
Here we introduced few catalog views so we could do some schema analysis, to know if our index strategy lacks any immediate threats.
We started with heaps
sys.tables:
Now, if we select* like:
use testing
go
select*
from sys.tables
We would get:

A lot of these columns are inherited from sys.objects:
- name
- object_id
- principal_id: who is the owner
- schema_id
- parent_object_id: 0 not a child object
- type: U means user table this
- type_desc: same here
- creation and modify dates
- is_ms_shipped: created by ms = Microsoft = is an internal component
- is_published: It is about replicas
- is_schema_published: same, but for the schemas
Those are the inherited ones
Now, what is the use of sys.objects?
Some examples:
select
OBJECT_SCHEMA_NAME(object_id,db_id()) + '.' + OBJECT_NAME(object_id) as object_name,
type_desc,
modify_date
from sys.objects
where modify_date >='2025-03-23 15:35:41.497'
order by modify_date
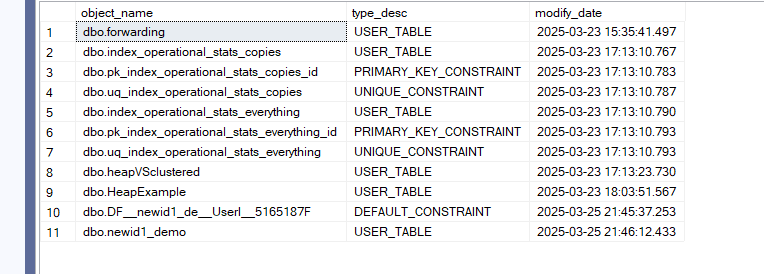
Here we have the objects modified since March 23rd, and what they are in this database
Now if we go back to sys.tables:

- lob_data_space_id: the id of the filegroup that contains the LOB data same goes for filestream
- max_columns_id_used: the id of the biggest columns
- lock_On_bulk_load: whether we used minimally logged operations or not
- ansi thing
- is_replicated
- has_replication_filter
- Is_merge_published something that relates to replication
- is_trans …… replication
- has_uncheked_assembly_data something that is so internal that it relates to actual assembly code
- text_in_row_limit now we don’t have limits, so no limits

- large_value_types_out_of_row overflow or lob
- is_tracked_by_cdc when you want to track extra stuff using cdc
- lock_escalation
- What type of lock escalation
- had filestream enabled
- Is it a memory table
- schema or schema and data, the later is 0
- same here
- Temporal tables are tables stored to track data, so here it tracks that information
- Is_remote_data_archive_enabled is this a stretch database

- External tables store metadata about tables outside SQL Server
- history stuff is for temporal tables
- is_node edge is for Graph SQL in SQL Server
- After that, until ledger table is about Azure SQL edge
- The ledger stuff is for a new feature in SQL Server 2022 for auditing
And with that, this ends
sys.indexes
If we select* like:
select*
from sys.indexes
We get:
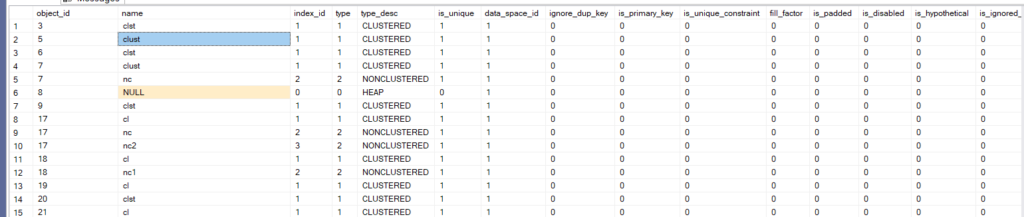
- object_id: as you can see there are a lot of internal tables and their indexes for example the 3 is syscols etc.
- index_id: like we said before 1 is always clustered 0 is always heap and nonclustered increments from 2 to the end
- type: 0 heap, 1 clustered, 2 nonclustered, 3 XML ……
- type_desc: same
- is_unique: unique
- data_space_id: filegroup or partition schema
- is_primary_key
- is_unique_constraint has a unique constraint
- fill_factor internal fragmentation, check out our fragmentation blogs in this series
- is_padded internal fragmentation for intermediate index levels
- is_disabled when you put the index out of use, disable it
- is_hypothetical holds only column-level statistics and not actual data, DTA creates them so as we
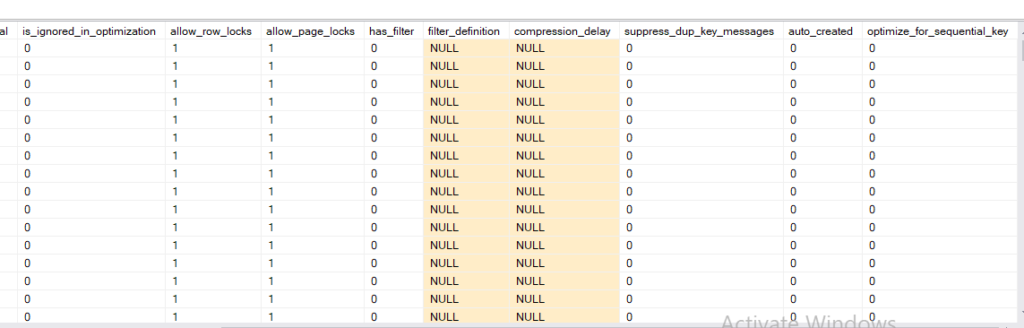
- is_ignored_in_optimization is not considered in tree generation
- allow_row_locks and page: you can hold these types of locks on i
- has_filter: filtered
- compression_delay How long would a columnstore index hold its breath until compression
- suppress_dup_key_messages . Paul White, this option ignores duplicates inserted at a unique or primary key, the constraint does not allow duplicate messages would be ignored Paul white
- auto_created did use a tool to create it, or not like DTA
- optimize_for sequential_key: we talked about before in the ascending_key_issue that was addressed first by a trace flag, then by incorporating it to the whole engine
And with that, this is over
sys.columns
Now if we select* like:
select*
from sys.columns
where OBJECT_ID(N'dbo.index_operational_stats_copies') = object_id
and we got:
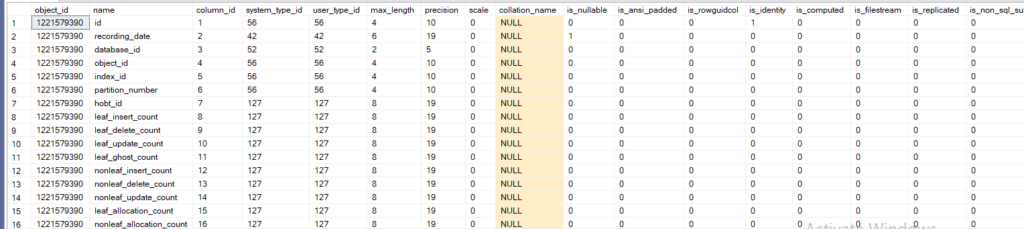
- object_id
- name
- column_id according to creation
- system_type_id and user_type_id datatype id for example 56 int
- max_length in bytes
- precision if numeric otherwise 0
- scale means how many digits after the decimal point
- collation_name if it is character based otherwise 0
- is_nullable
- ansi
- is_roguidcol
- is_identity like our identity(1,1)
- is_computed
- is_filestream
- is_replicated
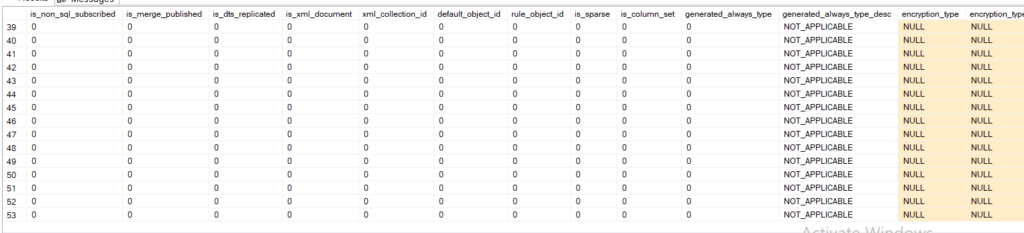
- is_non_sql_subscribed replicated in another server that does not use SQL server
- is_merge_published
- is_dts(SSIS)_replicated
- is_xml_document
- xml_collection_id
- defualt_object_id when we use default in the column and that default constraint fills the space it references the column, unless you bind it then it references itself
- rule_object_id if you create your own way of data integrity this would be the object_id for it if you use it in a column
- is_sparse
- is_column_set a way to store data in sparse columns
- generated_always_type is the one generated by the engine not the user and the types differ by edition
- encryption stuff
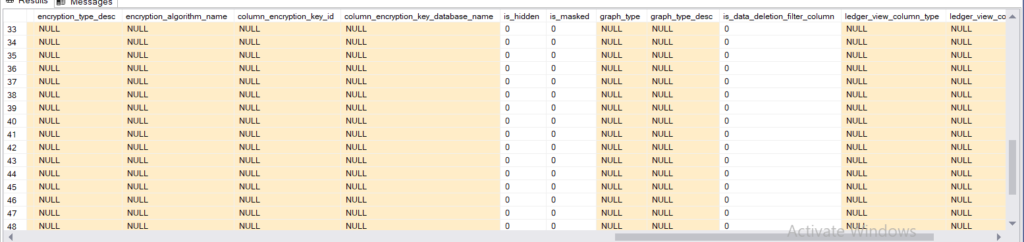
- then graph SQL stuff
- is_data_deletion…. Azure Edge stuff
- after that all ledger stuff for auditing
And with that, this catalog view is done
sys.index_columns
if we select*
select*
from sys.index_columns
where OBJECT_ID(N'dbo.index_operational_stats_copies') = object_id
we get:

- object_id
- index_id
- index_column_id is index-specific while the column_id is table-specific
- key_ordinal is the first key or not, if not, which key is it
- partition_ordinal if you partition by multiple columns, this would tell at which key is it if it is at all
- is_descending_key now the default is ascending so when it is descending this lights up
- column_store_order_ordinal same here
and with that, we finish this one
sys.foreign_keys
go
use ContosoRetailDW
go
select*
from sys.foreign_keys
And we got:
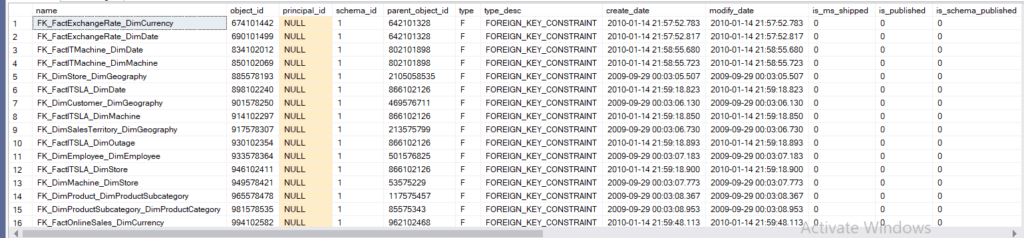
so:
- name
- object_id
- principal_id = owner id
- schema_id
- parent_object_id: the table that has the foreign key declared in it, the child table itself since the constraint is an object
- Type F means foreign
- type_desc
- create and modify dates
- is_ms_shipped
- is_published
- is_schema_published
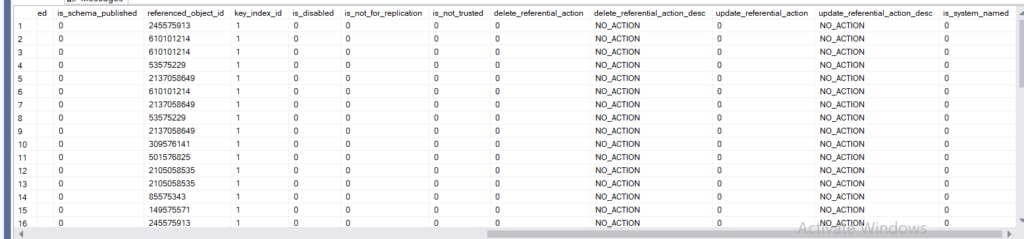
- referenced_object_id, where the key is the primary key
- key_index_id
- is_disabled for the foreign key, not the index
- is_not_for_replication
- is_not_trusted
- delete_referential_action_desc: how should we perform the delete 4 options we will talk about them in another blog
- same for the update
- is_system_name
sys.foreign_key_columns
select *
from sys.foreign_key_columns
We get:
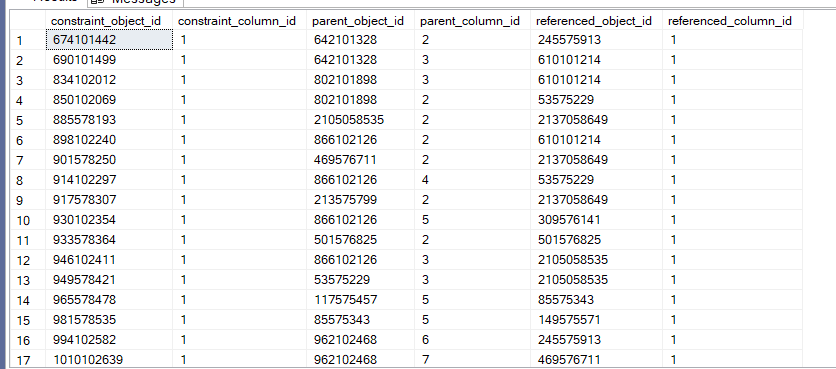
so object_id for the constraints tables and their columns
nothing much
obviously we can’t just read it like this, but if we join it with the sys.foreign_keys like they did in the docs, we would get:
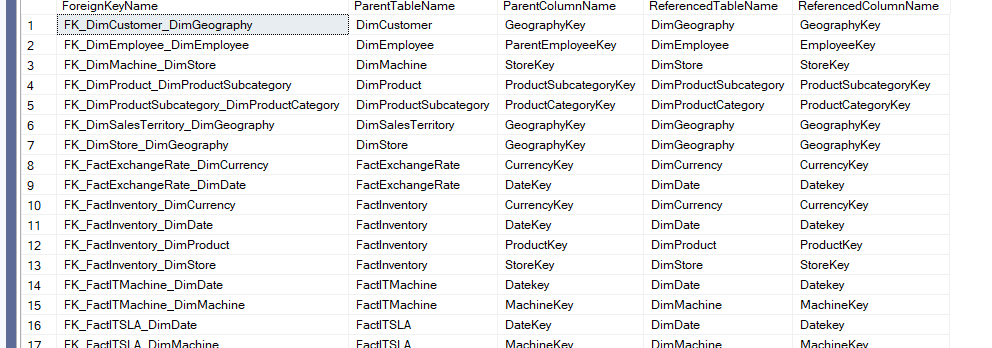
Now that we have introduced them, we are going to use them in schema analysis:
Schema Analysis
Using the above-mentioned catalog views, we can identify multiple issues like:
- Heaps
- Uniqueidentifier
- Wide and non-unique indexes
- Untrusted foreign keys
- nonindexed foreign keys
- redundant indexes
- high identity values
Heaps
According to this Microsoft whitepaper
We could use heaps in:
- very small table
- RID is smaller than the clustered index key More on that in our previous blogs in this series on heaps and clustered indexes, but basically it is a physical locator if we don’t have a physical design in mind( clustered index) that the engine creates for us so we could reach it, sometimes it is smaller the clustered index key in mind
- Inserts are not a good idea for heaps since clustered beat it in the above URL
- Same with updates and deletes
- selects as well
So, most of the time, you should not use heaps, and they are a problem
So, how could we identify them using the explained catalog views:
go
use testing
go
select
t.object_id as object_id,
s.name + '.' + t.name as table_name,
tp.sum_rows
from sys.tables t inner join sys.schemas s
on t.schema_id = s.schema_id
cross apply
(select sum(p.rows) as sum_rows
from sys.tables t inner join sys.partitions p
on t.object_id = p.object_id
and p.index_id = 0
) tp
where t.is_memory_optimized = 0
and t.is_ms_shipped = 0
and
exists
(
select*
from sys.indexes i
where t.object_id = i.object_id
and i.index_id = 0
)
order by tp.sum_rows desc
So here we wanted the heaps, so in the exists clause we asked for indexes that have the id of 0
Since we want the table name to do any analysis, we asked for sys.tables , sys.schemas
And the total_rows matters to know if the modifications are worth the effort
Other that we don’t have much here
And we got:
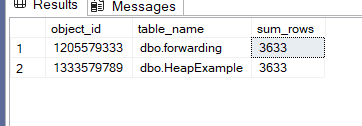
As you can see here, both small tables are so we could just ignore them
But let’s assume we are about to do something about them
So, what we could do is use the methodology described in our PerfMon counters blogs
Specifically, the blog on fullscans, and there we identifiedforwarded records per second
There, we used the operational, usage, and physical stats to identify how much of an effect these heaps have on the system
And we observed the effects of forwarding records in this blog
But basically, forwarding records introduces extra i/o since you can’t use the space at the moment
But you have a forwarding stub, a pointer, and a forwarded record, each has extra space and the record has its own page
So a lot of overhead for nothing
And internal fragmentation, since a heap can never reclaim the space which we talked about in this blog
Alternatively, we can use the cache, like we initially do:
go
select
t.object_id,
s.name + '.' + t.name as table_name ,
sum(ps.record_count) as heap_records_sum,
sum(ps.forwarded_record_count) as forwarded_record_sum,
sum(ps.avg_page_space_used_in_percent* ps.page_count)/nullif(sum(ps.page_count),0) as internal_fragmentation_in_percent
from sys.tables t inner join sys.schemas s on s.schema_id = t.schema_id
cross apply sys.dm_db_index_physical_stats(db_id(),t.object_id,0,null,'detailed') ps
where
t.is_memory_optimized = 0
and t.is_ms_shipped = 0
and
exists (
select*
from sys.indexes i where t.object_id = i.object_id and i.index_id = 0
)
group by t.object_id,s.name,t.name
order by forwarded_record_sum desc ;
Now what we did here is fairly simple, so we wanted to get heap,s so we looked for indexes that have the index_id = 0 in the exists clause
And we wanted the table and schema name, so if we wanted to generate some scripts, we know exactly where to strike
Now we are looking to monitor forwarding pointers, so we cross-applied to the index_physical_stats
And we grouped them by their names
Order them by forwarded records, since that is what we are monitoring
Other than that, we don’t have much in this query
And we got this:

So here we can see the high percentages of forwarded in both. If we knew how many forwarded records have been requested by the blogs mentioned, we could know if we want to do the modification
or we can just go ahead and do it if the structure is good for an index
and with that, we finish our intro blog to schema analysis, see you in the next one.