
Hi everyone, today we are going to explain:
- the difference between a heap and a clustered index
- b-trees
- root level
- intermediate level
- double-linked pages
- and leaf-level pages in a clustered index
- dbcc page of all of them
- and the difference in select* performance(basic)
Intro
in the previous blog, we talked about heaps, and we said that the data has no order, and is inserted as easy as it could be.
SQL Server can not guarantee any order
but what if we wanted order in our data, what if we wanted to reach a row more quickly, and modify it more easily
what if we wanted a single row, or a range of rows, how could we do that?
Clustered indexes would physically reorder the pages for us
now we had regular data pages for our heaps, or type 1
here in the leaf level( more on it later) you would have the same type but in the root or intermediate levels(more on them later) we would have index pages or type 2
now, we said that it would physically re-write the whole thing, so instead of having the rows put randomly in our pages we would maintain their order in our pages, this would improve performance significantly since we know where to look
for example, if we had the following names:
adrian, amer, asher, axel , mehmet, khalid, george, and melissa
now in the clustered index if we stored it based on the first name we would have it in its alphabetical order, however in a heap there is no order so we would have something like the following
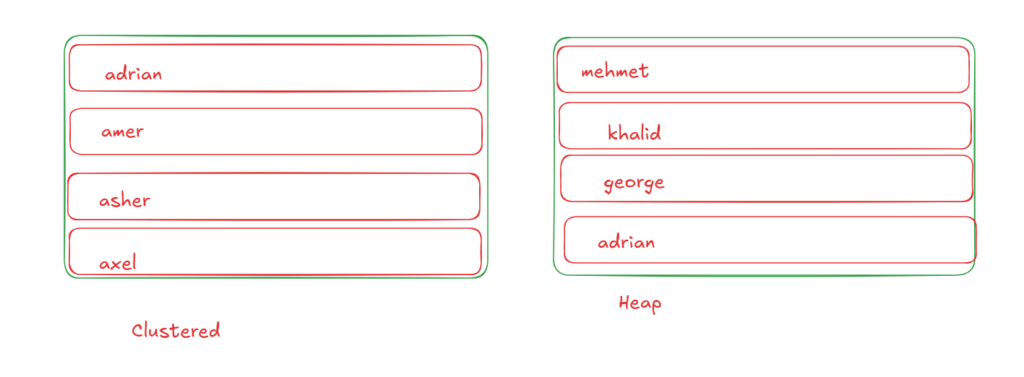
so we get the order, and if we wanted the row we would get it immediately
so let’s create a table with some rows id and col1:
create table dbo.heapVSclustered
(id int not null,
col1 char(200) null
);
with N1(C) AS(select 0 union all select 0)
,N2(C) AS (SELECT 0 FROM N1 AS T1 CROSS JOIN N1 AS T2)
,N3(C) AS (SELECT 0 FROM N2 AS T1 CROSS JOIN N2 AS T2)
,N4(C) AS (SELECT 0 FROM N3 AS T1 CROSS JOIN N3 AS T2)
,N5(C) AS (SELECT 0 FROM N4 AS T1 CROSS JOIN N4 AS T2)
,ids(id) as (select row_number() over(order by(select null)) from n5)
INSERT INTO dbo.heapVSclustered(id,col1)
select id,'sssss' from ids
Now if we select id between 100 and 5000 like:
select*
from dbo.heapVsclustered
where id >100
and id < 5000
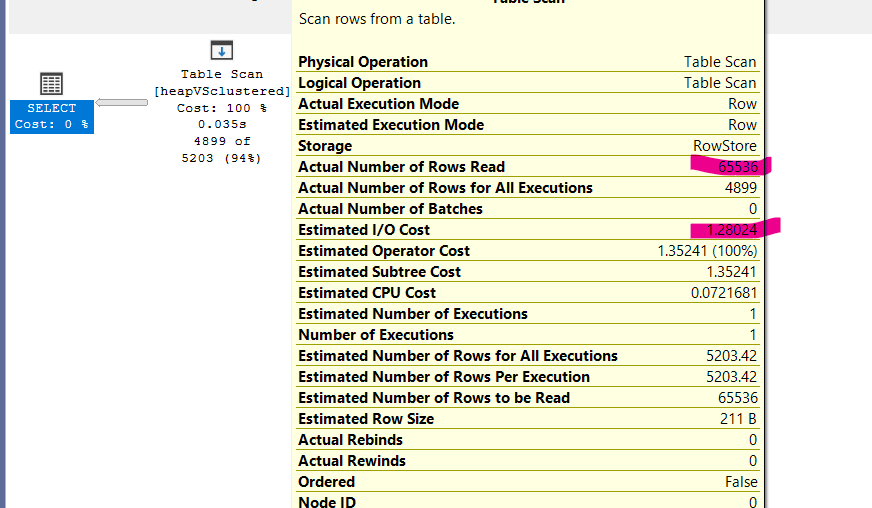
Now if we do the same but with a clustered index like:
create clustered index clus on dbo.heapVSclustered(id)
and do the same select
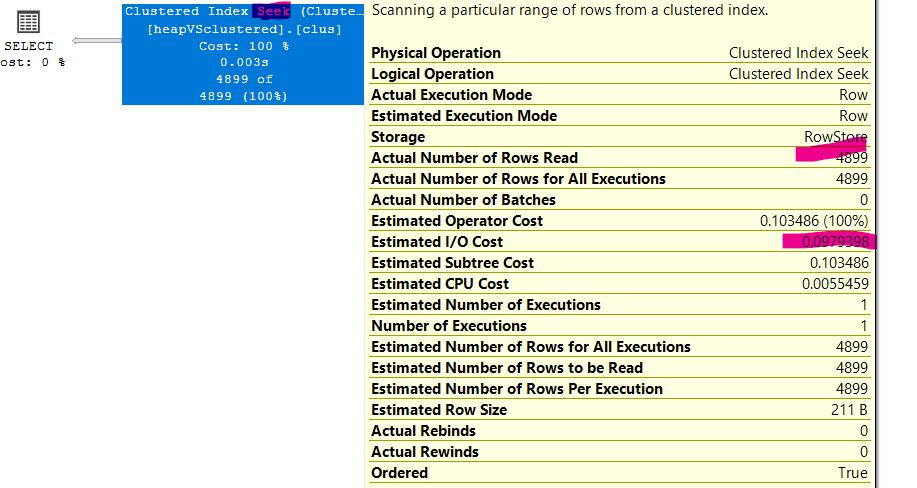
as you can see the cost has been cut down a lot and it only seeked the needed rows, it did not scan the whole table so it is way more efficient to select with a clustered
plus we got the rows ordered as shown at the end of the properties
in the table scan, it just went to the table read all the rows randomly, then put the ones we need
in the index seek, it just seeked the rows we need by scanning the range( in the execution plan itself)(more on in an upcoming blog)
and gave it back only the necessary rows and needed page, and how did it do that
Structure of the clustered index
now, instead of storing the rows randomly, we could store them based on one column or more, and with that structure, we could reach more quickly,
now how does it do that?
first, it creates another copy of the data
then it sorts them based on the value provided in the syntax, in our example, it was the id
then it links each page to the other one using double links so each page could point to the next and previous one
so we would have a doubly linked list, this list of pages, data pages, regular old-fashioned data pages, but sorted ones, is called the leaf-level pages
now how does SQL server go to the leaf we want, i mean Here we just ordered them?
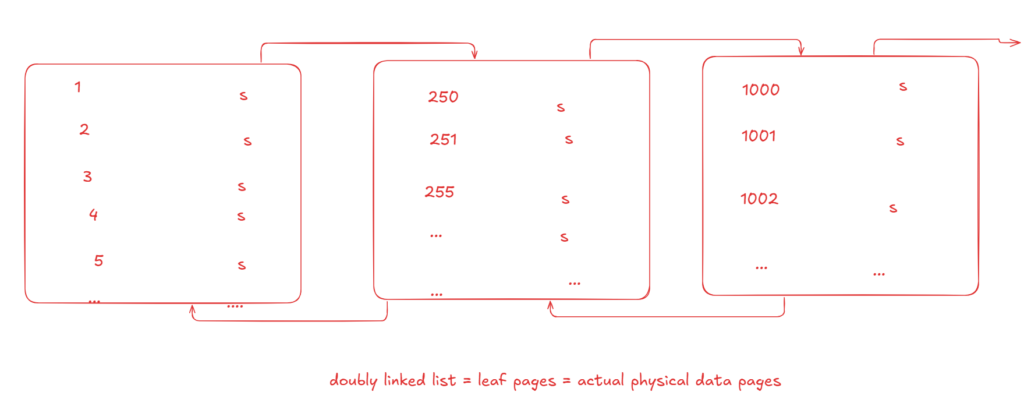
when we start having multiple pages like here
we can check with dbcc ind like:
dbcc ind('testdatabase','dbo.heapvsclustered',-1)

in our case, it has 1729

but we have a new page type = 2
which is the index page type
and its index level is = 2 or 1 unlike 0 which is the data level = leaf level pages
what does this mean?
it means we have pages other than the data pages
what do we call these two levels? root and intermediate levels
and what do we have there?
in intermediate levels, it stores one row per leaf-level page
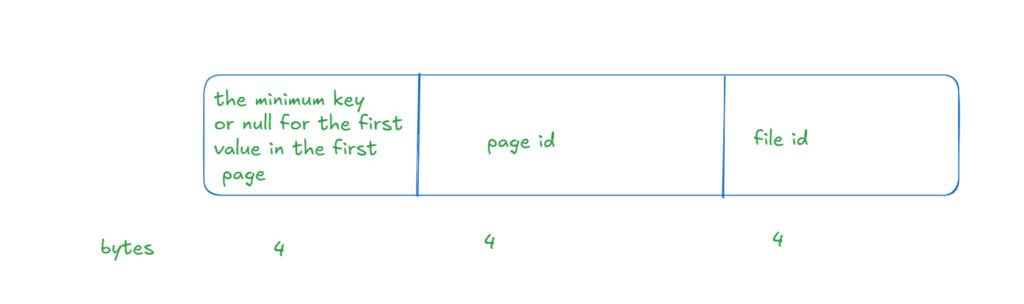
it stores two pieces of information the physical address and the lowest key or row value for the clustered index
the only exception is the first row in the first page
there it stores null instead of the actual value
with that, it does not need to update the non-leaf when we insert in there since it does not need to be updated
these pages are double-linked too
and it keeps on adding intermediate levels until one page fits the very top level
and that page is called the root page
root level page
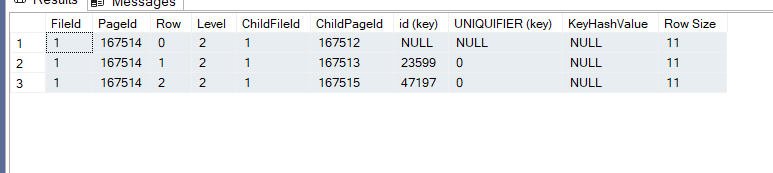
now if we dbcc page the root level like:(in our case)
-- dbcc page the root
dbcc traceon(3604)
dbcc page('testdatabase',1,167514,3)
we would get these
and
PAGE: (1:167514)
PAGE HEADER:
Page @0x0000020B647A8000
m_pageId = (1:167514) m_headerVersion = 1 m_type = 2
m_typeFlagBits = 0x0 m_level = 2 m_flagBits = 0x200
m_objId (AllocUnitId.idObj) = 284 m_indexId (AllocUnitId.idInd) = 256 Metadata: AllocUnitId = 72057594056540160
Metadata: PartitionId = 72057594049069056 Metadata: IndexId = 1
Metadata: ObjectId = 2069582411 m_prevPage = (0:0) m_nextPage = (0:0)
pminlen = 11 m_slotCnt = 3 m_freeCnt = 8057
m_freeData = 129 m_reservedCnt = 0 m_lsn = (67:81320:8)
m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0
m_tornBits = -2109005478 DB Frag ID = 1
Allocation Status
GAM (1:2) = ALLOCATED SGAM (1:3) = NOT ALLOCATED PFS (1:161760) = 0x40 ALLOCATED 0_PCT_FULL
DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED
Slot 0 Offset 0x60 Length 11
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x000000ACCB7F6060
0000000000000000: 06010000 00588e02 000100 .....X....
Slot 1 Offset 0x6b Length 11
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x000000ACCB7F606B
0000000000000000: 062f5c00 00598e02 000100 ./\\..Y....
Slot 2 Offset 0x76 Length 11
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x000000ACCB7F6076
0000000000000000: 065db800 005b8e02 000100 .]¸..[....
so it shows what this root points to in terms of intermediate-level pages, so we have 3 pages like we saw before in dbcc ind,
it shows us the range that this intermediate-level page covers
the last 4 bytes shows us the file id = 000100
the middle 4 bytes shows us the page id
slot 2 = 005b8e02 swapped 00028E5B= 167515
slot 1 = 00598e02 swapped 00028E59 = 167513
slot 0= 00588e02 swapped 00028E58 = 167512
and the first stores the lowest value in the range
for slot 2 = 065db800 swapped 0000B85D now I don’t know what 65 means but the others mean = 47197
for slot 1 = 062f5c00 swapped 5C2F and I don’t know what 006 means but this means = 23599
for slot 0 = 06010000 swapped equals null in the hex editors
so we know the following structure
and the page is like this
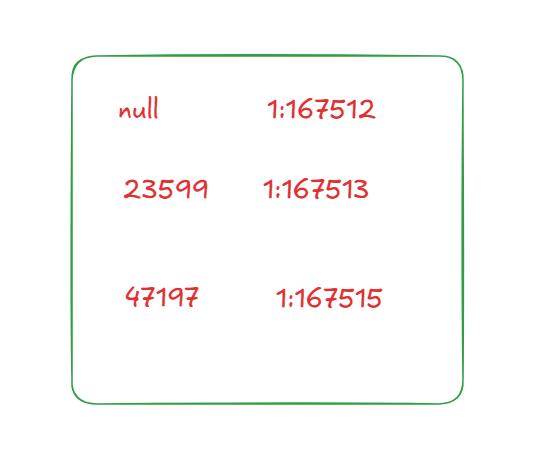
intermediate pages
now if we dbcc page one of all of them like:
--
dbcc traceon(3604)
dbcc page('testdatabase',1,167515,3)
--
dbcc traceon(3604)
dbcc page('testdatabase',1,167513,3)
--
dbcc traceon(3604)
dbcc page('testdatabase',1,167512,3)
We will get the following:
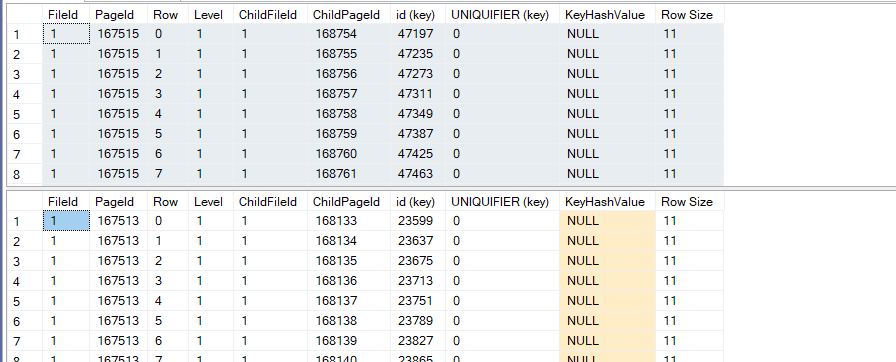
so each parent shows its children from data pages and the minimum value for each except for the first one
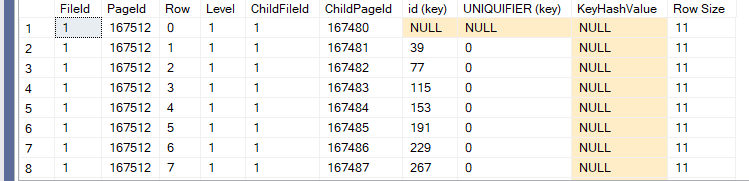
it is null
Now for the dbcc output:
PAGE HEADER:
Page @0x0000020B63D88000
m_pageId = (1:167512) m_headerVersion = 1 m_type = 2
m_typeFlagBits = 0x0 m_level = 1 m_flagBits = 0x200
m_objId (AllocUnitId.idObj) = 284 m_indexId (AllocUnitId.idInd) = 256 Metadata: AllocUnitId = 72057594056540160
Metadata: PartitionId = 72057594049069056 Metadata: IndexId = 1
Metadata: ObjectId = 2069582411 m_prevPage = (0:0) m_nextPage = (1:167513)
pminlen = 11 m_slotCnt = 621 m_freeCnt = 23
m_freeData = 6927 m_reservedCnt = 0 m_lsn = (67:62360:9)
m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0
m_tornBits = 142756749 DB Frag ID = 1
Allocation Status
GAM (1:2) = ALLOCATED SGAM (1:3) = NOT ALLOCATED PFS (1:161760) = 0x40 ALLOCATED 0_PCT_FULL
DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED
Slot 0 Offset 0x60 Length 11
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x000000ACD9676060
0000000000000000: 06010000 00388e02 000100 .....8....
Slot 1 Offset 0x6b Length 11
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x000000ACD967606B
0000000000000000: 06270000 00398e02 000100 .'...9....
Slot 2 Offset 0x76 Length 11
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x000000ACD9676076
0000000000000000: 064d0000 003a8e02 000100 .M...:....
Slot 3 Offset 0x81 Length 11
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x000000ACD9676081
0000000000000000: 06730000 003b8e02 000100 .s...;....
Slot 4 Offset 0x8c Length 11
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x000000ACD967608C
0000000000000000: 06990000 003c8e02 000100 .....<....
Slot 5 Offset 0x97 Length 11
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x000000ACD9676097
0000000000000000: 06bf0000 003d8e02 000100 .¿...=....
Slot 620 Offset 0x1b04 Length 11
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x000000ACD9677B04
0000000000000000: 06095c00 00c49002 000100 . \\..Ä.....
we can see the same here file at the end page number in the middle and the lowest key at the first and the page id in the middle
all the slots have the last 3 bytes set at one since they are all in the same file
the lowest key for:
- slot 0 = 06010000 = null like before
- slot 1 = 06270000 = 0027 with this 6 byte = 39
- slot 2= 064d0000 =004D = 77
- slot 3 = 06730000 = 0073 = 115
- slot 4 = 06990000 = 0099 = 153
- slot 5 = 06bf0000 = 00bf = 191
- slot 620 = 06095c00 = 5C09 = 23561
now if we check the other output for this page


you can see that it matches it exactly
and we would have the same for the page numbers in the middle except for the first it would be null
and we could find the next page and the previous page information in the page header
and dump style 1 does not have the double-linked bytes
and dump style 2 here too hard to decipher
so we feel that finding the double-linked list in text is enough for us here
Now we can develop this:
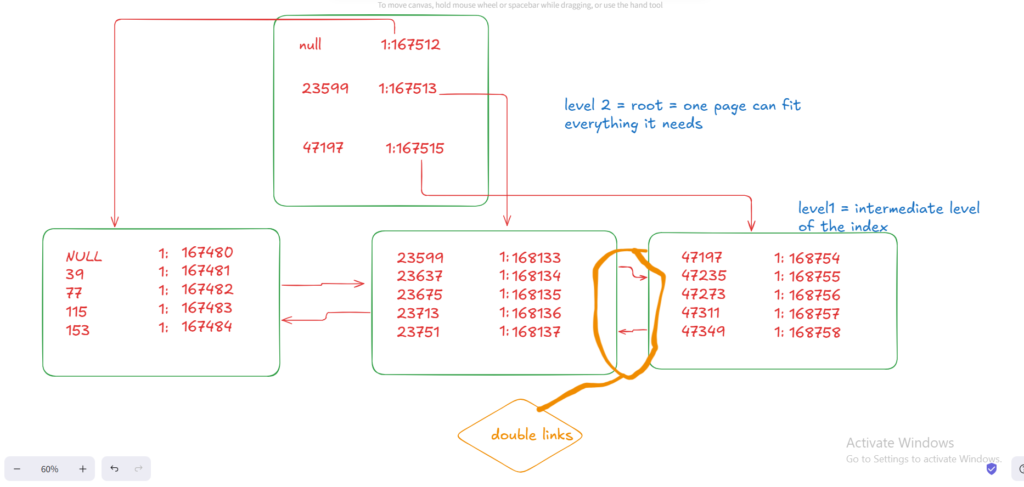
Now these are the index pages in the clustered, in a non-clustered index the whole thing would be index pages, but since the clustered is the physical data itself, the leaf level would be the actual stuff =data pages, but the other levels would be index pages= type 2
Leaf pages
now let’s explore the dbcc page output for our first data page:
use TestDatabase
dbcc traceon(3604)
dbcc page('testdatabase',1,167480,3)
Slot 0 Offset 0x60 Length 211
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP Record Size = 211
Memory Dump @0x000000ACCD5F6060
0000000000000000: 1000d000 01000000 73737373 73202020 20202020 ..Ð.....sssss
0000000000000014: 20202020 20202020 20202020 20202020 20202020
0000000000000028: 20202020 20202020 20202020 20202020 20202020
000000000000003C: 20202020 20202020 20202020 20202020 20202020
0000000000000050: 20202020 20202020 20202020 20202020 20202020
0000000000000064: 20202020 20202020 20202020 20202020 20202020
0000000000000078: 20202020 20202020 20202020 20202020 20202020
000000000000008C: 20202020 20202020 20202020 20202020 20202020
00000000000000A0: 20202020 20202020 20202020 20202020 20202020
00000000000000B4: 20202020 20202020 20202020 20202020 20202020
00000000000000C8: 20202020 20202020 030000 ...
Slot 0 Column 0 Offset 0x0 Length 4 Length (physical) 0
UNIQUIFIER = 0
Slot 0 Column 1 Offset 0x4 Length 4 Length (physical) 4
id = 1
Slot 0 Column 2 Offset 0x8 Length 200 Length (physical) 200
col1 = sssss
Slot 0 Offset 0x0 Length 0 Length (physical) 0
KeyHashValue = (de42f79bc795)
Slot 1 Offset 0x133 Length 211
key hash value helps in logging and holding the row in memory, sometimes it could get duplicated in extremely large tables(Paul Randal)
we obviously did not create column 2 but since we had fixed data length and we did not fill it all just 5 bytes sql server created a placeholder for it and filled it for us, now if we modify the col1 in id 1 like:
update dbo.heapvsclustered
set col1 = replicate('s',200)
where id = 1
--- dbcc page again
use TestDatabase
dbcc traceon(3604)
dbcc page('testdatabase',1,167480,3)
The output would be like:
Slot 0 Offset 0x60 Length 211
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP Record Size = 211
Memory Dump @0x000000ACCEDF6060
0000000000000000: 1000d000 01000000 73737373 73737373 73737373 ..Ð.....ssssssssssss
0000000000000014: 73737373 73737373 73737373 73737373 73737373 ssssssssssssssssssss
0000000000000028: 73737373 73737373 73737373 73737373 73737373 ssssssssssssssssssss
000000000000003C: 73737373 73737373 73737373 73737373 73737373 ssssssssssssssssssss
0000000000000050: 73737373 73737373 73737373 73737373 73737373 ssssssssssssssssssss
0000000000000064: 73737373 73737373 73737373 73737373 73737373 ssssssssssssssssssss
0000000000000078: 73737373 73737373 73737373 73737373 73737373 ssssssssssssssssssss
000000000000008C: 73737373 73737373 73737373 73737373 73737373 ssssssssssssssssssss
00000000000000A0: 73737373 73737373 73737373 73737373 73737373 ssssssssssssssssssss
00000000000000B4: 73737373 73737373 73737373 73737373 73737373 ssssssssssssssssssss
00000000000000C8: 73737373 73737373 030000 ssssssss...
Slot 0 Column 0 Offset 0x0 Length 4 Length (physical) 0
UNIQUIFIER = 0
Slot 0 Column 1 Offset 0x4 Length 4 Length (physical) 4
id = 1
Slot 0 Column 2 Offset 0x8 Length 200 Length (physical) 200
so it is ghosted now, not there, and we only have 2 columns id and col1
now it is the regular row:(the first output would be explained):

status bits a = 10 = 00010000= it has a null bitmap
status bits b = 00 = ghosted
fsize = d000 =208 = out data row size
fdata first column= 01000000= 1 = id
fdata second column =73737373=col1
then we have the placeholder with nothing in it
ncol = 0300 = 3 columns one for the placeholder and 2 for ours it was still 3 in our second output
then we have the nullbits = 00 = we don’t have any nulls in both outputs
now we can construct this
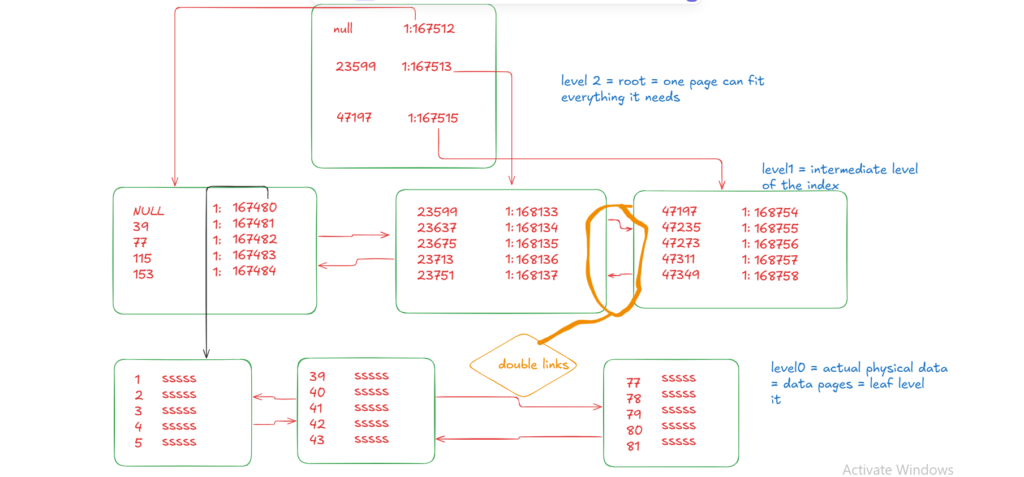
And with this, we introduced the difference between a heap and a clustered index, and how each is designed, see in the next blog