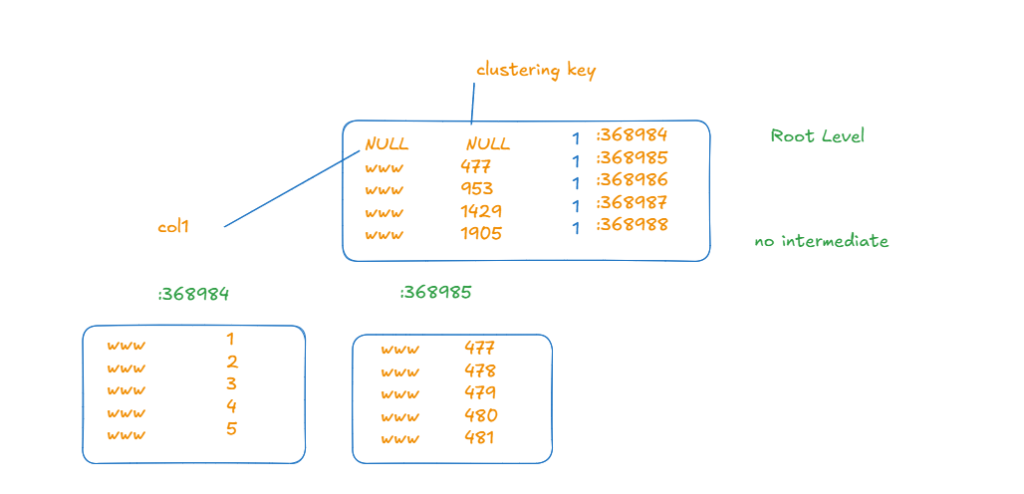
so now if we select like:
select col1
from nonc_tr
where col1 ='www'
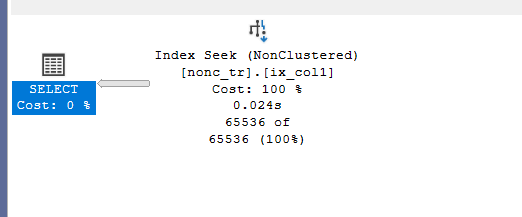
so we get a seek, and we are using all index pages
How does SQL server use nonclustered indexes
now since our nonclustered had all the rows that the clustered had we have to create a new or alter the old one, but since both would make no difference in terms of identifying pages, we opted to use the earlier
create table how_non_clus(
id int identinty(1,1),
co11 varchar(50),
col2 varchar(50)),
constraint cluss_p primary key clustered (id))
create nonclustered index ix_hnc on how_non_clus(col1)
with
n1(c) as (select 0 union all select 0),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2 ),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into how_non_clus(col1,col2)
select replicate('w',3),replicate('w',3)
from ids
Now in our case dbcc ind was like:
dbcc ind('testdatabase','how_non_clus',2)
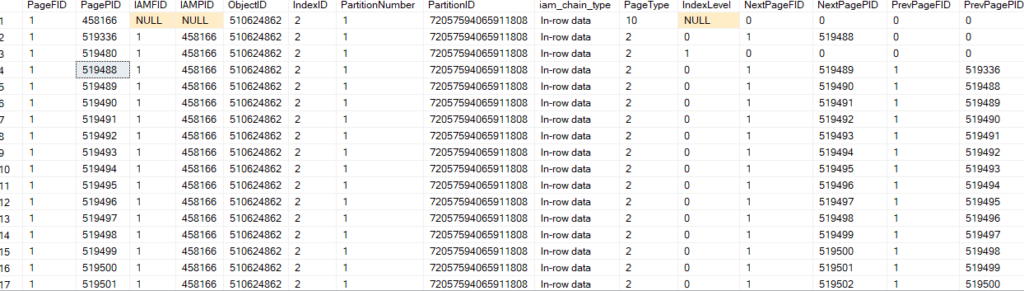
And dbcc page for the root level:
use testdatabase
dbcc traceon(3604)
dbcc page('TestDatabase',1,519480,3)
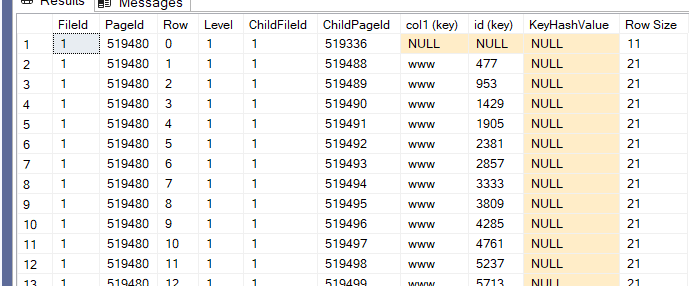
Not much of a difference except for page numbers:
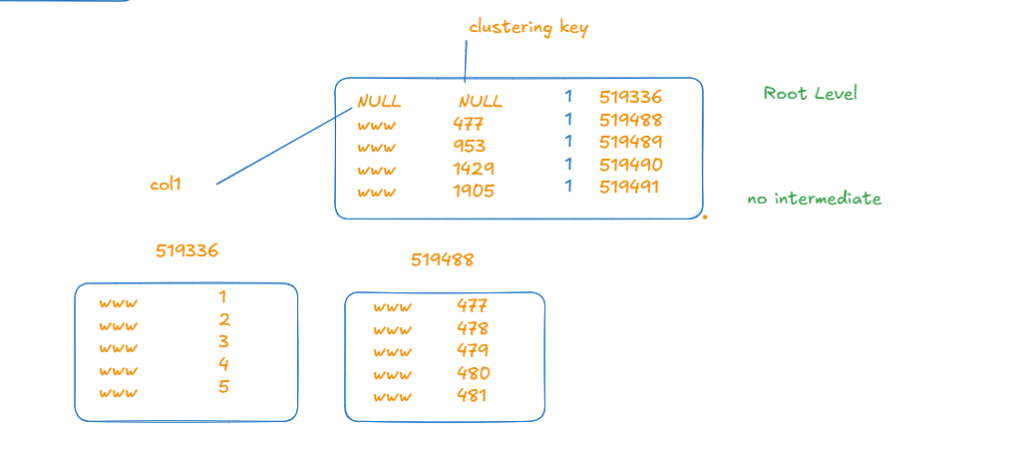
Now if we dbcc ind the clustering index like:
dbcc ind('testdatabase','how_non_clus',1)

Now dbcc page the clustering root:
use testdatabase
dbcc traceon(3604)
dbcc page('TestDatabase',1,519344,3)
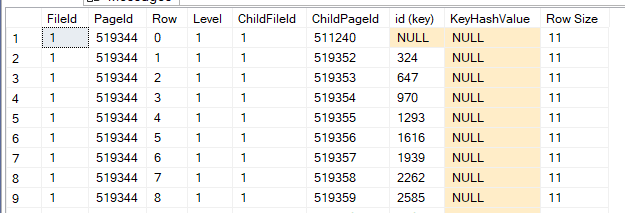
now as you can see the clustering root only includes the id as we discussed before
but if we dbcc page the first page like:
0000000000000000: 30000800 01000000 03000002 00140017 00777777 0................www
0000000000000014: 777777 www
Slot 0 Column 1 Offset 0x4 Length 4 Length (physical) 4
id = 1
Slot 0 Column 2 Offset 0x11 Length 3 Length (physical) 3
col1 = www
Slot 0 Column 3 Offset 0x14 Length 3 Length (physical) 3
col2 = www
we can see it stores everything, now if we want to construct the following
now if we insert like the following:
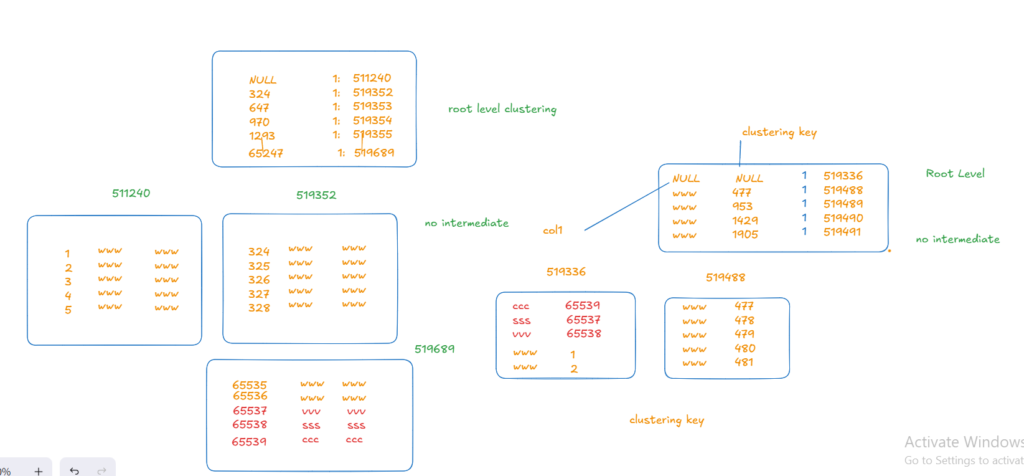
insert into how_non_clus(col1,col2) values('sss','sss') , ('vvv','vvv'),('ccc','ccc')
the new values were inserted at the first page

in nonclustered
and in the clustered the last page since the id is ever-increasing
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 23
Memory Dump @0x00000031DDBF7A85
0000000000000000: 30000800 02000100 03000002 00140017 00767676 0................vvv
0000000000000014: 767676 vvv
Slot 291 Column 1 Offset 0x4 Length 4 Length (physical) 4
id = 65538
Slot 291 Column 2 Offset 0x11 Length 3 Length (physical) 3
col1 = vvv
Slot 291 Column 3 Offset 0x14 Length 3 Length (physical) 3
col2 = vvv
Slot 291 Offset 0x0 Length 0 Length (physical) 0
KeyHashValue = (0a8a6362ce4f)
Slot 292 Offset 0x1a9c Length 23
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS
Record Size = 23
Memory Dump @0x00000031DDBF7A9C
0000000000000000: 30000800 03000100 03000002 00140017 00636363 0................ccc
0000000000000014: 636363 ccc
Slot 292 Column 1 Offset 0x4 Length 4 Length (physical) 4
id = 65539
Slot 292 Column 2 Offset 0x11 Length 3 Length (physical) 3
col1 = ccc
Slot 292 Column 3 Offset 0x14 Length 3 Length (physical) 3
col2 = ccc
Slot 292 Offset 0x0 Length 0 Length (physical) 0
KeyHashValue = (f3c608f52b43)
now as you can see it got inserted at the last page last slots
so we could construct the following
now if we select like:
select*
from how_non_clus
where col1 = 'sss'
We would get the following plan:
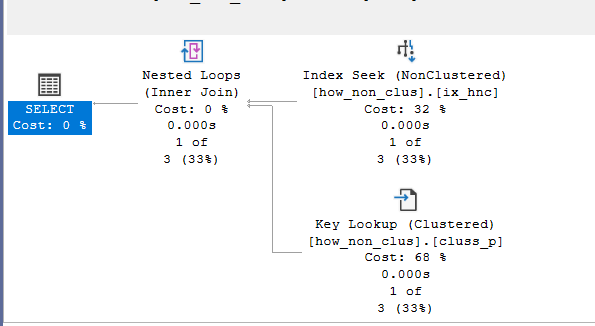
What is this operator?
SQL server wants the columns, but it can filter by the nonclustered so instead of scanning, it chose to seek the clustered for the fewer reads
first, it went to the root page
looked for the range of the values based on the nonclustering key='sss'
then it passed to the leaf level got the row
after that it looked in the nonclustered for col2, it could not find it
but it knows the clustering key for that row which is the id =65537
so it took that knowledge and went to the root of the clustering
found the page for 65537
then to the leaf page, and got the col2 data for us = ‘sss’
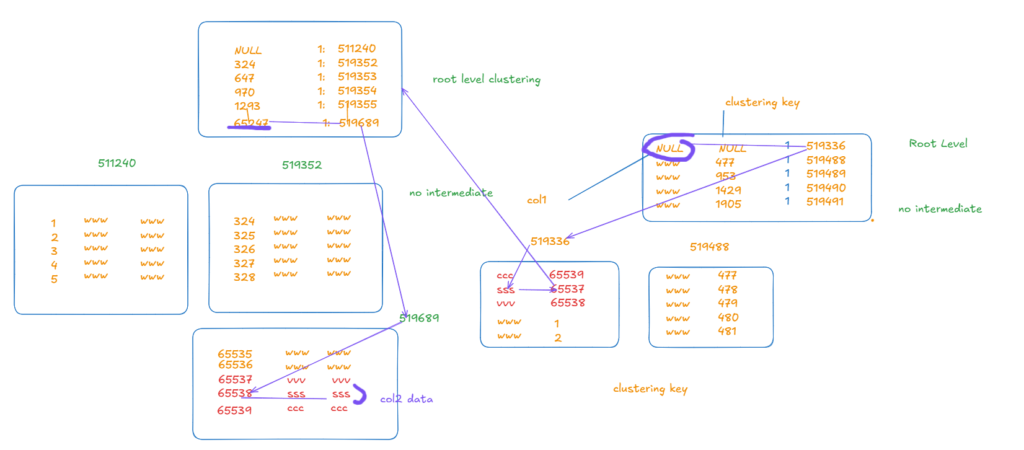
this is what you call a key lookup, a lookup for the clustering key in a non-heap or a table with a clustered index in it to find the missing rows that we can’t get from the nonclustered
so here it had to read the root of nonclustered, the leaf, then read the root and the leaf of the clustered, to get us one row, which is a lot of pages
secondly, key lookups introduce random i/o in contrast to scans which include sequential I/Os
which costs more
that is why SQL server tries not to choose nonclustered indexes whenever possible
for example, if we set statistics i/o on like:
go
use testdatabase
go
set statistics io on
go
select*
from how_non_clus
where col1 = 'sss'
go
select*
from how_non_clus
where col1 = 'www'
go
select*
from how_non_clus with(index = ix_hnc )
where col1 = 'www'
go
set statistics io off
The output was like:
Table 'how_non_clus'. Scan count 1, logical reads 4, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(1 row affected)
(65536 rows affected)
Table 'how_non_clus'. Scan count 1, logical reads 205, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(1 row affected)
(65536 rows affected)
Table 'how_non_clus'. Scan count 1, logical reads 135318, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(1 row affected)
Completion time: 2025-02-28T11:07:05.9770160+03:00
as you can see, in the first one it only needed one row, it got its 4 logical reads, not much, we are golden, this is why key-lookup is for
in the second it scanned
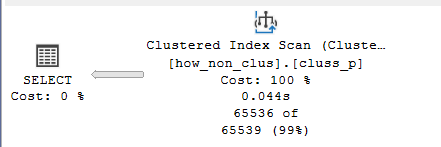
the clustered since it does not have to join and read every clustered with nonclustered
205 pages not bad for the whole table
now in the third where we forced the index to be used
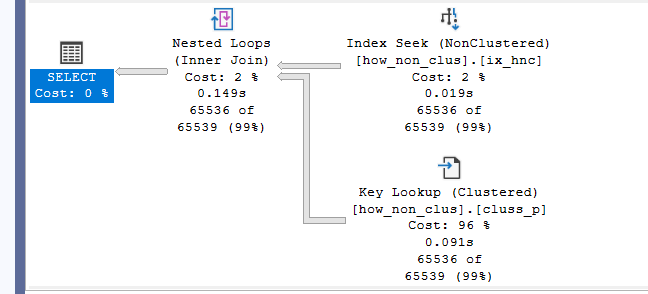
it had to read the whole table for each row (more on it in join operators)
135318
it is a lot
now if we had a heap, we would have another operator LIKE:
GO
CREATE TABLE RID_LOOKUP(
COL1 INT,
COL2 CHAR(10)
)
INSERT INTO RID_LOOKUP(COL1,COL2) VALUES(1,'S'),(2,'R')
CREATE NONCLUSTERED INDEX IX_RID_L ON RID_LOOKUP(COL2)
SELECT*
FROM RID_LOOKUP WITH(INDEX =IX_RID_L)
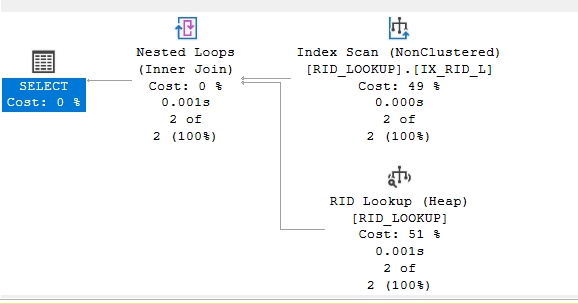
now here it goes directly to the pages, IAM scan for the whole table, until it reaches the row it needs
in key lookup, I have to go through the leaves
not typically leaves are cached in memory, and scans are more expensive, so going through a nonclustered or clustered is less expensive
and with that, we are done here see you in the next blog
[…] now instead of creating just one key for the clustered, we can use the second key as identity or sequence, thus guaranteeing uniqueness(for more on composite keys check out our blog) […]