
In the previous 3 blogs, we talked about the physical operators used in implementing logical joins.
Today, we are going to compare them.
Comparison Points
In handling size, for small datasets, nested loop join performs the best, while merge join falls in the middle, and hash join would be the best for larger inputs.
In the number of concurrent queries running, nested loop join does not require any memory, so we can have as many as we want. It is not a blocking operator; merge join would be suited if we have the data pre-sorted using indexes, and the join is a one-to-many join, and hash join would be best suited for BI since it requires a lot of memory, meaning less for the others. Still, since BI-type queries are only so many, we don’t have to worry about that.
The only blocking operator here is a hash join
Both hash and merge join support all kinds of logical joins, while nested loop falls lower here, or it requires too many rewrites that would lessen the quality of plan exploration.
But nested loop join can handle non-equijoins, since it is the fallback if there is no algorithm, while merge can only do that in an outer join, and hash requires the equijoins, no questions asked.
For memory consumption, Hash is the worst, while merge requires them for the sort, so if we have indexed columns, we are golden
Now, since a merge join has to compare the duplicates in a non-unique database, it might need to write them to tempdb, the same goes for a hash join that does not have enough memory and has to process the buckets in a worktable
While sorted input is not required by a nested or a hash join, they don’t preserve the order of the query, meaning if you want the data ordered, you need to ask for it; this is the play field for the merge, except if you want to preserve the order for only the inner input in a nested loop join.
Now, let’s run some demos:
Setup
use adventureworks2022
go
create table compare1 (
col1 int,
col2 int,
St char(100)
);
go
create table compare2 (
col1 int,
col2 int,
st char(100)
);
go
with
n1(c) as (select 0 union all select 0 ),
n2(c) as ( select 0 from n1 as t1 cross join n1 as t2),
n3(c) as ( select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
ids(id) as (select ROW_NUMBER() over (order by (select null)) from n4)
insert into compare1 (col1,col2)
select id,id
from ids;
go 4
with
n1(c) as (select 0 union all select 0 ),
n2(c) as ( select 0 from n1 as t1 cross join n1 as t2),
n3(c) as ( select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
ids(id) as (select ROW_NUMBER() over (order by (select null)) from n4)
insert into compare2 (col1,col2)
select id,id
from ids;
go 40
The first has 1000, the second has 10 000, and the third has 100 000.
Demos
select* from compare1 c1 inner join compare2 c2 on c1.col1 = c2.col1
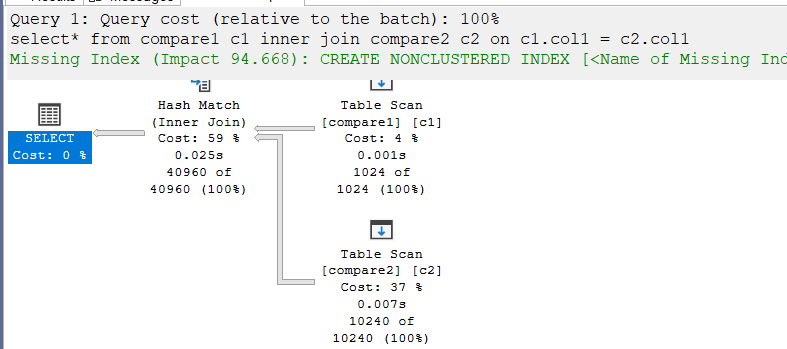
Nothing new here, hashing because we don’t have indexes.
But what if we added a top:
select top(10)* from compare1 c1 inner join compare2 c2 on c1.col1 = c2.col1
We get:
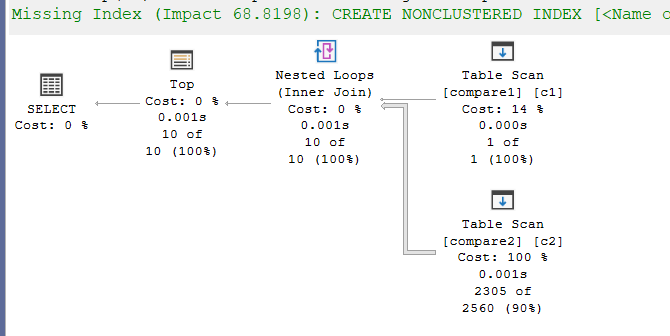
As you can see, it chose a nested loop, and we can see that it only had to reach to one top row from compare1, but we can see it had to scan a lot of rows to reach to 10 rows, that match, and are from the top, looked for the rows, and the top verified it.
But what if we want more than 10:
select top(50)* from compare1 c1 inner join compare2 c2 on c1.col1 = c2.col1
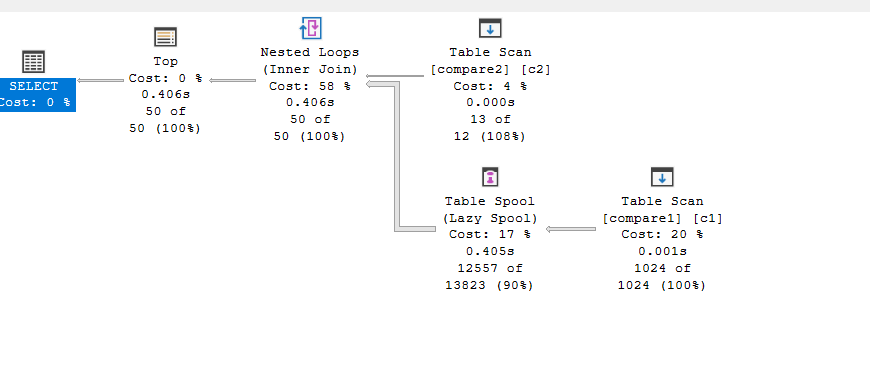
As you can see, it chose to store the entire table compare1, looked for the matching from compare2, and ran the thing like 12 times to get our row, so more rows means higher waits since it had to use a nested loop join
What if:
select top(100)* from compare1 c1 inner join compare2 c2 on c1.col1 = c2.col1
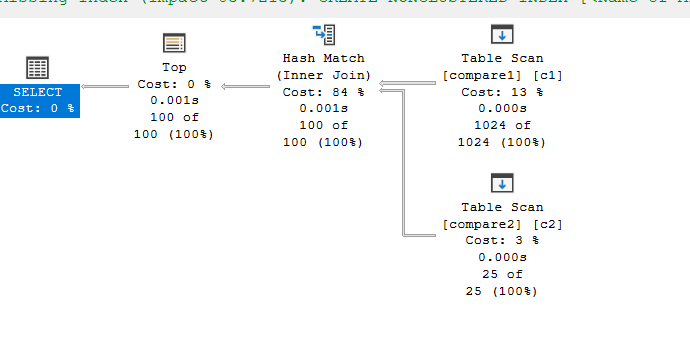
Here, it just realized, that instead of running and scanning a billion times, just join on the matching predicates, since you are going to get the top from compare1 no matter what if you scan it all, then after that look for the top in the join output itself, and you would get your results.
And if we love our order:
select top(100)* from compare1 c1 inner join compare2 c2 on c1.col1 = c2.col1 order by c1.col1
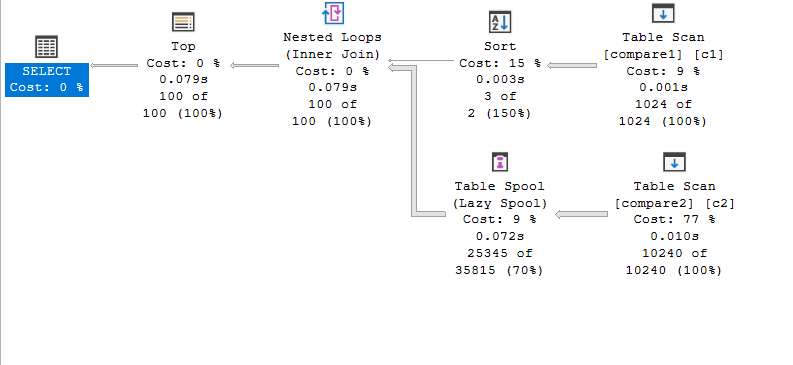
Since the output is sorted by outer input no matter what, we don’t need a sort after the nested loop, and since we can scan the table, it chose to do that, but it read the compare2 3 times to get our stuff done.
What if want it sorted by c2:
select top(1000)* from compare1 c1 inner join compare2 c2 on c1.col1 = c2.col1 order by c2.col1
Until like 500 as far as i remember, it decided to choose the previous plan, but once we hit the jackpot:
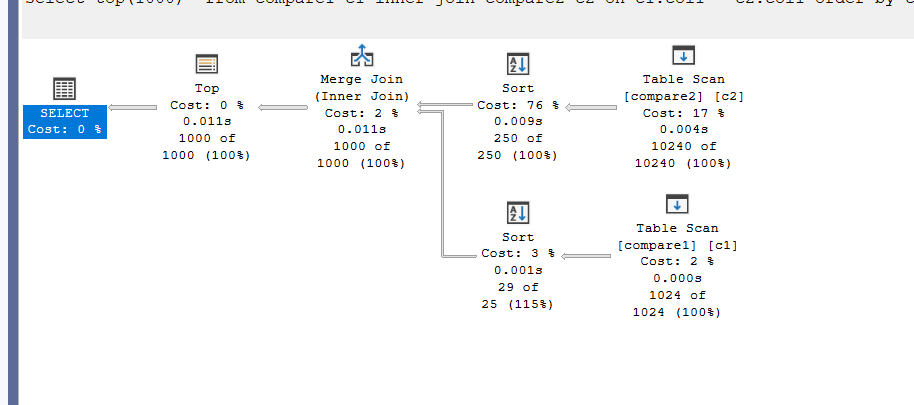
Since we need the sort no matter what, it decided to do it, then output it.
And with that, we finish this short comparison