
identifying unqiueidentifiers in indexes
Now, as we introduced it before, NEWID() function introduces a lot of fragmentation if indexed, since there is no way to know what the next value would be, every insert might be at the end or the start, even with enough fill factor, after a certain threshold, internal and external fragmentation are inevitable
Now, in the URL mentioned above, we introduced several ways to get around this issue
Now, today we are going to try to detect the indexes using the system catalog views we introduced in the previous blog:
use testdatabase
go
select
t.object_id,
s.name + '.' + t.name as table_with_schema_name,
i.name,
i.is_disabled,
tp.sum_rows
from sys.tables t inner join sys.schemas s on s.schema_id = t.schema_id
inner join sys.indexes i on i.object_id = t.object_id
cross apply (
select sum(p.rows) as sum_rows
from sys.partitions p
where i.object_id = p.object_id
and i.index_id = p.index_id
) tp
where t.is_memory_optimized = 0 and t.is_ms_shipped =0 and i.is_hypothetical = 0 and i.type in (1,2)
and exists (select*
from sys.index_columns ic inner join sys.columns c
on ic.object_id = c.object_id
and ic.index_id = i.index_id
and ic.key_ordinal = 1
and c.system_type_id = 36 ---- uniqueidentifier the type we use and have the issue with
)
order by tp.sum_rows desc
;
Now, here we want the table name and its schema ordered by the sum of rows in all partitions
So, we joined tables with schemas and indexes, plus the number of rows in all partitions
where it is in the index columns catalog view, and the first key_ordinal has the datatype 36, which is the uniqueidentifier
And we got this:
So, as you can see from our previous tests, we have all the uniqueidentifier indexes
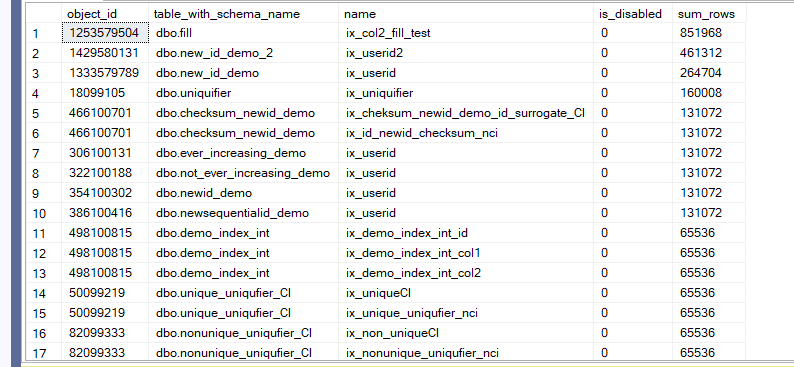
For ways to deal with it, check out the blog mentioned above
Wide and non-unique clustered indexes
Now in here, we talked about the issues introduced by wide indexes,
First, every nonclustered index has to have the keys
So it would increase the storage for everyone
Secondly, the updates would take longer for everyone
3rd, the page and what it would accommodate would decrease, leading to less data stored with each
and with non-unique you get extra bytes for the null and the uniquifier introduced by the storage engine itself so it could differentiate between duplicates, and even if you did not have any duplicates, since you did not have the unique constraint, SQL server would introduce 2 extra bytes just in case for each row, meaning you should specify if it, instead of having the engine do it for you with extra overhead
And a lot more details in the above URL
Now, how could we identify them:
use testdatabase
go
select
t.object_id,
s.name + '.' + t.name as table_name ,
tp.sum_rows,
ic.max_length
from sys.tables t inner join sys.schemas s on s.schema_id = t.schema_id
cross apply (
select sum(p.rows) as sum_rows
from sys.partitions p
where p.object_id = t.object_id
and index_id =1
) tp
cross apply(
select
sum(c.max_length) as max_length
from sys.indexes i inner join sys.index_columns ic on
i.object_id = ic.object_id
and i.index_id = ic.index_id
and ic.is_included_column = 0
inner join sys.columns c on
ic.object_id = c.object_id
and ic.column_id = c.column_id
where
i.object_id = t.object_id
and i.index_id = 1
and i.type = 1
) ic
where
t.is_memory_optimized = 0
order by
ic.max_length desc;
So we want the table name and scheme where it is clustered
We joined the first two
Cross applied the third with the number in all partitions
where the index is clustered and it is not an included one in the clustered since we only see that in the data pages, not the index itself, and if we were to update the value of the key, we don’t have to update it
And we only want the id to be 1, so clustered, same with the type; we requested the information we wanted the clustered index max_length and ordered by it
The output for our database was:
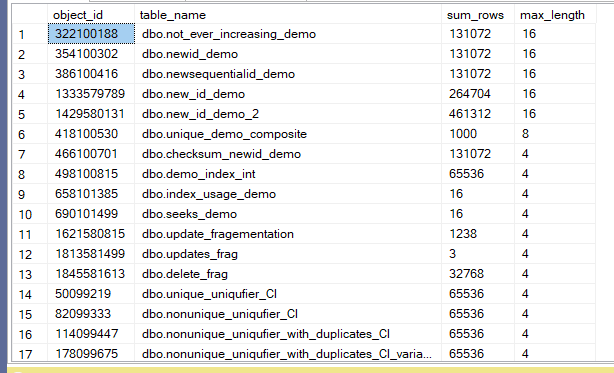
So nothing too wide here, but still we should evaluate it on a table basis and see if we can do some modifications if we are allowed to
Now, if we run it in Contoso:
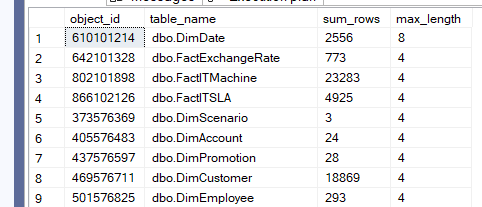
Nothing too wide, but again, we should look at the table
If we run it in AdventureWorks2022:
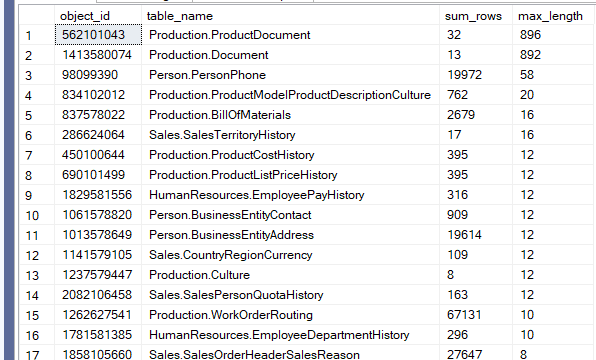
So, as you can see here, we have a huge clustered index
Again, if this was necessary for a covering query or something like that, we should keep it.
Identifying non-unique clustered indexes
For it should be unique, you can look up our blog on clustered index design
Now, how can we detect clustered indexes that do not have that:
use testdatabase
go
select
t.object_id,
s.name + '.' + t.name as table_name ,
tp.sum_rows
from sys.tables t inner join sys.schemas s
on s.schema_id = t.schema_id
cross apply (
select
sum(rows) as sum_rows
from sys.partitions p
where
p.object_id = t.object_id
and p.index_id = 1
) tp
where t.is_memory_optimized = 0
and exists(select*
from sys.indexes i
where
i.object_id = t.object_id
and i.index_id = 1
and i.is_unique = 0
and i.type = 1
)
order by
tp.sum_rows
desc
nothing much here, the new thing her i.is_unique = 0, meaning non-unique indexes
And we got:
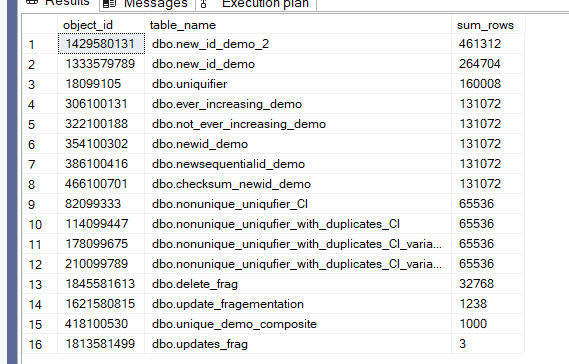
So, as you can see, we can identify them easily.
Untrusted foreign keys
We will talk about them in another blog, but if you want foreign key join elimination(here), data integrity
Now, when you define it with nocheck, SQL Server does not verify the existing data, only the new one,
which causes query optimizer issues.
Now, how can we detect them:
use ContosoRetailDW
go
select fk.is_not_trusted, fk.is_disabled,
fk.name,
par_s.name + '.' + par_t.name as parent_name,
chi_s.name +'.' + chi_t.name as child_name,
fk.delete_referential_action_desc,
fk.update_referential_action_desc
from
sys.foreign_keys fk inner join sys.tables par_t on fk.parent_object_id = par_t.object_id
inner join sys.schemas par_s on par_s.schema_id = par_t.schema_id
inner join sys.tables chi_t on fk.referenced_object_id = chi_t.object_id
inner join sys.schemas chi_s on chi_s.schema_id = chi_t.schema_id
where fk.is_not_trusted =1 or fk.is_disabled = 1
nothing fancy here, we filtered by the joins, using the parent and child objects, parent and referenced
Then we looked for the non-trusted keys and queried them
Now the default Constoso does not have that issue, but before testing, i ran this:
alter table FactExchangeRate nocheck constraint FK_FactExchangeRate_DimCurrency;
alter table FactExchangeRate nocheck constraint FK_FactExchangeRate_DimDate;
alter table FactITMachine nocheck constraint FK_FactITMachine_DimDate;
alter table FactITMachine nocheck constraint FK_FactITMachine_DimMachine;
alter table DimStore nocheck constraint FK_DimStore_DimGeography;
alter table FactITSLA nocheck constraint FK_FactITSLA_DimDate;
alter table DimCustomer nocheck constraint FK_DimCustomer_DimGeography;
alter table FactITSLA nocheck constraint FK_FactITSLA_DimMachine;
alter table DimSalesTerritory nocheck constraint FK_DimSalesTerritory_DimGeography;
alter table FactITSLA nocheck constraint FK_FactITSLA_DimOutage;
alter table DimEmployee nocheck constraint FK_DimEmployee_DimEmployee;
alter table FactITSLA nocheck constraint FK_FactITSLA_DimStore;
alter table DimMachine nocheck constraint FK_DimMachine_DimStore;
So we got this:
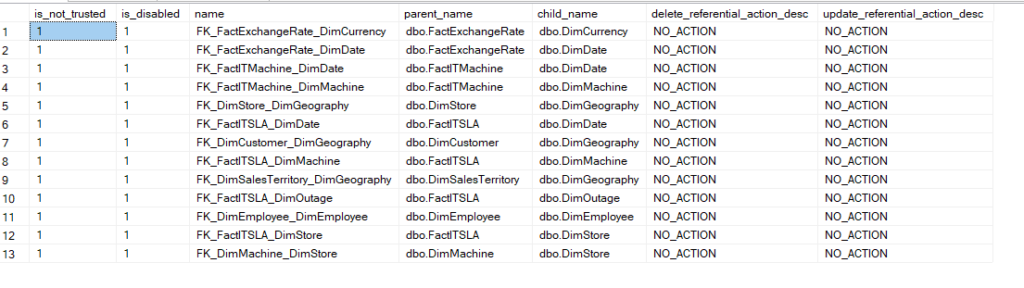
Now, how could we reverse this:
alter table FactExchangeRate with check check constraint FK_FactExchangeRate_DimCurrency;
alter table FactExchangeRate with check check constraint FK_FactExchangeRate_DimDate;
alter table FactITMachine with check check constraint FK_FactITMachine_DimDate;
alter table FactITMachine with check check constraint FK_FactITMachine_DimMachine;
alter table DimStore with check check constraint FK_DimStore_DimGeography;
alter table FactITSLA with check check constraint FK_FactITSLA_DimDate;
alter table DimCustomer with check check constraint FK_DimCustomer_DimGeography;
alter table FactITSLA with check check constraint FK_FactITSLA_DimMachine;
alter table DimSalesTerritory with check check constraint FK_DimSalesTerritory_DimGeography;
alter table FactITSLA with check check constraint FK_FactITSLA_DimOutage;
alter table DimEmployee with check check constraint FK_DimEmployee_DimEmployee;
alter table FactITSLA with check check constraint FK_FactITSLA_DimStore;
alter table DimMachine with check check constraint FK_DimMachine_DimStore;
And run the previous query again:

With that, we finish today’s blog. See you in the next one.