
today we are going to introduce the second tool, DTA or database tuning advisor
Introduction
it can use a workload from a:
- file
- table
- plan cache
- or query store
it is low cost
it is integrated
it is quick
it could be misused if not provided with a representative workload for recommendations
it can recommend indexes on the following:
- rowstore and columnstore
- aligned or non-aligned partitions\
- indexable views
we have a lot of knobs
we can use only data warehouse data workload or OLTP
cons could be the fact that it can’t recommend system table indexes
can not modify anything that has unique constraints in it
recommendations are based on sampling
no remote servers
now if we have limited resources and we run the session on production it might not run like running out of space
so with that, as we said for missing indexes, you can’t just apply the suggestions, you have to test them in Dev.
The graphical user interface
now if we wanted to automate the process, using the DTA command line utility would be the best idea
but both provide the same capabilities and since we are introducing the concepts we are going to start with this and see where it goes
so if we open SSMS and at the top click on tools
we can find the database engine tuning advisor
so we connect it to the server like we connect in SSMS
and with that we start

and this would pop up
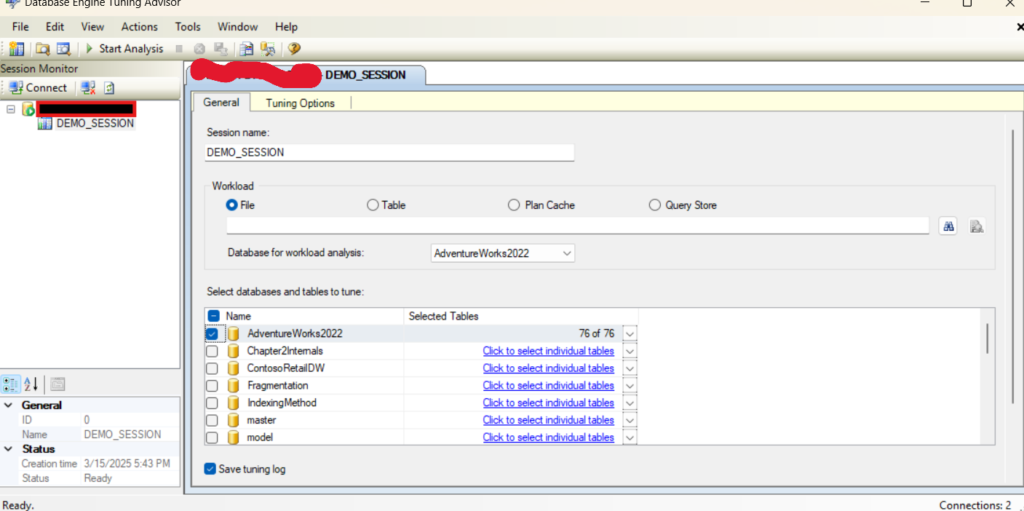
now here we can see that we can attach 4 types of workloads that we could test
We have the query store
the plan cache so it could use what we have in cache
we have a file that could be SQL server file .sql
or we can create a table and insert traces or extended events in it and use the table option
we are going to use the file option
and here we select all the tables in adventure works
now here we are going to SSMS:
use adventureworks2022
go
select OrderDate
from Purchasing.PurchaseOrderHeader
where OrderDate = '2013-04-25 00:00:00.000'
and ShipDate = '2013-05-04 00:00:00.000'
go
select OrderDate
from Purchasing.PurchaseOrderHeader
where OrderDate between '2011-04-16 00:00:00.000' and '2011-12-14 00:00:00.000'
and ShipDate between '2011-04-25 00:00:00.000' and '2011-12-23 00:00:00.000'
go
select OrderDate,ShipDate
from Purchasing.PurchaseOrderHeader
where orderdate between '2011-04-16 00:00:00.000' and '2011-12-14 00:00:00.000'
go
select ShipMethodID,OrderDate
from Purchasing.PurchaseOrderHeader
where orderdate between '2011-04-16 00:00:00.000' and '2011-12-14 00:00:00.000'
and
ShipDate between '2011-04-25 00:00:00.000' and '2011-12-23 00:00:00.000'
go
use AdventureWorks2022
select EmailPromotion
from Person.Person
where EmailPromotion = 2
or EmailPromotion = 0
go
select emailpromotion
from person.person
where emailpromotion = 1
go
select emailpromotion, Suffix
from person.person
where emailpromotion = 1
and Suffix = 'Jr.'
go
after that we hit Ctrl + S we name the file we save it
then in DTA GUI:
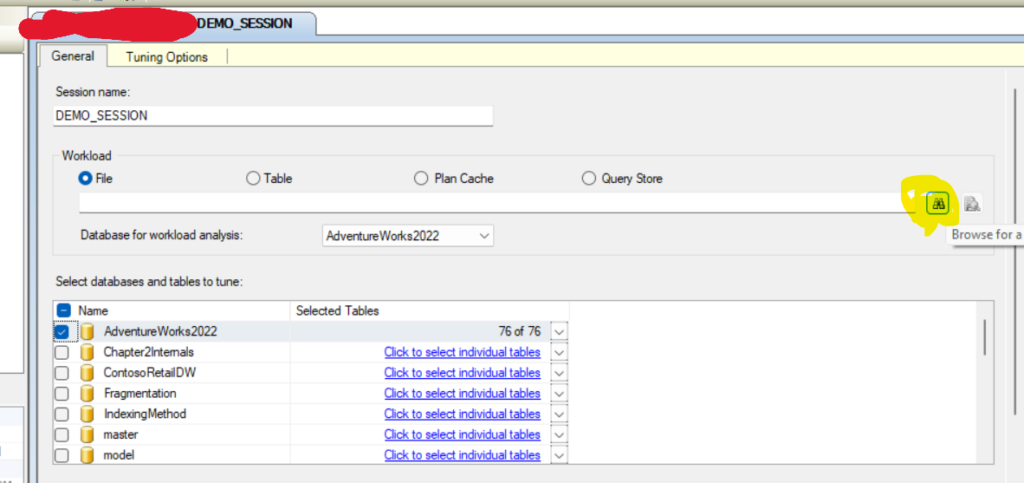
and we click on our demo
after that we can configure the specific database or maybe the whole instance that we want to select like:

now here we selected the whole adventureworks2022
now here we can get configuration options for start and restart and font and stuff like that at the start:
after that if we click on tuning options like:
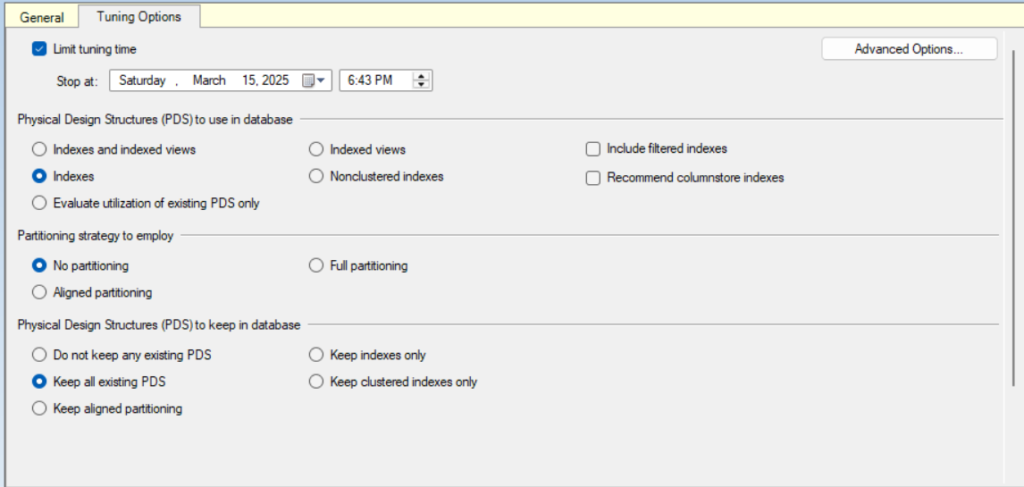
here we can configure the PDS or the physical structures we want to keep, what kind of suggestions do we want
do you want:
- clustered
- nonclustered
- to index a view or not to
- do you want filtered indexes to be considered
- do you want columnstore
- and even if you choose columnstore it would not necessarily recommend it since it might not be a good fit for the workload, the docs did a test and showed that not each database would be tuned equally even if the option is enabled, so it would only consider the necessary ones
- how long do you want to run it and when, while running forever is not good, but running for a long time on a huge database, so here we can run it shortly
- then we have the partitioning options, now here do you want to align indexes with partitions, do you want partitions
now we should run these tests, since they are highly resource intensive in a Dev environment that simulates the actual database, or create hypotheticals(more on it later)(docs)
now if we click on advanced options:
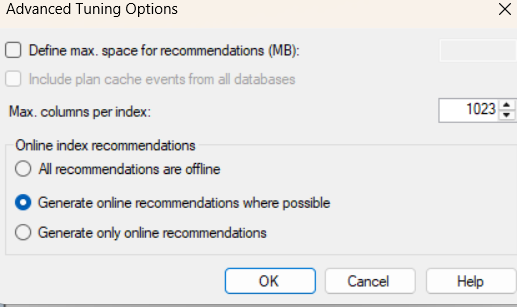
we can define the number of included columns whether we want our operations online or offline
now after that we should click on start analysis

now this was the progress screen

and this was the output and reports:
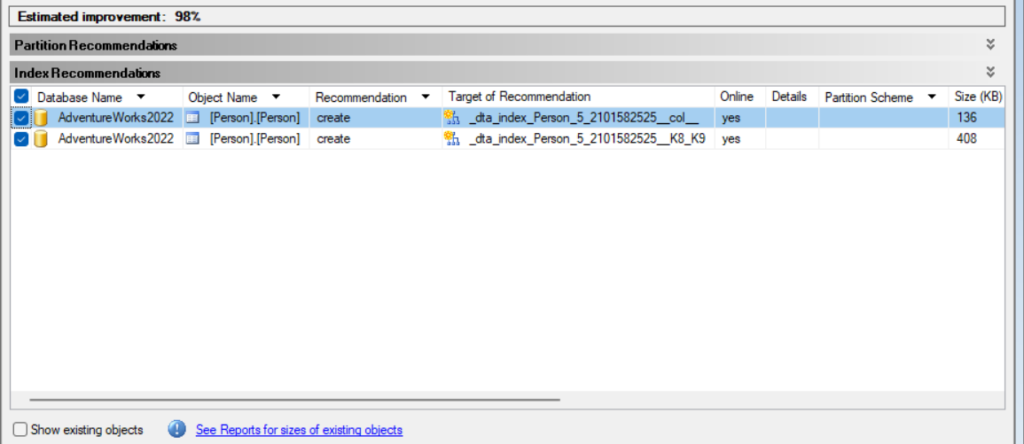
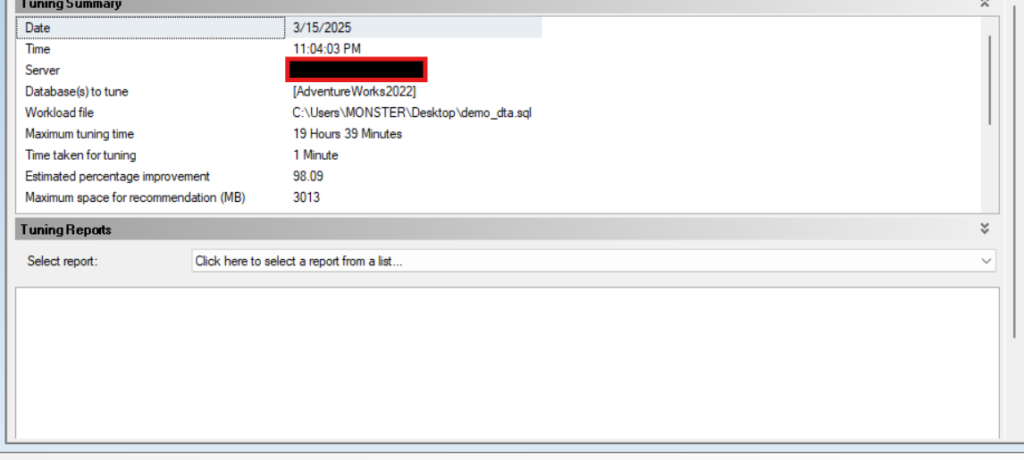
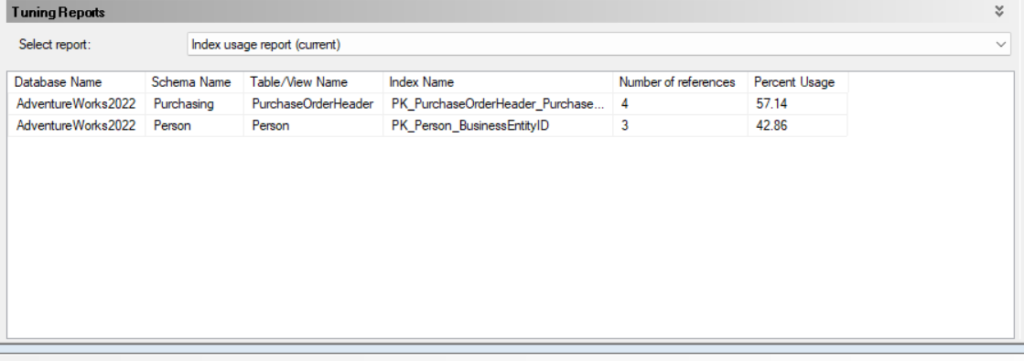
now here is an example report, here it shows what indexes are being used while accessing the query in the file and how often
now in statement cost report:
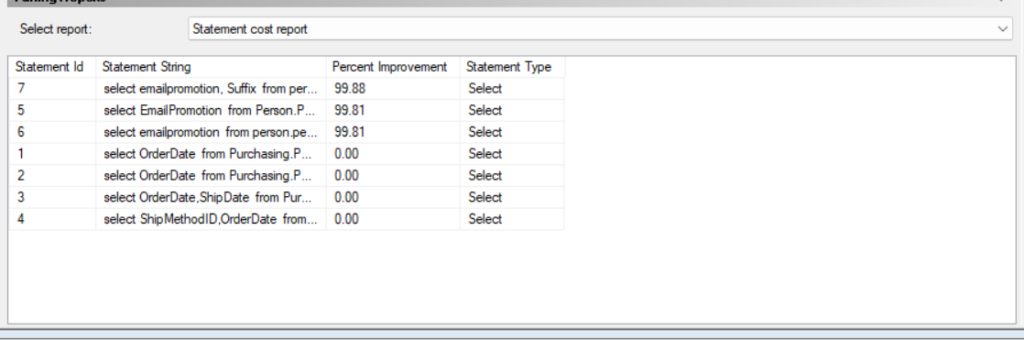
you can see the each statement’s cost improvement by the new index
now in the upper tuning summary:
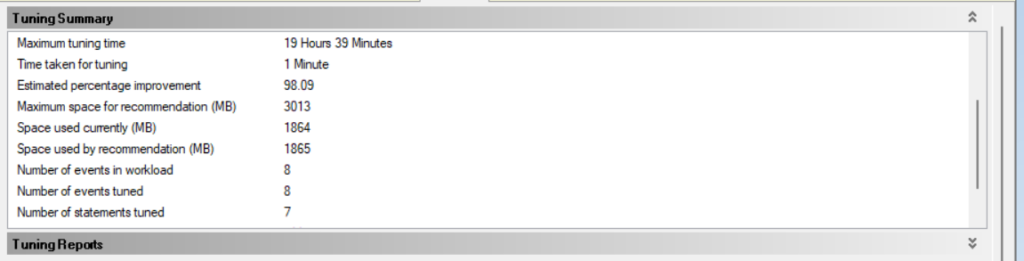
we can see how long it took, the max it might take
the amount used by the tuning session and how much did we already use
number of events, we submitted in the file and how many did it tune, since one of them has been covered by the primary

at the end of the summary we can see the amount of indexes the DTA wants to create
in event frequency report we can see how often each happened
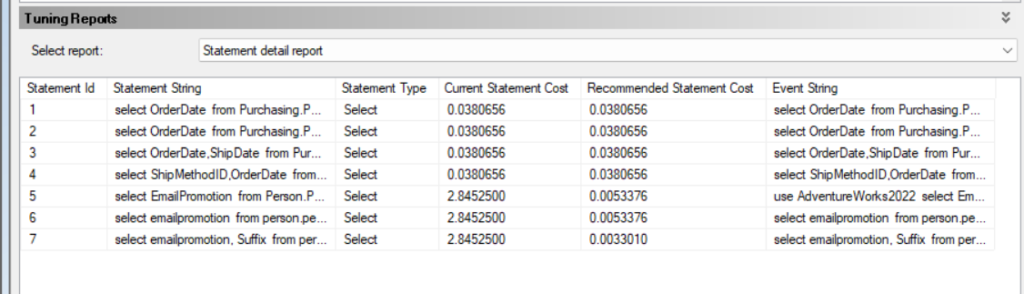
now here we see detail before and after improvement, now here it did not suggest indexes for all of them
and here we supplied the query’s string, if we did not do that in extended events, it is not going to include that information
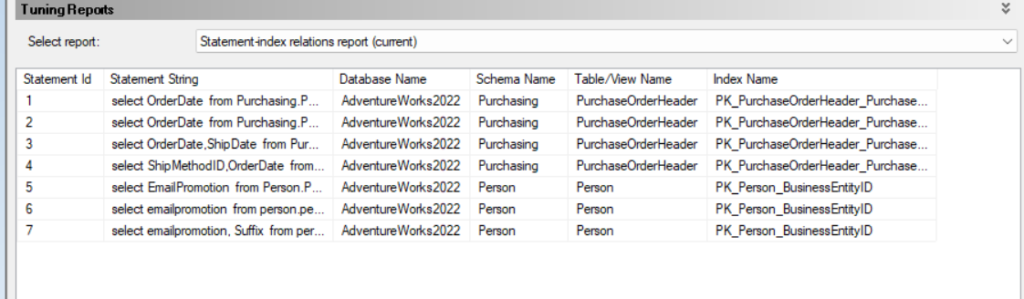
now here we can see what tables each select accessed in the current database definitions and in the recommended
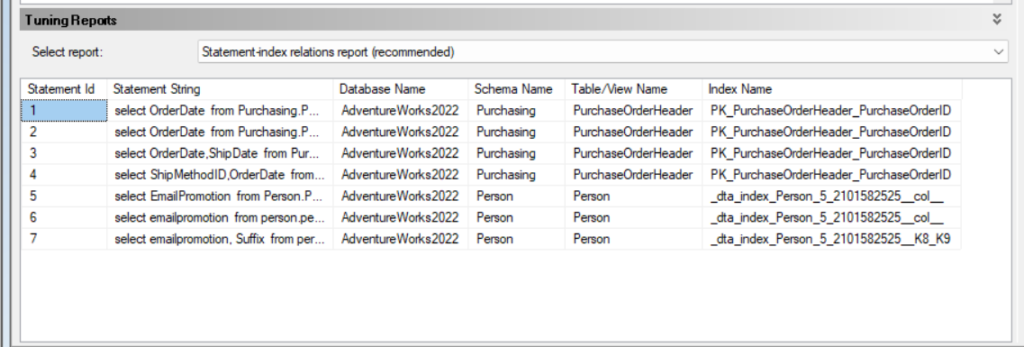
now here in the recommended we can see the index suggestion, we have two at the end, one for the 5 and 6, and 1 for seven
but we know that we should not create on any of them since none of them were selective as we saw in the previous blog
plus we know that one index could cover both if we did not use suffix in the where clause
but this was better than the missing_index DMOs since each of the statements needed her own index
here it is estimated that the use of an index on orderdate and shipdate is not good
and we don’t need 3 indexes for emailpromotion, it has a more holistic overview
also we only included 7 or 8 statements, so not a representative workload
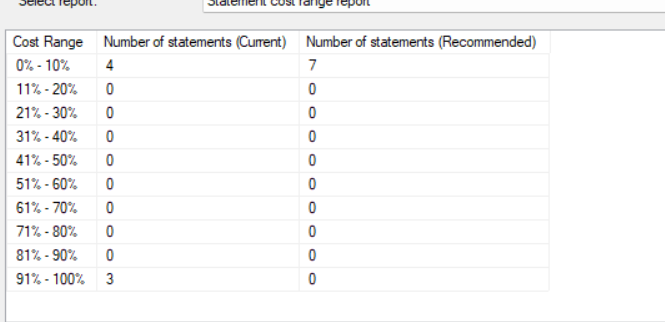
now in statement cost range, we can see what each of the statements would cost if executed
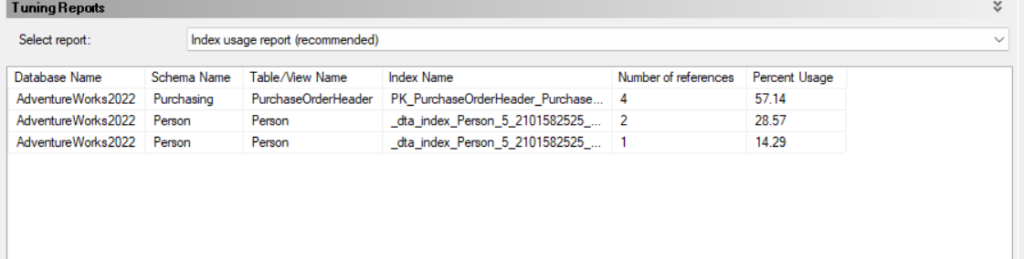
then we have the index usage reports current and recommended there we can see each index in the workload we specified and how often each is used and when we include the new indexes how often they will be used
then in the index details report:
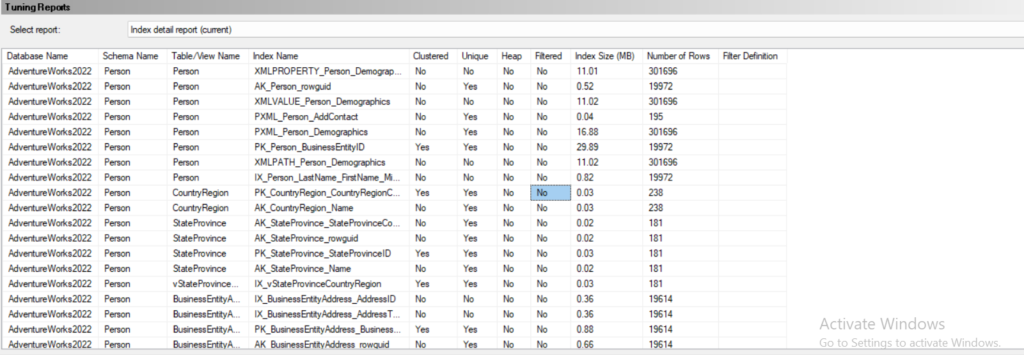
we can see a lot more details about the index type and their sizes

now since we included views, it went through them and did the same for them

now here it is self explanatory
in the database, table, and column access reports we can see how many times each event accessed each of these for example

now if we go back to recommendations:
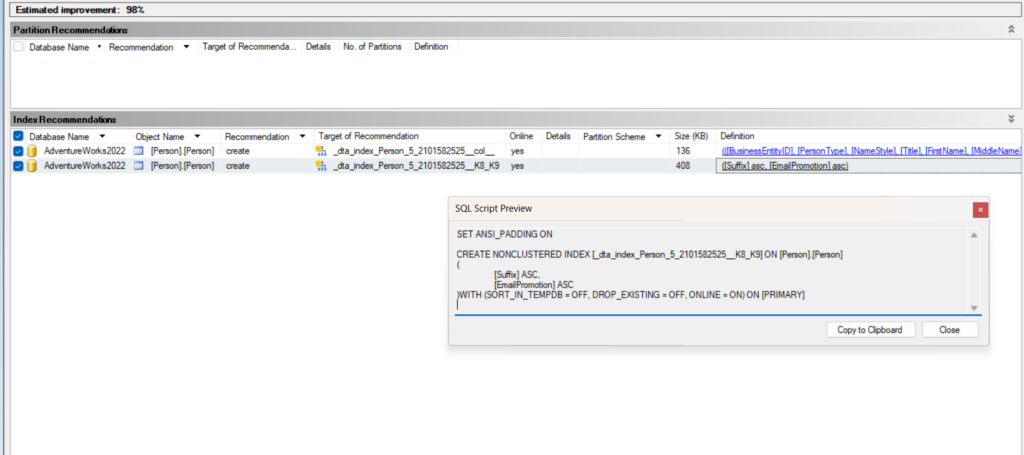
and click on one of the definitions we can see the script it would use for creating each of these structures here it suggested two indexes and one of them should be created like this:
SET ANSI_PADDING ON
CREATE NONCLUSTERED INDEX [_dta_index_Person_5_2101582525__K8_K9] ON [Person].[Person]
(
[Suffix] ASC,
[EmailPromotion] ASC
)WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = ON) ON [PRIMARY]
now the second one was:
Script failed for Index '_dta_index_Person_5_2101582525__col__'.
Cannot use the following options with a Columnstore index: PAD_INDEX ,STATISTICS_NORECOMPUTE ,SORT_IN_TEMPDB ,IGNORE_DUP_KEY ,ONLINE ,FILLFACTOR ,ALLOW_ROW_LOCKS and ALLOW_PAGE_LOCKS.
now if we re-create the session with no columnstore option and run it again:
CREATE NONCLUSTERED INDEX [_dta_index_Person_5_2101582525__K9] ON [Person].[Person]
(
[EmailPromotion] ASC
)WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = ON) ON [PRIMARY]
now here it is a duplicate and unnecessary since the first one covers both, plus the first one is composite, which is not a big deal, but if did not use suffix that often and modified our coding patterns we don’t have to include it
plus we lost one nonclustered suggestion, because we enabled an option in tuning, these are some of the few problems that are mentioned when dealing with DTA
that being said, it is a great tool for quick visits and not spending too much time on suggestions that we don’t need like
and it is a good starting point
now to apply the recommendations, click on actions at the top
and we
can apply it now or in the future
or we can save the suggested scripts like
now if we click on the scripts:
use [AdventureWorks2022]
go
SET ANSI_PADDING ON
go
CREATE NONCLUSTERED INDEX [_dta_index_Person_5_2101582525__K8_K9] ON [Person].[Person]
(
[Suffix] ASC,
[EmailPromotion] ASC
)WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = ON) ON [PRIMARY]
go
CREATE NONCLUSTERED INDEX [_dta_index_Person_5_2101582525__K9] ON [Person].[Person]
(
[EmailPromotion] ASC
)WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = ON) ON [PRIMARY]
go
we can see both scripts here
if clicked on the first session, it could not save it since the columnstore error was there
now here as you can see the names are not catchy, so we have to rename them according to our naming standards
and maybe we want to sort in tempdb or include suffix, or not create any of them
now here you can see how quick it is to optimize indexing using DTA, this is why a lot of veteran DBAs recommend it as a tool to help tuning and reduce efforts.
now we can use the command line to do the same things
but we are going to talk about that later in another blog series
for now, we are done here, see you in the next blog.