
now in part 13, we stopped at comparing performance hits with NEWID() and ever-increasing keys,
now sometimes the developers might decide to choose NEWID(), today we are going to discuss ways to enhance performance using it as a clustered key
after that, we are going to introduce some design considerations while dealing with nonclustered indexes.
NEWSEQUENTIALID(): Guaranteeing uniqueness across databases
now since developers use it to generate unique values across the application, the main issue was the values were random, what happens if we generated non-random values, meaning newsequentialid() generates the next value in line, then at some point, when we shut down windows and restart, it would start generating from a lower range, but it still unique,
so it generates sequential values until the restart
so we are golden most of the time
but, this has a security concern,
you can guess the next value most of the time, later in this blog we will talk about this
for more information on it check out the docs
now let’s compare the fragmentation of both:
USE TESTDATABASE
create table newid_demo(
UserID uniqueidentifier not null default newid(),
purchase_amount int);
----
create clustered index ix_userid on newid_demo(userid)
with( fillfactor = 100, pad_index =on);
-----------------
create table newsequentialid_demo(
UserID uniqueidentifier not null default newsequentialid(),
purchase_amount int);
----
create clustered index ix_userid on newsequentialid_demo(userid)
with( fillfactor = 100, pad_index =on);
So we create the tables with indexes, now let’s insert with, then physical stats at the end:
----------------inserts
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into newid_demo(purchase_amount)
select id*20
from ids;
-----
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into newsequentialid_demo(purchase_amount)
select id*20
from ids;
and physical:
-----physical
select
index_level,
page_count,
avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.newid_demo'),1,null,'Detailed')
---
select
index_level,
page_count,
avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.newsequentialid_demo'),1,null,'Detailed')
The output was like:
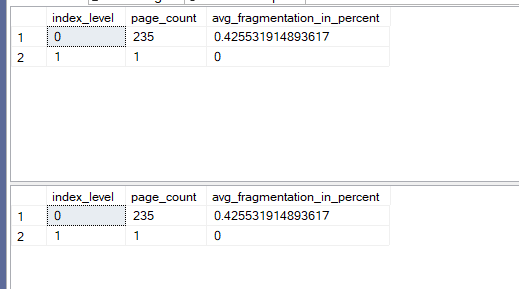
Now if we insert again with physical:
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into newid_demo(purchase_amount)
select id*20
from ids;
-----
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into newsequentialid_demo(purchase_amount)
select id*20
from ids;
-----physical
select
index_level,
page_count,
avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.newid_demo'),1,null,'Detailed')
---
select
index_level,
page_count,
avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.newsequentialid_demo'),1,null,'Detailed')
The output was like:
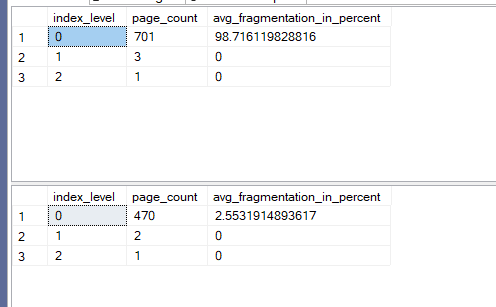
Now as you can see no fragmentation
Using Composite key as an alternative to guarantee uniqueness
now instead of creating just one key for the clustered, we can use the second key as identity or sequence, thus guaranteeing uniqueness(for more on composite keys check out our blog)
for example:
use testdatabase
go
create table unique_demo_composite(
id_1 int not null,
id_2 int identity not null
)
create clustered index ix_unique_demo_composite_ci_id_1_id_2 on
dbo.unique_demo_composite(id_1,id_2);
go
insert into dbo.unique_demo_composite(id_1) values(1)
go 50
select*
from unique_demo_composite
We can see:
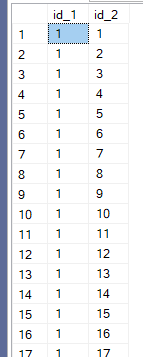
It is always unique
Security concern solution: creating a calculated column on newid() using checksum
now sometimes you have to use newid() as a security token
but indexing such column is pointless or at least costly and introduces a lot of blocking,
one way to get around it is to get around it is to create a calculated column using checksum
now this column will be:
fragmented
and non-unique
but it will be more compact
and the second issue could be solved by creating a surrogate key like identity(1,1)
which would be unique and asking for both in the where clause
For example:
use testdatabase
create table checksum_newid_demo(
id_surrogate int identity(1,1) not null,
id_newid uniqueidentifier not null
constraint default_checksum_newid_demo_id_newid
default newid(),
id_newid_checksum as checksum(id_newid)
);
create clustered index ix_cheksum_newid_demo_id_surrogate_CI on
dbo.checksum_newid_demo(id_surrogate);
create nonclustered index ix_id_newid_checksum_nci on
dbo.checksum_newid_demo(id_newid_checksum);
Now let’s insert some values with physical afterward:
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select ROW_NUMBER() over(order by (select null)) from n5)
insert into dbo.checksum_newid_demo(col1)
select id
from ids
---- physical
select
index_level,
page_count,
avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.checksum_newid_demo'),2,null,'Detailed')
The output was like:
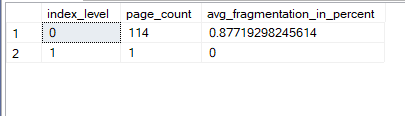
Newly formed now if we insert again with physical:
--- let's insert again
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select ROW_NUMBER() over(order by (select null)) from n5)
insert into dbo.checksum_newid_demo(col1)
select id
from ids
--- physical again
select
index_level,
page_count,
avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),OBJECT_ID(N'dbo.checksum_newid_demo'),2,null,'Detailed')
The output was like:
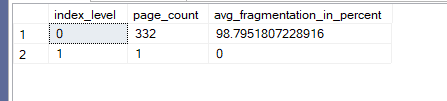
Now this is way too fragmented but, it is way too smaller than the clustered index that would be on newid() and it is unique if we query like this:
select*
from dbo.checksum_newid_demo
where id_surrogate = 1
and id_newid_checksum = -1833764562
and with that, we finish our small talk on clustered index design
Nonclustered index design index intersection(Dmitri Korotkevitch)
the main thing here, should I have multiple indexes that cover every query, or small single column indexes that covers most of my needs and gets slow sometimes
there is no specific rule we need to test
if the index’s selectivity is high, and a small number of rows will be returned, then a key-lookup would be sufficient, since we don’t need that many rows, going through the root and intermediate levels of the clustered would not be that expensive
but once the row number increases and the selectivity decreases, it would choose the scan, at that point, we would need a new covering nonclustered
now let’s try that:
we will create a table that has 4 different columns each with a different amount of selectivity
and create 4 separate nonclustered indexes on each
And watch what the optimizer would do when we try each as a predicate:
use testdatabase
create table demo_index_int(
id int not null,
col1 int not null,
col2 int not null,
col3 int not null,
col4 int not null
);
create unique clustered index ix_demo_index_int_id on demo_index_int(id);
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into dbo.demo_index_int(id,col1,col2,col3,col4)
select id,id%50,id%100,id%150,id%200
from ids;
now here it would generate the same values, as remainder every 50 in the first
and 100 in the second
and 150 in the third
and 200 at 4th
now if we select like:
select*
from dbo.demo_index_int
We can see:
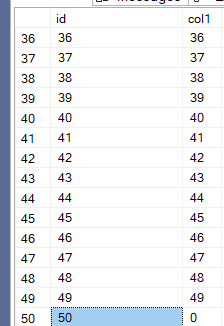
for col1, and:
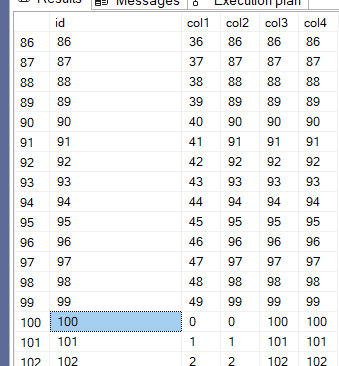
for col2 and the same goes for the other two,
so there are a lot of duplicates at the first and it decreases going up since there are more distinct values,
Now if we create nonclustered indexes like:
create nonclustered index ix_demo_index_int_col1 on dbo.demo_index_int(col1);
create nonclustered index ix_demo_index_int_col2 on dbo.demo_index_int(col2);
create nonclustered index ix_demo_index_int_col3 on dbo.demo_index_int(col3);
create nonclustered index ix_demo_index_int_col4 on dbo.demo_index_int(col4);
Now if we check the dbcc show statistics for each like:
dbcc show_statistics('dbo.demo_index_int',ix_demo_index_int_col1);
dbcc show_statistics('dbo.demo_index_int',ix_demo_index_int_col2);
dbcc show_statistics('dbo.demo_index_int',ix_demo_index_int_col3);
dbcc show_statistics('dbo.demo_index_int',ix_demo_index_int_col4);



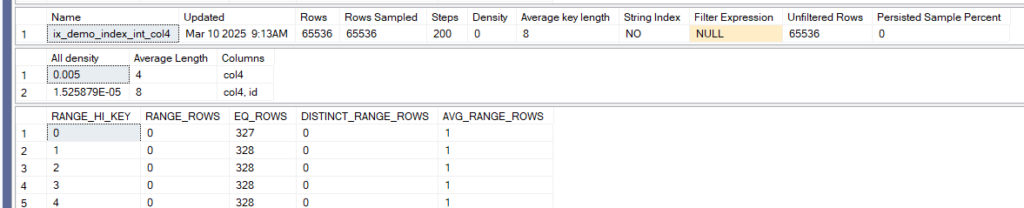
now the only one that had the whole histogram 200 steps used is the last one
so the only one that was selective enough to use the whole thing is the last one
so from that, only we can decide that the last one is the most selective
plus from the eq_rows 328 is lower than the others
and all_density = 1/ n where n is the number of distinct rows, so the more selective is the index, the lower the value
so in the last case 1/200 since we have only 200 distinct values that keep on generating = 0.005
now they are all unique with id, since it is unique, ever-increasing, and follows the standards we talked about like tight, static, etc.
for more details on statistics check out our blog
now if we select using the 4 predicates, so we could join the 4 indexes:
SELECT id
FROM demo_index_int
WHERE col1 = 1
AND col2 = 1
AND col3 = 1
AND col4 = 1
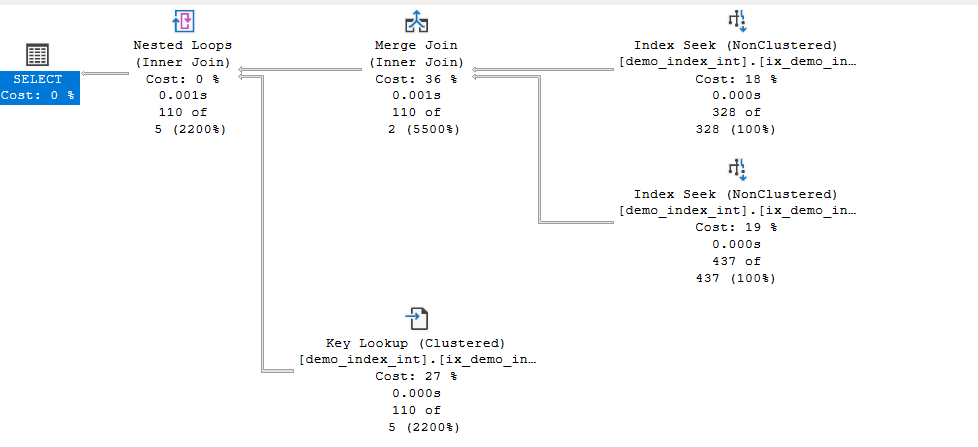
now how did it get this plan,
now the estimates for the index seek were accurate since it just looked for histogram steps
took the value
since we did not have many distinct values, but at the same time we could get an accurate estimate of the values
it used it
what about the others
but the main thing is that with seeks it had to get 1311 rows from col1 and 656 from the col2
which is way more than 2 so instead it went and looked up the estimated 2 rows as key lookup
way less than that it just got 2 (110 in our case) after they matched the id of the merge rows
using the nested loop row by row
it went and looked if they matched the first and the second predicates col1= 1 and col2 = 1
now if we set statistics io on like:
go
set statistics io on
go
select id
from demo_index_int
where col1 =1 and col2 =1 and col3 =1 and col4 = 1
go
set statistics io off
We would get:
(110 rows affected)
Table 'demo_index_int'. Scan count 2, logical reads 226,
and time on :
go
set statistics time on
go
select id
from demo_index_int
where col1 =1 and col2 =1 and col3 =1 and col4 = 1
go
set statistics time off
We would get:
(1 row affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 46 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Now if we create an index that includes all of these like:
create nonclustered index ix_demo_index_int_col4_inc_col2_col3_col1
on demo_index_int(col4)
include(col1,col2,col3)
Now if we select:
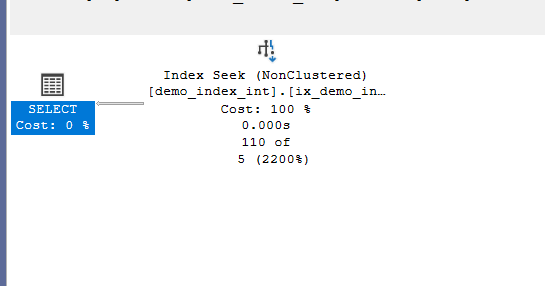
We get one seek and with statistics time on:
go
set statistics time on
go
select id
from demo_index_int
where col1 =1 and col2 =1 and col3 =1 and col4 = 1
go
set statistics time off
The output was like:
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 42 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
and io on:
Table 'demo_index_int'. Scan count 1, logical reads 3,
So the number of reads is way too decreased, and we had some decrease in the CPU time, possibly due to capturing the execution plan now I am going to turn it off and capture time again:
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
And drop the new index and select again:
drop index ix_demo_index_int_col4_inc_col2_col3_col1
on demo_index_int
and the output was like:
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 2 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
so it decreased twice or more or less but the point is that it is less with the covering index, plus we have no reads compared to the original one
so it is way more efficient
the place where we join indexes is called index intersection
and we could use it sometimes
but would increase performance by a covering one
now this depends on the workload, since maintaining an index means update and storage overhead
on the other hand, if this query is critical and the waits can not be tolerated we should create one
and with that, we finish our small talk in this blog, catch you in the next one
[…] as we introduced it before, NEWID() function introduces a lot of fragmentation if indexed, since there is no way to know what […]