
now we talked about how to defragment individual indexes, but this process is too manual and takes a lot of monitoring, how could we automate that:
- maintenance plans
- scripts like Ola Hallengren’s
Maintenance plans
deep down they are an interface to internal SQL agent job
but with a very simplified drop-down interface
now here we are going to use the SSMS maintenance plan interface:
first in the object explorer:
expand management
after that right click on maintenance plans
after that click new maintenance plan
, now if you want you can click on the wizard to make you walk through, but it always has some issues like the whole thing not expanding, you can walk through with us instead if you like
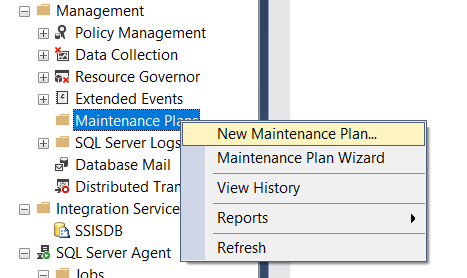
after that we have to name our session, let’s call it test_index_reorganize_rebuild
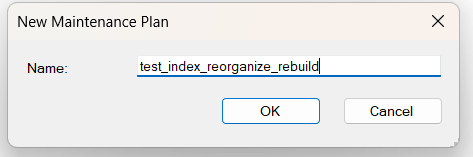
now here we have 3 boxes:
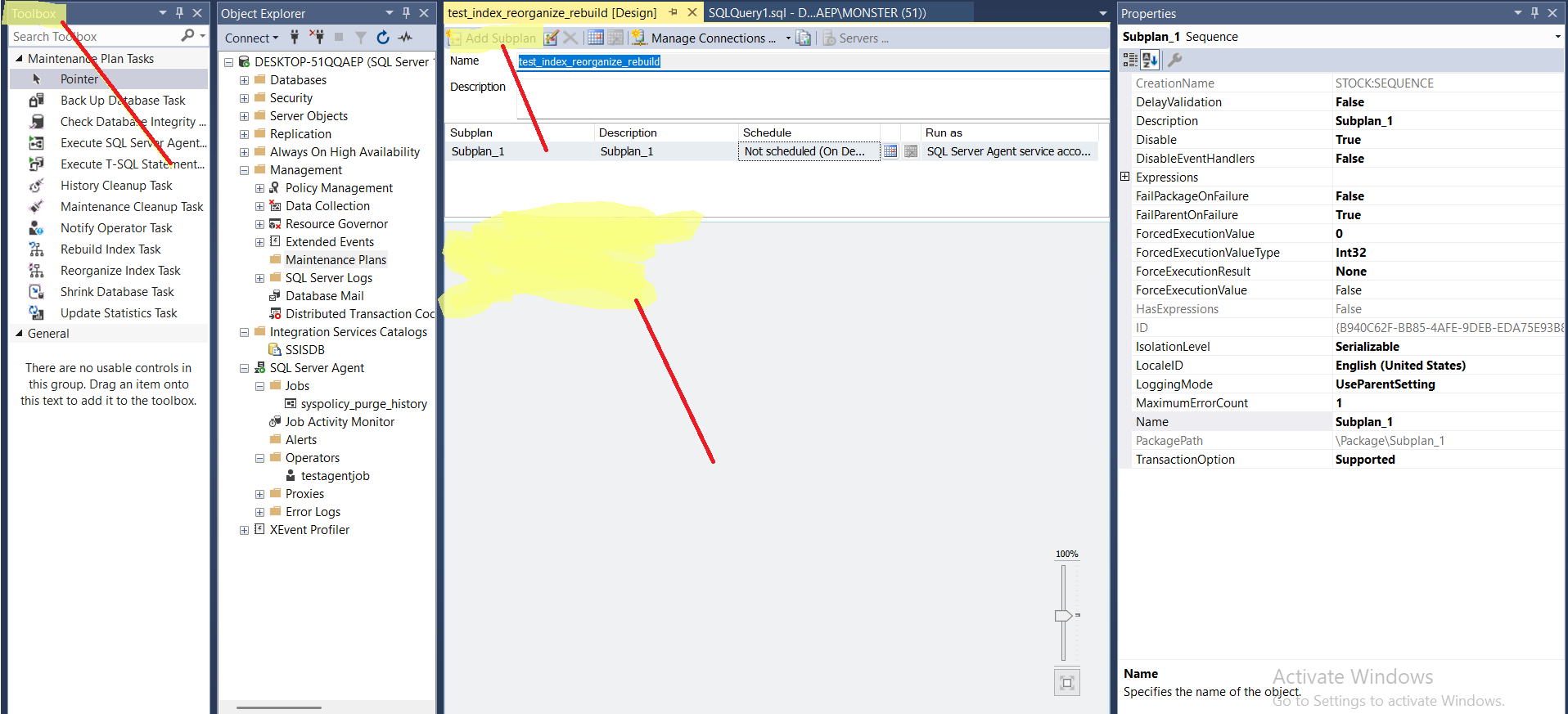
at the top left we have the toolbox, it contains the built-in tasks that you can assign to a specific plan click on index rebuild, reorganize.
in the middle we see the design interface, once you click on anything in the toolbox it will be here
and we have the Subplan list at the top
now here we see our tasks
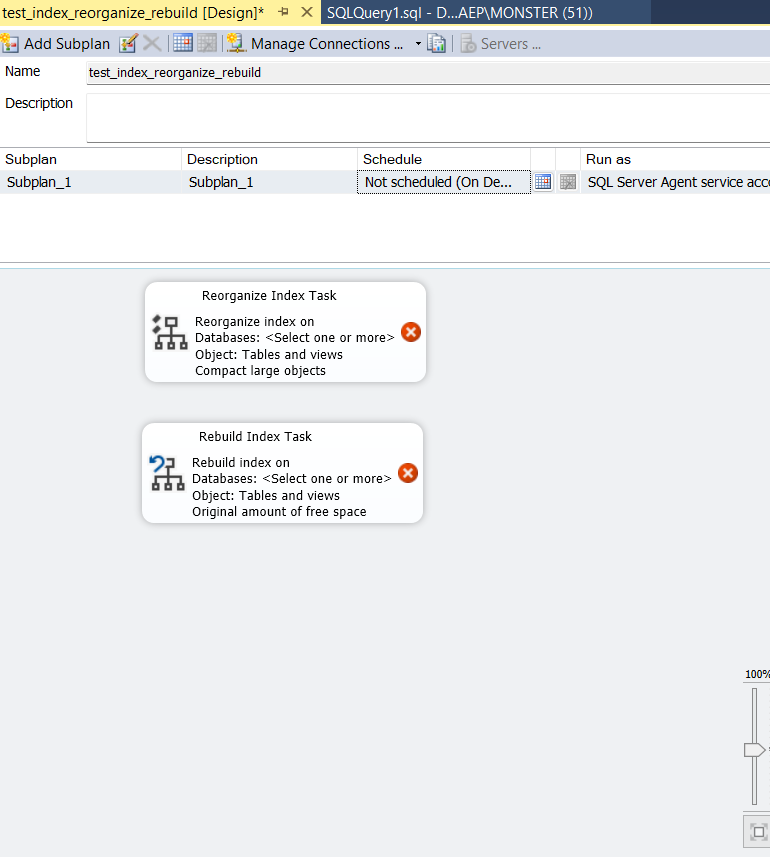
now let’s look inside the reorganize:
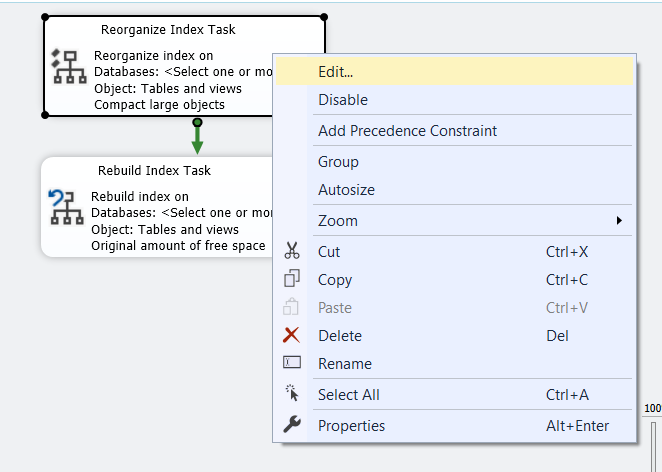
now right click then edit:
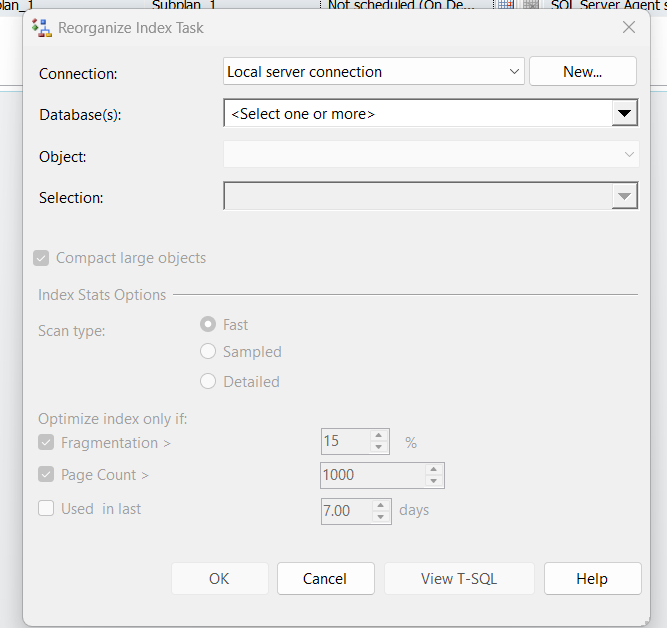
so we have:
- the type of connection
- database what kinds, do you want it for all databases, system databases, user databases, specific database
- object: table, view, or table and a view
- selection: now if you don’t choose tables and views in the previous drop-down list, here you can specify what object you want to include in the task like a specific table or a view
- compact_large_objects: now since unless we specify this option SQL server will not reclaim the LOB space we should specify it
- scan type: what kind of statistics do you want: fast, sampled, or detailed, why do we have it here? stats don’t get updated with reorganize only with rebuild
- optimize index only if: do the task only if:
- we are going to choose anything less that 30
- page count 1000, but since our tables are small, we are going to use 1
- used in last: now some indexes might not be used at all, or only used monthly, whether you should reorganize them or not depends on your workload but since we don’t care here we are not going to specify it
now we are going to choose test database:
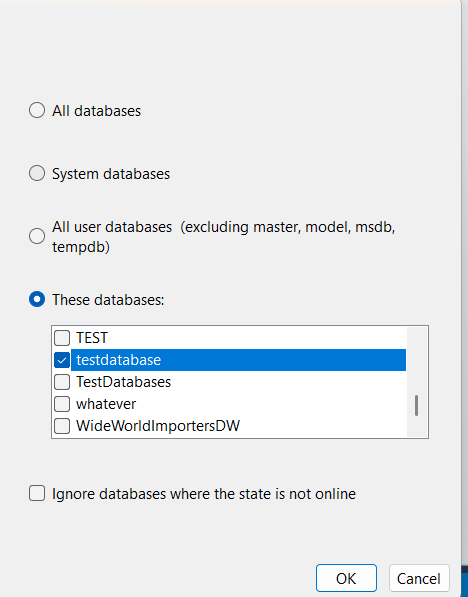
now we are just going to show the options in the selection if we choose table:

the rest of our options:
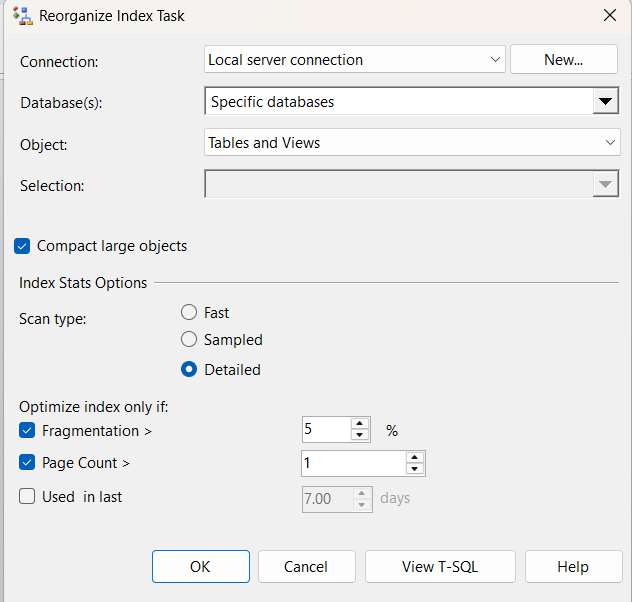
and if we wanted to view the script itself:
use [master];
GO
USE [testdatabase]
GO
ALTER INDEX [ix_idd] ON [dbo].[forwarding] REORGANIZE WITH ( LOB_COMPACTION = ON )
GO
USE [testdatabase]
GO
ALTER INDEX [ix_col1] ON [dbo].[frag_demo] REORGANIZE WITH ( LOB_COMPACTION = ON )
GO
USE [testdatabase]
GO
ALTER INDEX [ix_userid] ON [dbo].[new_id_demo] REORGANIZE WITH ( LOB_COMPACTION = ON )
GO
USE [testdatabase]
GO
ALTER INDEX [ix_userid2] ON [dbo].[new_id_demo_2] REORGANIZE WITH ( LOB_COMPACTION = ON )
GO
USE [testdatabase]
GO
ALTER INDEX [ix_uf_id] ON [dbo].[updates_frag] REORGANIZE WITH ( LOB_COMPACTION = ON )
GO
Here, as you can see it shows the action on each one.
now let’s take a look at the index rebuild task
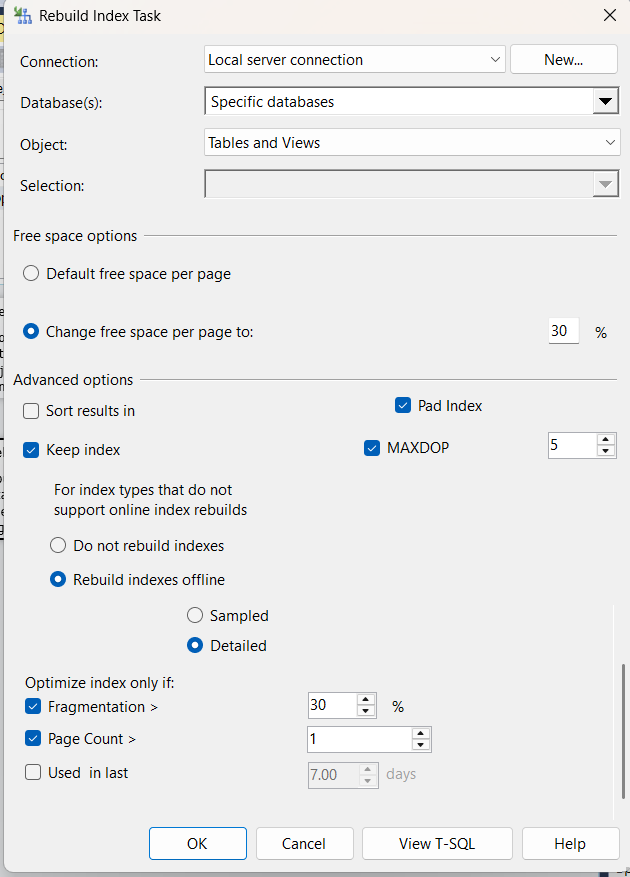
now here we have:
- connection
- database
- object
- selection all the same
- but what it comes to fill factor or default free space, here we have a new option
- now if free space is 30 percent then fill factor is 70 since the we are going to fill it up to 70 percent
- default uses the server default or we can specify it
- sort results in(tempdb) whether we have option ALTER INDEX SORT_IN_TEMPD = ON
- MAXDOP:
- keep index online while index: whether we want the option ALTER INDEX ONLINE = ON
- Then after that we have an option either skip or build offline
- then after that it is all the same
now if we script:
use [master];
GO
USE [testdatabase]
GO
ALTER INDEX [ix_delete] ON [dbo].[delete_frag]
REBUILD PARTITION = ALL WITH
(PAD_INDEX = ON,
STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF,
ONLINE = ON
(WAIT_AT_LOW_PRIORITY (MAX_DURATION = 0 MINUTES, ABORT_AFTER_WAIT = NONE)),
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, MAXDOP = 5, FILLFACTOR = 70)
GO
USE [testdatabase]
---- and it goes on
now here we can see the options of the index rebuild, for example statistics_norcompute says whether we want auto generate stats or not
now we have to schedule this thing:
nothing much about scheduling
and we have to specify an operator to send emails to:
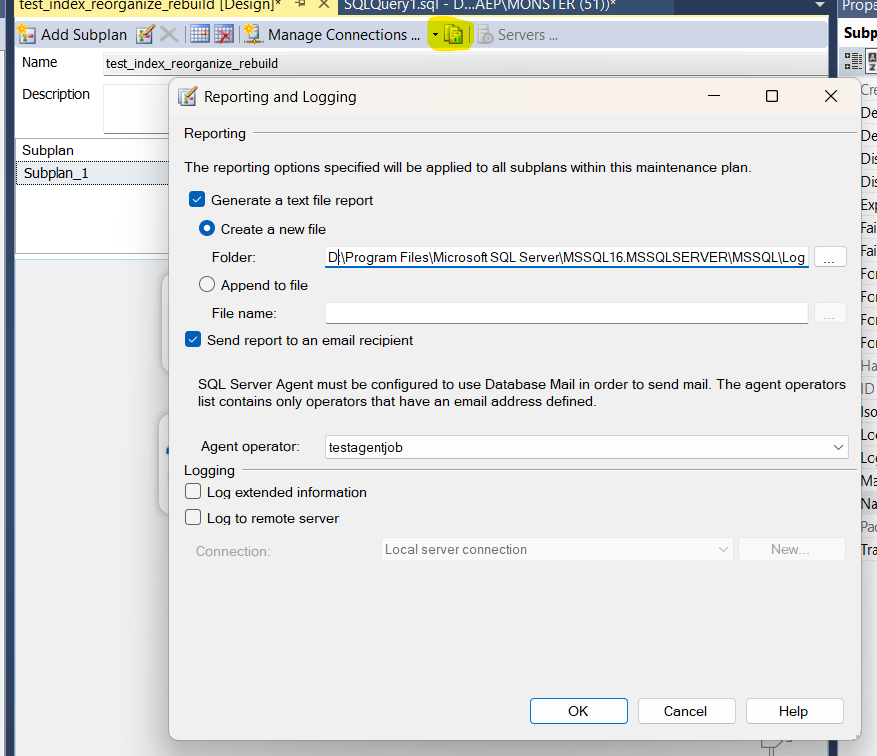
at the top click on reporting and logging button, then specify the operator you want
now if we did not have an operator, in object explorer we can create one
by expanding SQL server agent, operators, right click on New Operator
this would pop up:
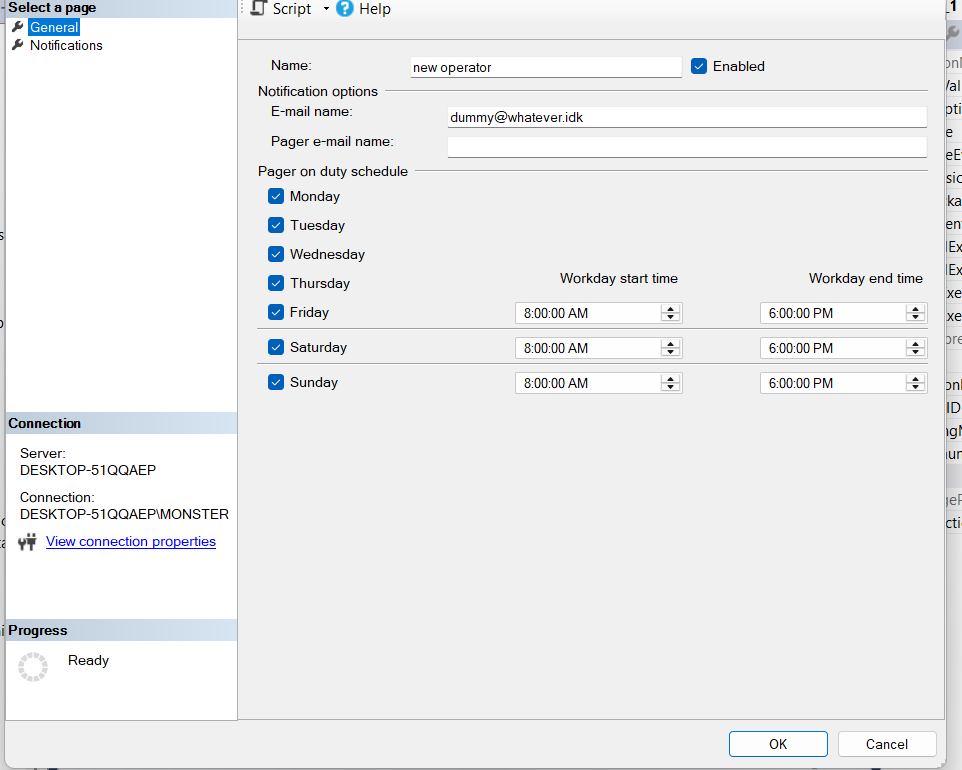
now if we script it:
USE [msdb]
GO
/****** Object: Operator [new operator] Script Date: 3/6/2025 4:22:37 PM ******/
EXEC msdb.dbo.sp_add_operator @name=N'new operator',
@enabled=1,
@weekday_pager_start_time=80000,
@weekday_pager_end_time=180000,
@saturday_pager_start_time=80000,
@saturday_pager_end_time=180000,
@sunday_pager_start_time=80000,
@sunday_pager_end_time=180000,
@pager_days=127,
@email_address=N'dummy@whatever.idk',
@category_name=N'[Uncategorized]'
GO
then we connect it
or we can create our own scripts:
defragmentation using T-SQL
now maintenance plans as you saw have limited functionality, so if you want something more robust, like for example, allows you to choose which indexes need to be rebuild, it would be way better at a relatively high scale
if we want details we can create our own script or we can use Ola Hallengren’s scripts
now we have specific guidelines that everybody follows:
- reorganize everything with fragmentation less than 30 percent
- rebuild the above that
- ignore anything below 1000 pages
- if we have enterprise, and we need to access the data while doing index rebuild, we should enable the online option,
- if we are rebuilding the clustered index, might as well rebuild the whole thing, since it would on its own rebuild it without telling us
now what does a defragmentation script consist of:
collect data,
determine what indexes to rebuild, reorganize
build the defragmentation command
(this was inspired by Edward Pollack, Jason Strate, and Ola Hallengeren)
so let’s create our script:
DECLARE @max_fragmentation tinyint =30,
@minimun_pages smallint =1,/*now here we can decalare it more but we
choose not to so we could see some action otherwise
smalltables under 1000 pages might not have any benefit from this*/
@SQL nvarchar(max), -- for dynamic sql
@object_name nvarchar(350),-- table or a view
@index_name nvarchar(350),--- you know
@current_fragmentation decimal(9,6)
/*before we declared cursor variables so we could process
the information from the temp table, now we will populate that
from sys.dm_db_index_physical_stats
and from there it would loop through each value
feed it to anothe stuff
then it would or would not generate the
T-SQL we want
*/
declare @frag_dm_db_stuff_table table/*now here we will create our intermediate result set
so we could feed it to our variables*/
(
schema_name sysname,
table_name sysname,
object_id int,
index_name sysname,
index_id int,
page_count bigint,
avg_fragmentation_in_percent float,
avg_page_space_used_in_percent float,
type_desc varchar(260)
)
/*now here we are going to insert the data from sys.dm_db_index_physical stats
to our @frag_dm_db_stuff_table*/
insert into @frag_dm_db_stuff_table
select
s.name as schema_name,
t.name as table_name,
t.object_id,
i.name as index_name,
i.index_id,
i_p.page_count,
i_p.avg_fragmentation_in_percent,
i_p.avg_page_space_used_in_percent,
i.type_desc
from sys.dm_db_index_physical_stats(db_id(),null,null,null,'detailed') as i_p/*now obviously here
we don't need to do the detailed, but we choose to include it */
inner join sys.tables t on t.object_id = i_p.object_id
inner join sys.schemas s on s.schema_id = t.schema_id--- now no schema id in i_p so we have to use table
inner join sys.indexes i on i.object_id = i_p.object_id and i.index_id=i_p.index_id
where i_p.index_id>0
and i_p.avg_fragmentation_in_percent>0
and alloc_unit_type_desc = 'IN_ROW_DATA'
/*now here we excluded heaps
and no fragmentation whatsoever
and LOB with columns in indexes with include since they can't be build online*/
--- now we are going to cursor
DECLARE FRAGMENTED_INDEX CURSOR LOCAL FAST_FORWARD FOR
--- NOW HERE LOCAL MEANS TO THE BATCH OR STORED PROCEDURE NOT GLOBAL TO EVERYBODY
--- UNTIL THE SESSION CLOSES
---FAST_FORWARD IT CAN MODIFY ONLY IN THE FORWARD DIRECTION, NO GOING BACK
---- FOR MEANS, WHAT ROWS SHOULD I FETCH IN THIS LOCAL CURSOR
--- NOW HERE WE ARE GOING TO DEFINE OUR SELECT STATMENT FROM OUR TEMP TABLE
select QUOTENAME(a.schema_name)+'.'+QUOTENAME(a.table_name),
case when a.type_desc = 'CLUSTERED' THEN ' ALL '
else QUOTENAME(a.index_name) end,
a.avg_fragmentation_in_percent
from @frag_dm_db_stuff_table as a
LEFT JOIN @frag_dm_db_stuff_table as b on a.object_id = b.object_id
and b.index_id =1
where ( a.type_desc ='CLUSTERED'
and b.type_desc = 'CLUSTERED'
)
or
B.index_id is null
order by a.object_id,a.index_id
/*now here what we did is that we wanted to supply the name of the index, and if it is
a clustered index then we wanted the all the indexes that exists in a specific
schema in a specific table
since if you modify the clustered you have to modify the other indexes no matter what
so instead of doing that, rebuild from the get go
and if it is not a clustered then get me just that index and we would see where
it goes */
open FRAGMENTED_INDEX
while 1 = 1
begin
fetch next from FRAGMENTED_INDEX INTO
@object_name,
@index_name,
@current_fragmentation
if @@FETCH_STATUS <> 0
break
/*now here we are inserting the rows we got from the temp table joins into the variables
declared above so we can process them
so first we declared while 1=1 as a placeholder
so the break or the stop of this cursor will be after the break statement
so it would go fetch= get the next row from our temptables
and insert them in these 3 varibles
as long as there is a row or if fetch status = 0 which means, the thing is fetching
once there are no rows anymore
the loop would break*/
SET @SQL = concat(' alter index ',@index_name,' on ',@object_name,
case when @current_fragmentation <=30 then ' reorganize '
else ' rebuild ' end,
case when convert(varchar(100),serverproperty('Edition')) like 'Enterprise%'
or convert(varchar(100),serverproperty('Edition')) like 'Developer%'
then ' with ( online = on , sort_in_tempdb = on)' end, ';') ;
/*now here what we did, is created the sql statement we wanted to execute through
dynamic sql
so we told put alter index
then get the index name
then on
then get the object name
so until here we have alter index ix_whatever dbo.sometable
then after that we are going to decide our strategey
here we used the standard guideline 30 or less
to get reorganize
or for more rebuild
and since index rebuilds could be online only in enterprise or developer
editions, we said we wanted that in our options */
EXEC sp_executeSQL @SQL
end
close fragmented_index
deallocate fragmented_index
/* now here we executed the dynamic SQL statement we created
then we told him to cut the connection between the cursor and us
then we told him to delete the cursor from this batch*/
now if we look up the current fragmentation state using our join sys.dm_db_index_physical_stats
select
s.name as schema_name,
t.name as table_name,
t.object_id,
i.index_id,
i_p.page_count,
i_p.avg_fragmentation_in_percent,
i_p.avg_page_space_used_in_percent,
i.type_desc
from sys.dm_db_index_physical_stats(db_id(),null,null,null,'detailed') as i_p/*now obviously here
we don't need to do the detailed, but we choose to include it */
inner join sys.tables t on t.object_id = i_p.object_id
inner join sys.schemas s on s.schema_id = t.schema_id--- now no schema id in i_p so we have to use table
inner join sys.indexes i on i.object_id = i_p.object_id and i.index_id=i_p.index_id
where i_p.index_id>0
and i_p.avg_fragmentation_in_percent>0
and alloc_unit_type_desc = 'IN_ROW_DATA'
the output would be like:
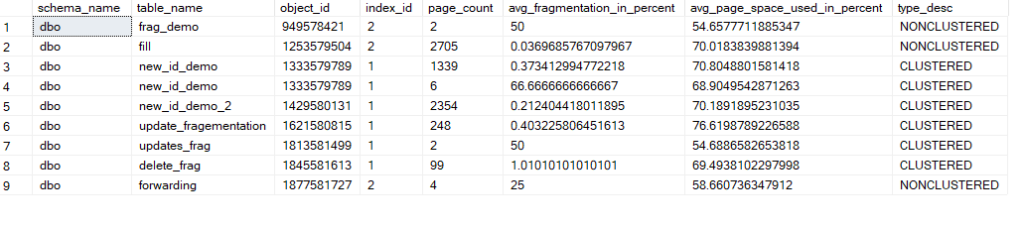
we see some demo indexes we created tin the previous blogs
now the exclusion of LOB is not necessary in 2017 enterprise and more
so we could modify that if wanted to
now here we used detailed, but we can use sampled to minimize the impact of this DMF on performance
and after we identified the fragmentation we wanted to get the names in:
DECLARE @max_fragmentation tinyint =30,
@minimun_pages smallint =1,
@SQL nvarchar(max),
@object_name nvarchar(350),
@index_name nvarchar(350),
@current_fragmentation decimal(9,6)
declare @frag_dm_db_stuff_table table
(
schema_name sysname,
table_name sysname,
object_id int,
index_name sysname,
index_id int,
page_count bigint,
avg_fragmentation_in_percent float,
avg_page_space_used_in_percent float,
type_desc varchar(255)
)
insert into @frag_dm_db_stuff_table
select
s.name as schema_name,
t.name as table_name,
t.object_id,
i.name as index_name,
i.index_id,
i_p.page_count,
i_p.avg_fragmentation_in_percent,
i_p.avg_page_space_used_in_percent,
i.type_desc
from sys.dm_db_index_physical_stats(db_id(),null,null,null,'detailed') as i_p/*now obviously here
we don't need to do the detailed, but we choose to include it */
inner join sys.tables t on t.object_id = i_p.object_id
inner join sys.schemas s on s.schema_id = t.schema_id--- now no schema id in i_p so we have to use table
inner join sys.indexes i on i.object_id = i_p.object_id and i.index_id=i_p.index_id
where i_p.index_id>0
and i_p.avg_fragmentation_in_percent>0
and alloc_unit_type_desc = 'IN_ROW_DATA'
select QUOTENAME(a.schema_name)+'.'+QUOTENAME(a.table_name),
case when a.type_desc = 'CLUSTERED' THEN 'ALL'
else QUOTENAME(a.index_name) end,
a.avg_fragmentation_in_percent
from @frag_dm_db_stuff_table as a
LEFT JOIN @frag_dm_db_stuff_table as b on a.object_id = b.object_id
and b.index_id =1
where ( a.type_desc ='CLUSTERED'
and b.type_desc = 'CLUSTERED'
)
or
B.index_id is null
order by a.object_id,a.index_id
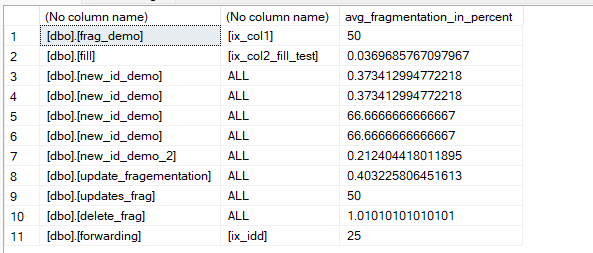
now here it shows the name and everything that needs to be supplied to the @SQL
now if wanted to look in the @SQL generated we could without the exec:
DECLARE @max_fragmentation tinyint =30,
@minimun_pages smallint =1,
@SQL nvarchar(max),
@object_name nvarchar(350),
@index_name nvarchar(350),
@current_fragmentation decimal(9,6)
declare @frag_dm_db_stuff_table table
(
schema_name sysname,
table_name sysname,
object_id int,
index_name sysname,
index_id int,
page_count bigint,
avg_fragmentation_in_percent float,
avg_page_space_used_in_percent float,
type_desc varchar(255)
)
insert into @frag_dm_db_stuff_table
select
s.name as schema_name,
t.name as table_name,
t.object_id,
i.name as index_name,
i.index_id,
i_p.page_count,
i_p.avg_fragmentation_in_percent,
i_p.avg_page_space_used_in_percent,
i.type_desc
from sys.dm_db_index_physical_stats(db_id(),null,null,null,'detailed') as i_p/*now obviously here
we don't need to do the detailed, but we choose to include it */
inner join sys.tables t on t.object_id = i_p.object_id
inner join sys.schemas s on s.schema_id = t.schema_id--- now no schema id in i_p so we have to use table
inner join sys.indexes i on i.object_id = i_p.object_id and i.index_id=i_p.index_id
where i_p.index_id>0
and i_p.avg_fragmentation_in_percent>0
and alloc_unit_type_desc = 'IN_ROW_DATA'
DECLARE FRAGMENTED_INDEX CURSOR LOCAL FAST_FORWARD FOR
select QUOTENAME(a.schema_name)+'.'+QUOTENAME(a.table_name),
case when a.type_desc = 'CLUSTERED' THEN ' ALL '
else QUOTENAME(a.index_name) end,
a.avg_fragmentation_in_percent
from @frag_dm_db_stuff_table as a
LEFT JOIN @frag_dm_db_stuff_table as b on a.object_id = b.object_id
and b.index_id =1
where ( a.type_desc ='CLUSTERED'
and b.type_desc = 'CLUSTERED'
)
or
B.index_id is null
order by a.object_id,a.index_id
open FRAGMENTED_INDEX
while 1 = 1
begin
fetch next from FRAGMENTED_INDEX INTO
@object_name,
@index_name,
@current_fragmentation
if @@FETCH_STATUS <> 0
break
SET @SQL = concat(' alter index ',@index_name,' on ',@object_name,
case when @current_fragmentation <=30 then ' reorganize '
else ' rebuild ' end,
case when convert(varchar(100),serverproperty('Edition')) like 'Enterprise%'
or convert(varchar(100),serverproperty('Edition')) like 'Developer%'
then ' with ( online = on , sort_in_tempdb = on)' end, ';') ;
print @SQL
end
close fragmented_index
deallocate fragmented_index
the output would be like:
alter index [ix_col1] on [dbo].[frag_demo] rebuild with ( online = on , sort_in_tempdb = on);
alter index [ix_col2_fill_test] on [dbo].[fill] reorganize with ( online = on , sort_in_tempdb = on);
alter index ALL on [dbo].[new_id_demo] reorganize with ( online = on , sort_in_tempdb = on);
alter index ALL on [dbo].[new_id_demo] reorganize with ( online = on , sort_in_tempdb = on);
alter index ALL on [dbo].[new_id_demo] rebuild with ( online = on , sort_in_tempdb = on);
alter index ALL on [dbo].[new_id_demo] rebuild with ( online = on , sort_in_tempdb = on);
alter index ALL on [dbo].[new_id_demo_2] reorganize with ( online = on , sort_in_tempdb = on);
alter index ALL on [dbo].[update_fragementation] reorganize with ( online = on , sort_in_tempdb = on);
alter index ALL on [dbo].[updates_frag] rebuild with ( online = on , sort_in_tempdb = on);
alter index ALL on [dbo].[delete_frag] reorganize with ( online = on , sort_in_tempdb = on);
alter index [ix_idd] on [dbo].[forwarding] reorganize with ( online = on , sort_in_tempdb = on);
now if we hit the whole thing we would get our defragmentation
but the alter index reorganize can’t be executed so in order to do that we can modify the fetch like:
SET @SQL = CONCAT(
'ALTER INDEX ', @index_name, ' ON ', @object_name, ' ',
CASE WHEN @current_fragmentation <= 30 THEN 'REORGANIZE'
ELSE 'REBUILD' END,
CASE WHEN @current_fragmentation > 30 --- this is the modification
AND (CONVERT(VARCHAR(100), SERVERPROPERTY('Edition')) LIKE 'Enterprise%'
OR CONVERT(VARCHAR(100), SERVERPROPERTY('Edition')) LIKE 'Developer%')
THEN ' WITH (ONLINE = ON, SORT_IN_TEMPDB = ON)' END, ';'
);
we would get our statements and rebuilds done
and with that we created our code.
now this is not as comprehensive as Ola Hallengren’s script, and there you have index statistics
we would cover that in the future
see you in the next blog.