
Today, we will explore how the execution engine deals with a subquery that returns one value = a scalar subquery per row, row-by-row execution, and how an assert operator would appear.
Query
The setup:
go
create table fiirst (
col1 int,
col2 int
);
create table seecond(
col1 int,
col2 int
);
with
n1(c) as (select 0 union all select 0 ),
n2(c) as ( select 0 from n1 as t1 cross join n1 as t2),
n3(c) as ( select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
ids(id) as (select ROW_NUMBER() over (order by (select null)) from n4)
insert into fiirst(col1,col2)
select id,id
from ids;
with
n1(c) as (select 0 union all select 0 ),
n2(c) as ( select 0 from n1 as t1 cross join n1 as t2),
n3(c) as ( select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
ids(id) as (select ROW_NUMBER() over (order by (select null)) from n4)
insert into seecond(col1,col2)
select id,id
from ids;
select *
from fiirst
where fiirst.col1 > (
select min(seecond.col1)
from seecond
where seecond.col2 < fiirst.col2
);
--- or
select f.*
from fiirst as f
cross apply (
select min(s.col1) as mincol1
from seecond as s
where s.col2 < f.col2
) as t
where f.col1 > t.mincol1;
Now, if we do this:
We get:
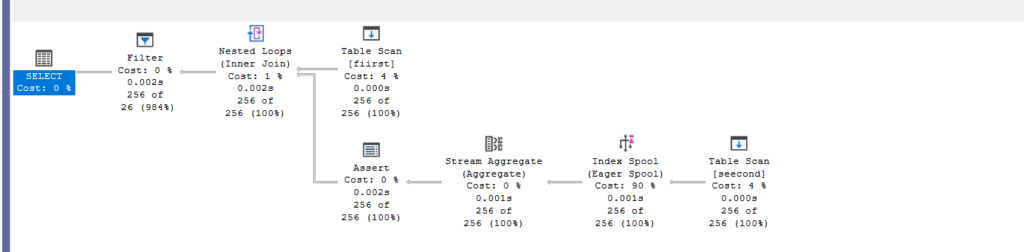
Index spool and a filter operator
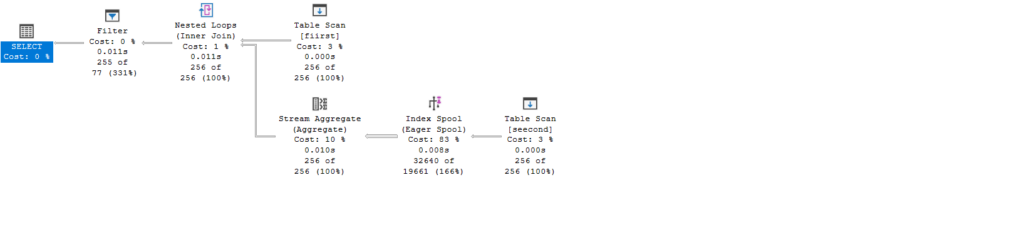
So, here we have multiple things:
- First, we are joining with an inequality predicate, so we have no choice but to join with a nested loop join, why do we have to join?
- SQL Server un-nests nested queries by joining them; different query optimizers do different things
- Secondly, we have to filter the rows for the aggregate functions, so we know that the where clause in the subquery is satisfied, which is seecond.col2<fiirst.col2 so where do we do that
- In the spool, or more specifically, the index spool:
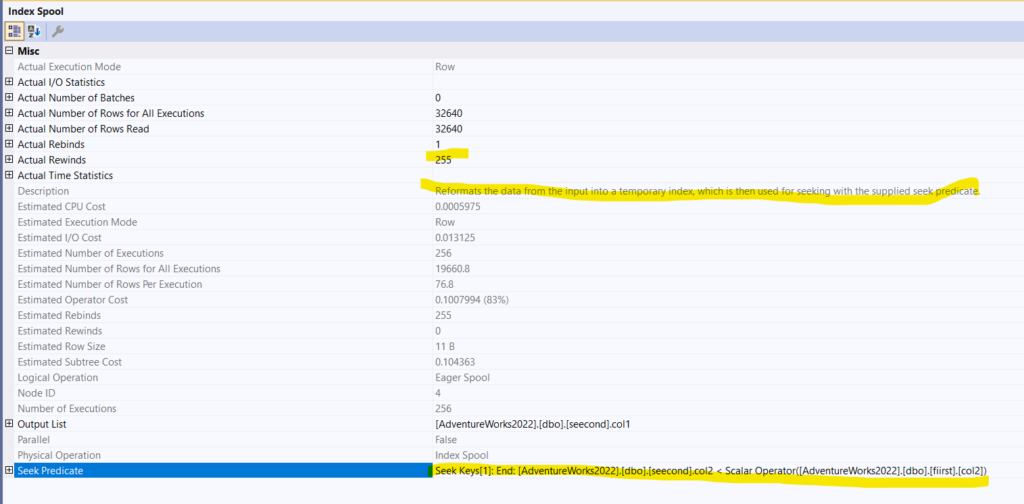
We see that it had to create an index, which is why it is an index spool, temporary one, on the temporary table, on the seek prediacate that it needs to satisfy, if you look at the seek keys, you can see, it needs an index to compare col2 to col2, so it created one so it don’t have to read the entire thing over and over again, but, it had to send the values themselves, for the stream aggregate 256 times, to know the min(col1) value, so it scans, creates a table, then create a clustered index that has col2 including col1, so it could evaluate our filtering predicate,
- After that, it sends that to the stream aggregate:
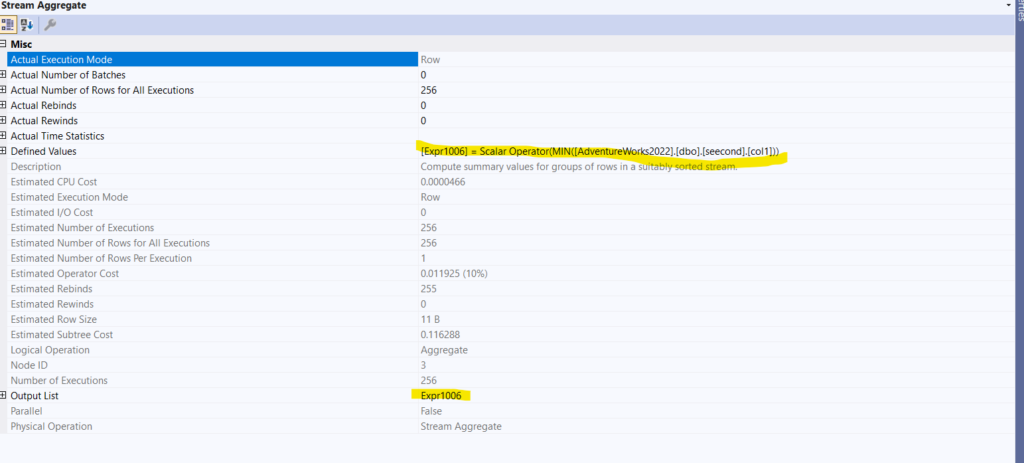
It just finds the minimum from our values, so it reads the temporary index for each col1, which comes from the nested loop’s outer reference = fiirst.col1, then it compares whether min(seecond.col1)<fiirst.col1
- But it can’t do that here, so it just glues, then in the filter:
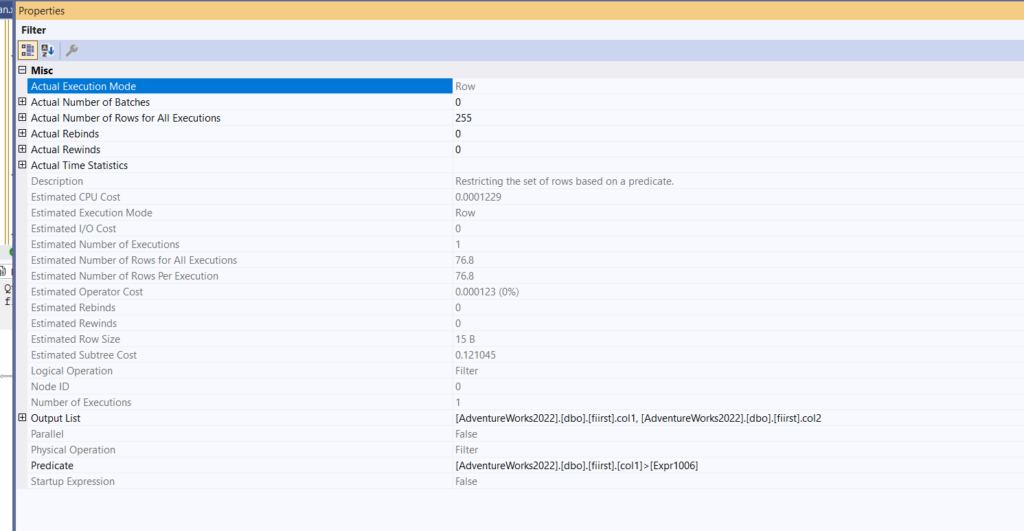
it looks for the joined stuff, expr1006 = min(seecond.col1) so here it evaluates the predicate in the where clause, if it works, it goes to the select, if not, then nothing
Now, here we know there is only 1 minimum value that we have to join and compare to
What if we had more
Assert
Like the following:
select *
from fiirst
where fiirst.col1 =(
select seecond.col1
from seecond
where seecond.col2 =fiirst.col2
);
We get:
So:
- index spool, since we have to compare each col2 to the other col2 in the subquery, as we can see:
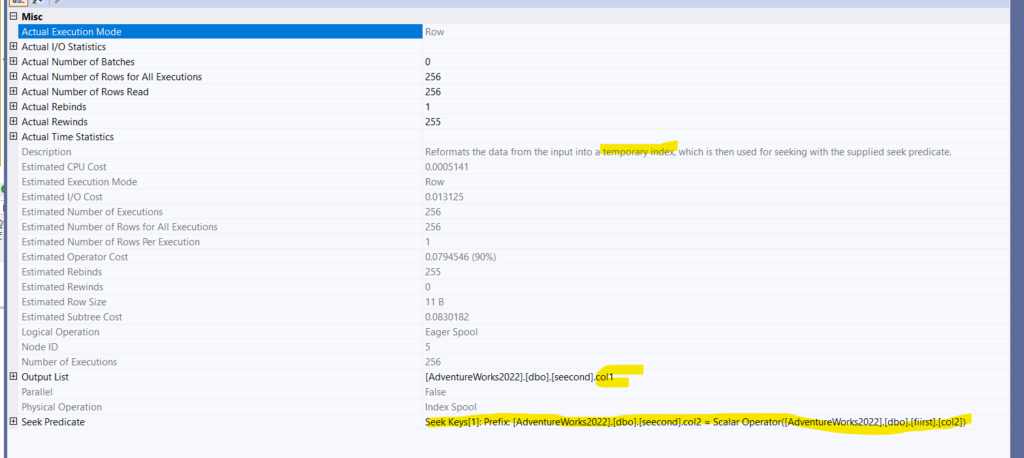
So, if they are equal, we are golden, first equality predicate check
Any aggregate
- New stream aggregate, a stream aggregate that we did not ask for, so what is it?
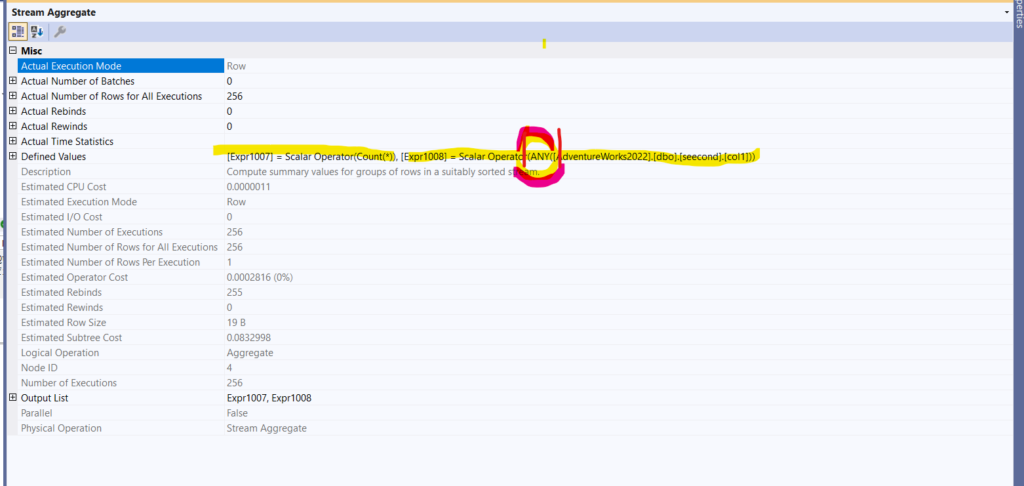
- So why do we have it?
- Like we said before, on each execution, subqueries are supposed to return one row,
- But since we know we don’t have that here, we have to ensure that
- How does SQL Server do that? It counts, so it would have one value, and selects any( the undocumented any that takes any value, like it says, from the index spool, and spits it out)
- Then we get to our assert:
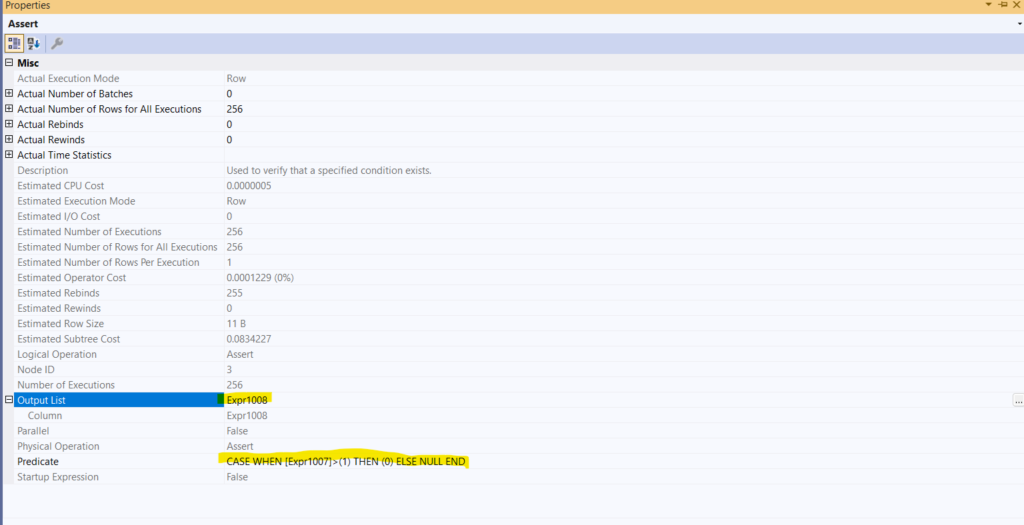
Now here it looks if the count() is more than 1, which is always is, the only reason this operator exists, so it could assure that only one value could be returned per subquery, so it spits out the any aggregate, meaning any value
- Then we have our nested loop:
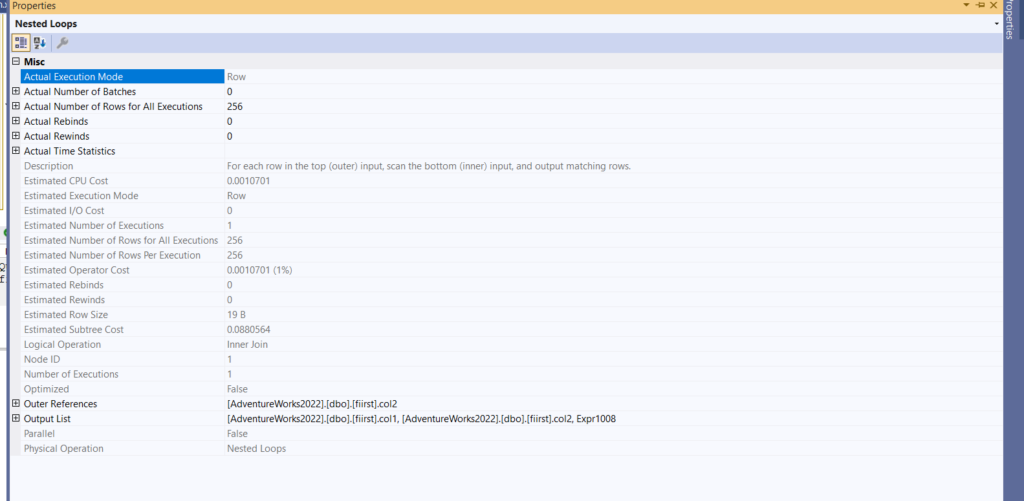
the nested loop here just glues the values, there is no rows to match to as far as I can see, and we evaluated each predicate before the filter operator in the index spool, so there are no issues here, we get some values, and we spit them out so we could compare them to each other in the filter operator:
Filter
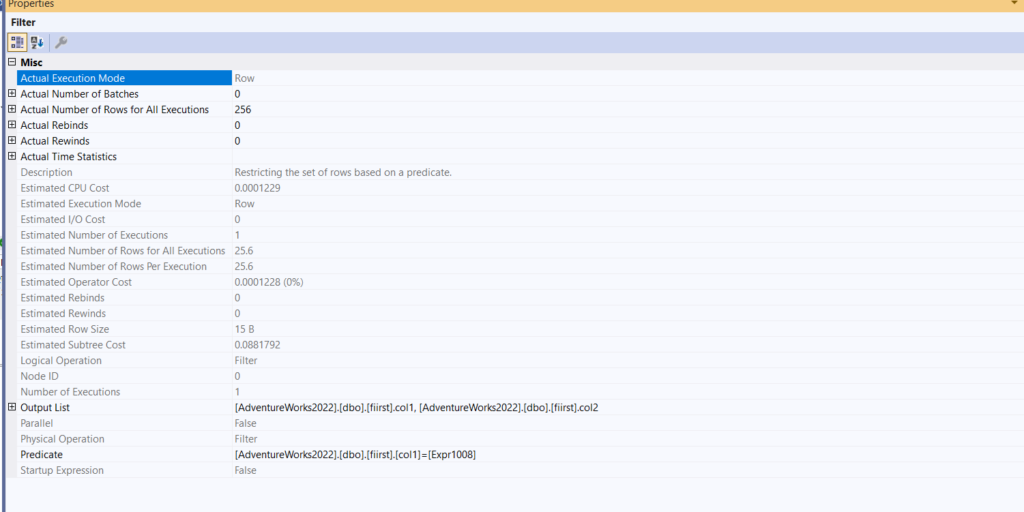
- Now here, it looks if any of the values from the seecond.col1 equals fiirst.col1, meaning if the any aggregate expr1008 matches, if it does, then it sends it
Now the assert operator is cost-free, but it has some pitfalls:
- It is single-threaded and makes the optimizer limit the parallel execution plans for other operators when they exist
- We have to use a nested loop join, meaning it does not scale well with larger inputs
How could we get rid of it?
How to eliminate the assert and index spool
An index spool means we need an index so much that the system created one for us
An assert means we need one row at a time, to fix both, we can create a unique index like:
create unique clustered index ix_CI_seecond_col2 on dbo.seecond(col2)
Now, if we execute again:
select *
from fiirst
where fiirst.col1 =(
select seecond.col1
from seecond
where seecond.col2 =fiirst.col2
);
We get:
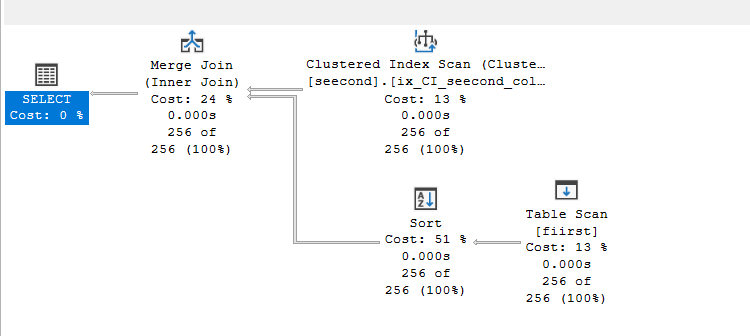
Now this happened because we had a regular, one-key, old-fashioned index, which guarantees one row, but that is not always the case. If we create a composite, we would get the old plan, but no spool.
Let’s drop this index, create a composite, execute, then recreate this one:
drop index ix_CI_seecond_col2 on dbo.seecond
go
create unique clustered index ix_CI_seecond_col2_col1 on dbo.seecond(col2,col1)
go
select *
from fiirst
where fiirst.col1 =(
select seecond.col1
from seecond
where seecond.col2 =fiirst.col2
);
go
--- you should stop here and capture the execution plan
drop index ix_CI_seecond_col2_col1 on dbo.seecond
go
create unique clustered index ix_CI_seecond_col2 on dbo.seecond(col2)
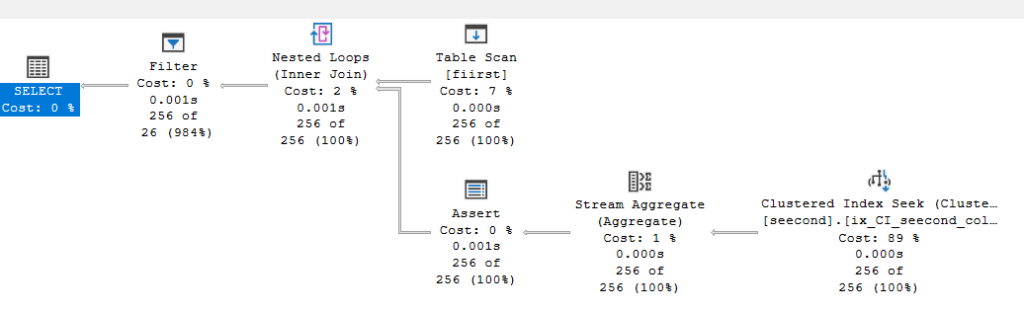
So no spool, since we have the index, and we know the order of col2, so we need to request the values every time, but still we don’t have one row at a time, or a way to guarantee it, so we have our assert and any, and count()
Now let’s get back to the last query with the merge join:
- We have a scan on the Fiirst table, an index scan on the second, nothing new here,
- We have a sort:
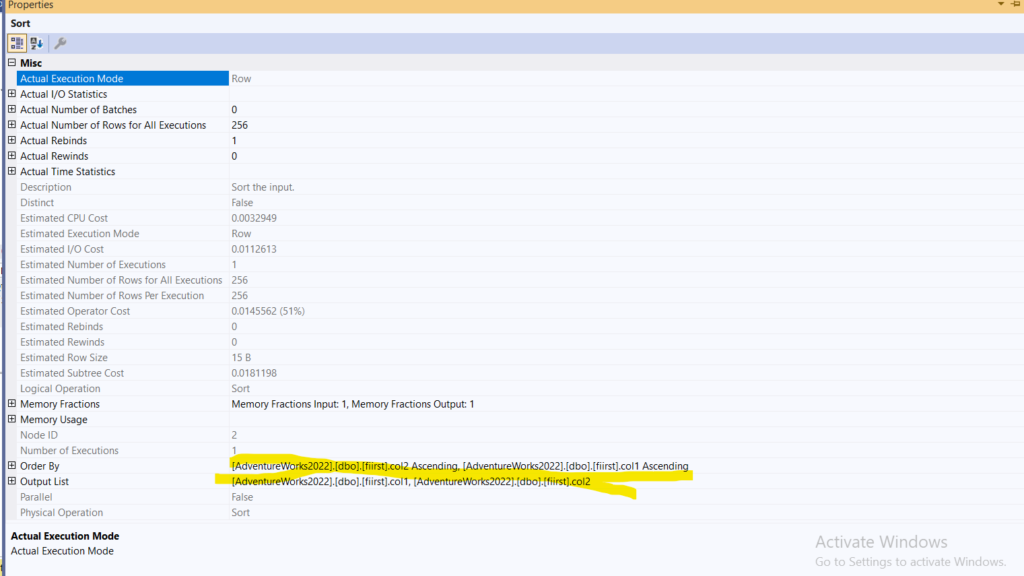
We have it here because the merge needs it, and since we are comparing the equality here, we are comparing both, and the first thing to get compared is col2 so we order by it first, then the second
We already have the sort in the index key in dbo.seecond table, so no need for the sort
Now, if we check the merge properties:

We can see the row estimates improve a lot, since we did not have to read the same data over and over again in a spool, or a stream aggregate, and there is no nested loop
What if we tried the merge without the index:
So we have to drop the index, and force merge:
drop index ix_CI_seecond_col2 on dbo.seecond
go
select *
from fiirst
where fiirst.col1 =(
select seecond.col1
from seecond
where seecond.col2 =fiirst.col2
) option (merge join);
go
We get this error:
Msg 8622, Level 16, State 1, Line 104
Query processor could not produce a query plan because of the hints
defined in this query. Resubmit the query without specifying any hints
and without using SET FORCEPLAN.
So, no merge, only nested if not sorted, and no guarantee of one row at a time
What if we include, instead of composite(which did not work)
So:
create unique nonclustered index ix_NCI_seecond_col2_Inc_col1 on dbo.seecond(col2) include (col1);
go
select *
from fiirst
where fiirst.col1 =(
select seecond.col1
from seecond
where seecond.col2 =fiirst.col2
) ;
go
We get:
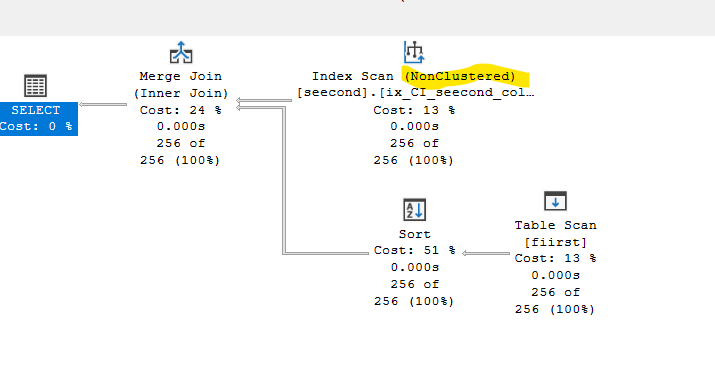
It is still a heap, but at least we got rid of the issue. Let’s clean up now:
drop index ix_NCI_seecond_col2_Inc_col1 on dbo.seecond
How to eliminate that by rewriting instead of creating an index:
Now we had a scalar subquery with an equality predicate(or an inequality) that needed one row at a time
select*
from fiirst f
where f.col1 in (select s.col1
from seecond s
where s.col1 = f.col1
and f.col2 = s.col2
);
We get:
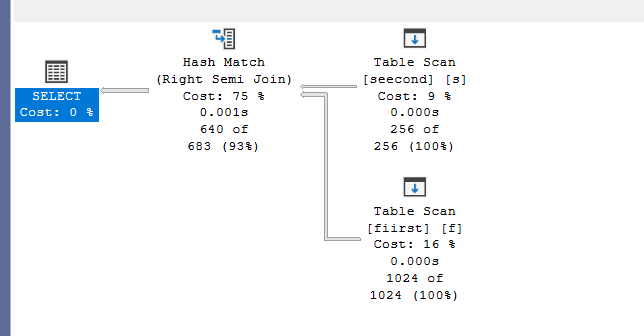
We inserted more rows to get a hash join, so we got it, since we don’t have a scalar subquery anymore
And this does not require sorting
And obviously, we can force merge like this:
select*
from fiirst f
where f.col1 in (select s.col1
from seecond s
where s.col1 = f.col1
and f.col2 = s.col2
) option (merge join)
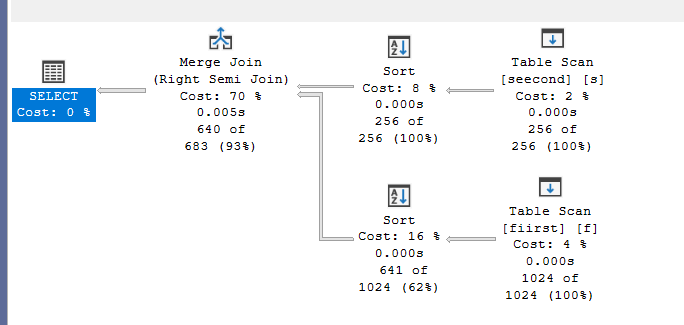
As you can see, we need two sorts here, sorts are expensive and unnecessary.
Or the reason we did this is to get rid of the nested loop, which processes row-by-row:
select*
from fiirst f
where f.col1 in (select s.col1
from seecond s
where s.col1 = f.col1
and f.col2 = s.col2
) option (loop join)
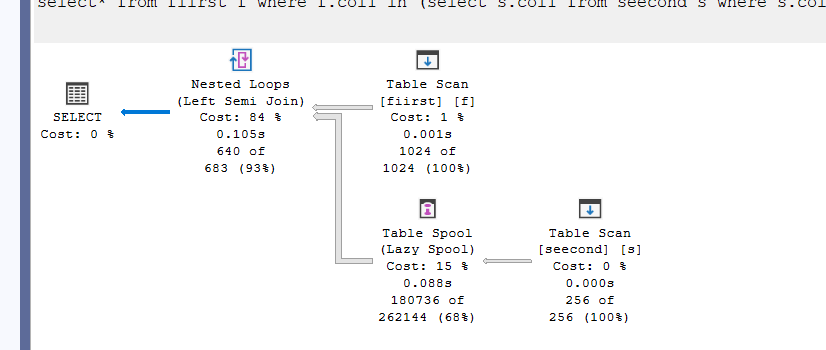
As you can see, way less efficient, and processes a lot more rows, and it is going to compare the whole 256 rows to each row in the first to see if they are equal, a lot of work
Now, back to our hash join query, in the properties of the hash join:
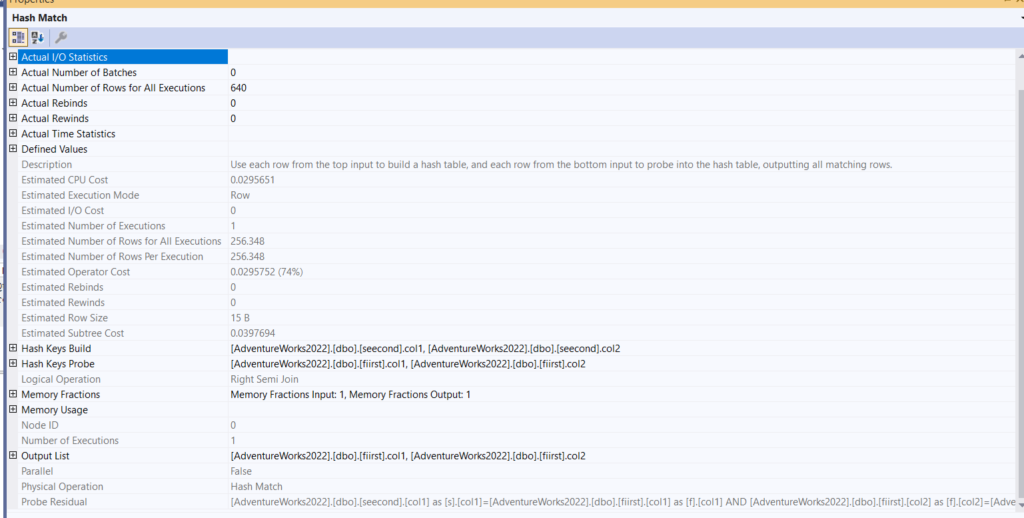
So:
- Two hash key types that would be compared
- The build, which is the smaller, is used to keep the process while comparing the equals, more quicker; it is the first to be hashed, then for each row from the second
- The probe that would be hashed and compared to the build, we see if our stuff matches
- If they do, we do a semi-join, which is a join with no rows from the second table, meaning we only get the rows from the dbo.fiirst if they match our filtering conditions from the dbo.seecond
We will talk about both in future blogs
Another potential rewrite: EXISTS
Like:
select*
from fiirst f
where exists( select f.col1
from seecond s
where
s.col1 = f. col1
and f.col2 = s.col2
)
We get:
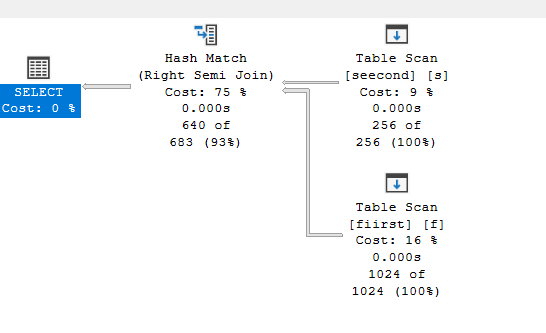
same stuff.
Logically different
But, if we do the following:
select*
from fiirst f
where f.col1 in(select s.col1
from seecond s
where s.col1<f.col1
and s.col2<f.col2);
We get:
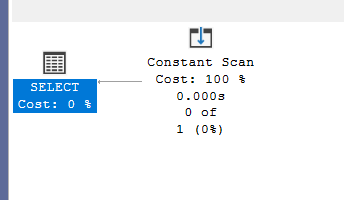
This is similar to our first query. Here we have an early phase optimization, but since no rows that could satisfy the predicate, it chose to give a constant scan that basically says there are no rows
And we finish our blog here, see you in the next one.
Resources: