
Today we are going to introduce two internal tools that could design indexes for us in a quick manner, with little to no overhead
Missing indexes DMOs:
nowNowre we have 5 DMOs
while the optimizer is using the cardinality estimator and statistics, it would decide whether this query needs an index and then it sends this data to these DMOs
now this is on by default, we don’t need to enable it, it is with the optimizer, and basically cost-free
secondly, it is based on our production data, not a test load, so this is actually what we need
now they have some cons like:
it Itn only store information about 600 missing index groups, nothing more.
so once they are full, you can’t find any more information
even if it was on a similar query with a similar index
the second one, it only acts on a query basis, not a holistic overview of the whole system
and it does not care about the order of columns which definitely influences performance
to do that we have to test the suggestions
the third one is the inequality predicates in the query
the cost estimates would not be as good as the one with equality predicates
the fofourthis the type of indexes, it can not suggest indexes on the following:
clustered
XML
Spatial
columnstore
filtered indexes
and others
and whenever we do any metadata operation on the index like adding a column would drop all the missing indexes suggestions
since we have all these cons, we should not create every index that these DMOs suggest Wee should weigh each index’s overhead, its inserts and updates, and how much of a benefit we would get from creating it.
we should weigh each index’s overhead, its inserts and updates, and how much of a benefit we would get from creating it.
sys.dm_db_missing_index_details
now we are going to use adventureworks2022:
use AdventureWorks2022
select EmailPromotion
from Person.Person
where EmailPromotion = 2
or EmailPromotion = 0
Now we query the following:
select*
from sys.dm_db_missing_index_details
where object_id(N'person.person') = object_id
We would get:

- index_handle: is the surrogate key, the clustered index of the DMV here it is one since it is the first suggestion since the start of the server
- database_id
- object_id
- equEqualitylumns: if we had an equality predicate we would get one for example:
select emailpromotion
from person.person
where emailpromotion = 1
Then DMV again:

You can see here we have in an equality predicate columns
obviously, both queries could be server by the same index but since we did them separately suggested another one with the same columns
it suggested another one with the same columns
this is why we should not follow every suggestion, but judge each one and combine them in one or two indexes,
so if we query with ‘=’ we would get it the equality columns filled
now for included columns we can do the following:
select emailpromotion, Suffix
from person.person
where emailpromotion = 1
and Suffix = 'Jr.'
Then DMV like:
select*
from sys.dm_db_missing_index_details
where object_id(N'person.person') = object_id

Now, suffix is full of nulls, and emailpromotion is full of duplicates, so both are not a good candidate for indexing, for now, we see their statistics by:
select*
from sys.stats
where object_id = OBJECT_ID(N'person.person')
dbcc show_statistics('person.person',_WA_Sys_00000009_7D439ABD)
dbcc show_statistics('person.person',_WA_Sys_00000008_7D439ABD)
And we get the following:
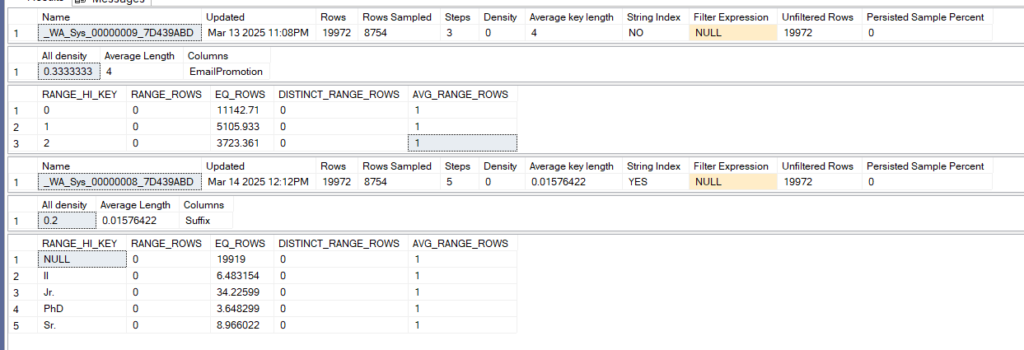
as you can see suffix is full of nulls, but it is more selective in the other columns so we could create a filtered index on it
on the other hand, EmailPromotion, has 3 values, all of them which duplicates
so neither should be indexed
but the missing indexes DMVs suggested creating 4 indexes so far, so we would end up with redundant highly fragmented non-selective poor indexes
that is why it is suggestions, not ready prescriptions
the included column would help us prevent a key-lookup like we said before if the index was to be created
sys.dm_db_missing_index_columns(DMF)
now here we have to pass the index handle like:
select *
FROM sys.dm_db_missing_index_details AS mid
CROSS APPLY sys.dm_db_missing_index_columns (mid.index_handle)
where object_id = OBJECT_ID(N'person.person')
we would get:

or
select [statement],column_id,column_name,column_usage
FROM sys.dm_db_missing_index_details AS mid
CROSS APPLY sys.dm_db_missing_index_columns (mid.index_handle)
where object_id = OBJECT_ID(N'person.person')
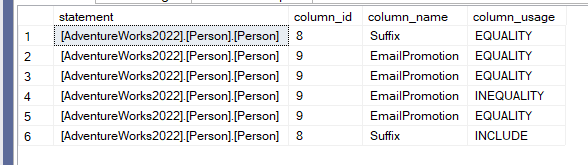
so here we can see the table, the column_id inside the DMF, the name of the column, and where it was used, and how should we create it if the index were to be created
so in the first form we can see that we have multiple suggested indexes, but all have the same columns ids, thus suggesting, we should look into it before applying the changes, test before in Dev and then Production.
sys.dm_db_missing_index_groups
now if we do the following:
select *
from sys.dm_db_missing_index_groups g inner join sys.dm_db_missing_index_details d
on g.index_handle = d.index_handle
and d.object_id = OBJECT_ID(N'person.person')

or
select g.*
from sys.dm_db_missing_index_groups g inner join sys.dm_db_missing_index_details d
on g.index_handle = d.index_handle
and d.object_id = OBJECT_ID(N'person.person')
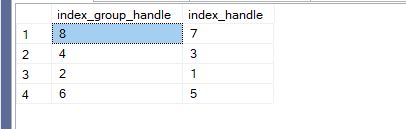
so here we have index_group_handle or id, clustered key as an extra
it always has one index not many
sys.dm_db_index_missing_index_group_stats
if we:
select gs.*
from sys.dm_db_missing_index_group_stats gs inner join sys.dm_db_missing_index_groups g
on gs.group_handle = g.index_group_handle
inner join sys.dm_db_missing_index_details d
on d.index_handle = g.index_handle
where d.object_id = OBJECT_ID(N'person.person')
we can get:

now here we have:
- group_handle
- how many times the query has been compiled for this specific index recommendations, how many queries tried to execute this with a unique execution plan, or it recompiled it
- how many seeks and scan from user or system( like operational stats) would benefit from this and their timestamps
- avg_user_impact: this query performance would increase by this percentage if this index was created
- avg_total_user_cost: the amount of cost in terms of percentile that could be reduced by indexing like this
or we could query it like this:
select*
from sys.dm_db_missing_index_groups g inner join sys.dm_db_missing_index_details d
on d.index_handle =g.index_handle
inner join sys.dm_db_missing_index_group_stats gs
on g.index_group_handle = gs.group_handle
and we would get the group first, then the index, then the seeks, we can modify it however we want
sys.dm_db_missing_index_group_stats_query
select*
from sys.dm_db_missing_index_groups g inner join sys.dm_db_missing_index_details d
on d.index_handle =g.index_handle
inner join sys.dm_db_missing_index_group_stats_query gsq
on g.index_group_handle = gsq.group_handle
with this we get these extras, which could help us pinpoint the queries that use these indexes, and compare them to the most executed queries:

for example (reproduced from the docs):
select top 10
substring
(
sql_text.text,
gsq.last_statement_start_offset / 2 + 1,
(
CASE gsq.last_statement_start_offset
WHEN -1 THEN DATALENGTH(sql_text.text)
ELSE gsq.last_statement_end_offset
END - gsq.last_statement_start_offset
) / 2 + 1
),
gsq.*
from sys.dm_db_missing_index_group_stats_query AS gsq
cross apply sys.dm_exec_sql_text(gsq.last_sql_handle) AS sql_text
ORDER BY gsq.avg_total_user_cost * gsq.avg_user_impact * (gsq.user_seeks + gsq.user_scans) DESC;
we would get the following:

now here we can see the text of each of the queries that we had the suggestion for,
now this is a fairly generic code and we explained it in troubleshooting blocking and deadlocks, for more information you can go there.
Using the DMOs: A Case
now if we do the following:
go
select OrderDate
from Purchasing.PurchaseOrderHeader
where OrderDate = '2013-04-25 00:00:00.000'
and ShipDate = '2013-05-04 00:00:00.000'
go
select OrderDate
from Purchasing.PurchaseOrderHeader
where OrderDate between '2011-04-16 00:00:00.000' and '2011-12-14 00:00:00.000'
and ShipDate between '2011-04-25 00:00:00.000' and '2011-12-23 00:00:00.000'
go
select OrderDate,ShipDate
from Purchasing.PurchaseOrderHeader
where orderdate between '2011-04-16 00:00:00.000' and '2011-12-14 00:00:00.000'
go
select ShipMethodID,OrderDate
from Purchasing.PurchaseOrderHeader
where orderdate between '2011-04-16 00:00:00.000' and '2011-12-14 00:00:00.000'
and
ShipDate between '2011-04-25 00:00:00.000' and '2011-12-23 00:00:00.000'
go
now here we selected from nonselective columns all over, none of them have that many unique values, but together they might have some selectivity, but without the clustered index, maintaining them would be an issue
now all of them don’t have any indexes and all would produce index scans like:

the green thing out there is the missing index suggestion, now the graphical plan can only display one of them, but if we click on show the plan XML by right click on the plan the clicking on show plan XML we might get more, now we could text search in there using Ctrl + F:
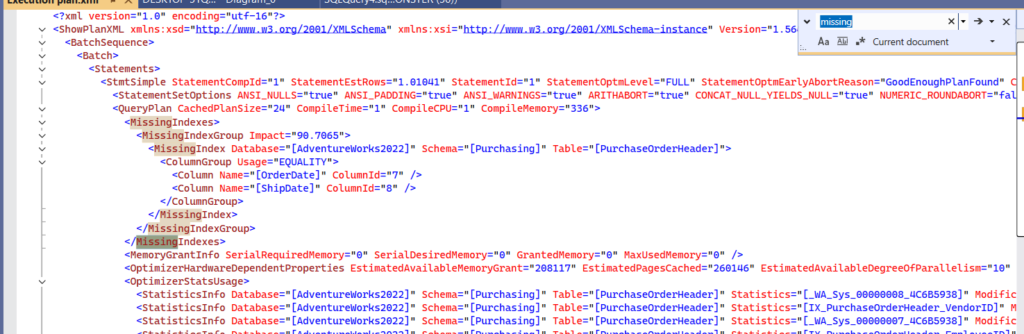
now here it shows the database, what kind of predicate was used, and how should we create it,
the impact 90.7….
now this one estimates how much of query execution time this might reduce in terms of percentile
now this is only for the first query not everything
but if we had these queries accumulated, the impact would be across all queries
and if just want to create that index we can just right click on the execution plan, then click on missing index details like:
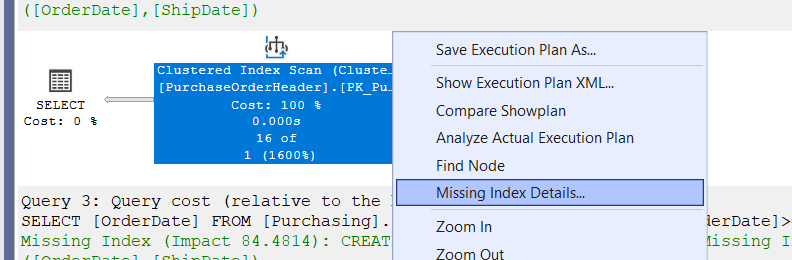
/*
Missing Index Details from SQLQuery4.sql - device.AdventureWorks2022 (device (56))
The Query Processor estimates that implementing the following index could improve the query cost by 90.7065%.
*/
/*
USE [AdventureWorks2022]
GO
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>]
ON [Purchasing].[PurchaseOrderHeader] ([OrderDate],[ShipDate])
GO
*/
now if we wanted to see more details behind this(Edward Pollack and Jason Strate):
use adventureworks2022
select
db_name(d.database_id) as [database],
object_name(d.object_id,d.database_id) as [table],
d.equality_columns,
d.inequality_columns,
d.included_columns,
(gs.user_seeks+gs.user_scans)*gs.avg_user_impact as impact,
gs.avg_total_user_cost*(gs.avg_user_impact/100)*(gs.user_seeks+gs.user_scans) as score,
gs.user_seeks,
gs.user_scans
from sys.dm_db_missing_index_details d
inner join sys.dm_db_missing_index_groups g on
d.index_handle= g.index_handle
inner join sys.dm_db_missing_index_group_stats gs on
gs.group_handle = g.index_group_handle
where
db_name(d.database_id)='adventureWorks2022'
and
d.object_id = object_id(N'Purchasing.PurchaseOrderHeader')
order by
gs.avg_total_user_cost*(gs.avg_user_impact/100)*(gs.user_seeks + gs.user_scans) desc
now the impact here is universal, just like the one in the table
and the score here is query specific
now the following output:

now here each has similar impacts, the seek amount would affect the results so if we run of the queries again we would skew it, but since they are similar, we could make some conclusions
first we should look at how many queries need shipmethodid, since it was seeked once so maybe we could cover the overhead of key-lookup
on the other hand if we include it we could increase performance, but we would have the index overhead
now most of them want the orderdate and shipdate
now whether the second should be a composite key, depends on how do we seek
now if we use it in the where clause a lot, we should, so if it was a filtering criteria we might add it
it was here
on the other hand if we only selected it, then it could be included
now at what order should we create the composite index or the included column, depends on our workloads and the selectivity of both
and what kind of queries do we use
if we don’t specify shipdate without orderdate that much, then we might choose orderdate
on the other hand, if orderdate was not that selective, we might need to query it with shipdate everytime so we could decrease index overhead and increase seek effectiveness
now here since we mostly used orderdate first
as inequality or equality predicate, it is safe to say that it should be the leftmost
and since we never filtered based on shipmethodid, we could just include it
and we would cover all the suggestions, keeping in mind that not all suggestions should be applied
now we can write an index creation ddl here
or we can make the tiger toolbox index_creation script do it for us
it is provided by Microsoft
and it only generates statements
the link is here
and with that we finish our talk about missing index DMOs