
Inserts
now, it might not be the most common practice that causes fragmentation, for instance, in our previous blog, we showed an ever-increasing key example, now there since each key is inserted at the end of the page there is no way that would lead to any fragmentation.
Clustered index fragmentation using NEWID()
the most common practice is to create a surrogate key, a synthetic key that provides a way of physically sorting the data without the risk of duplicates like first + last names
now we can use an ever-increasing value like the following:
create table surrogate_key_test(
id int identity(1,1) not null primary key clustered,
col1 int)
--- now if we insert into col1 like
insert into surrogate_key_test(col1) values (20),(30),(40),(50)
Now if we select* like:
select*
from surrogate_key_test
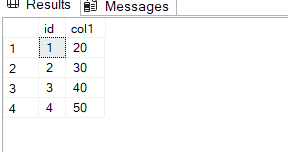
now as you can see here it adds from 1 up to N values, so there is no way a duplicate would be there
or a key might increase in bytes, since you can’t change it,
so no fragmentation
now you can delete it, but since the keys have to be in sync on page, it would be inserted at the end,
that is the most common best practice, no fragmentation
but if we use the NEWID() function
now this is what you call a uniqueidentifier value that is unique instance wise
now this would guarantee uniqueness in the server, not worldwide
at the cost of inserting a totally different value each time it does it
it could be before the last key
or after at
which leads to random inserts
with no time each page gets full and some of them never get filled
which leads to external and internal fragmentation
(for more information check the docs)
let’s try it:
use testdatabase
create table new_id_demo(
UserID uniqueidentifier not null default newid(),
purchase_amount int);
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into new_id_demo(purchase_amount)
select id*20
from ids;
create clustered index ix_userid on new_id_demo(userid)
with( fillfactor = 70, pad_index =on);
Now if we select*:
select*
from new_id_demo
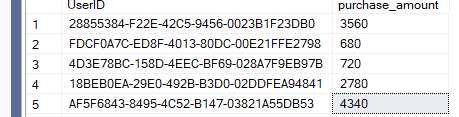
now these are the kind of values that are generated
now if we check sys.dm_db_index_physical_stats:
select page_count, avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.new_id_demo'),1,null,'detailed')
The output would be like:
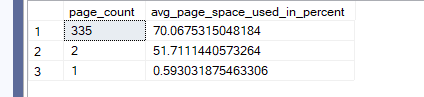
now as you can see we recently created the index so no issues there, no fragmentation
but happens if we insert the same amount of values again
when we did in the last demo, we had to do it over 12 times to get some fragmentation
Here we are going to insert the same amount of rows we inserted twice:
go
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into new_id_demo(purchase_amount)
select id*20
from ids;
go 2
And query the DMF again:
select page_count, avg_page_space_used_in_percent,fragment_count
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.new_id_demo'),1,null,'detailed')
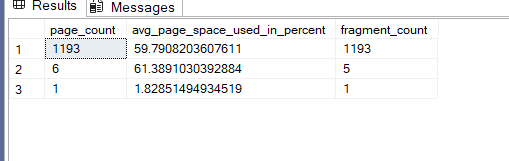
now as you can see here it started fragmenting, now our int is 4 bytes and uniqueidentifier is 16bytes
the row count is:
SELECT COUNT(*)
FROM new_id_demo;
---199168
which used 1193 pages
now each row has 24 bytes, and each page can store 335 rows, now initially with fillfactor it tolerated the inserts but at a certain point it had to split
now normally with 100 percent fillfactor we need 595 pages
but here it is almost double plus the intermediate levels, but since we had pad_index on it tolerated that a little bit
so even with fillfactor it had to fragment to have percent
plus
if we wanted to scan a range the whole thing would be filled with logical pointers, thus ramping up random i/o
now if we had the index with no fill factor like:
create table new_id_demo_2(
UserID uniqueidentifier not null default newid(),
purchase_amount int);
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into new_id_demo_2(purchase_amount)
select id*20
from ids;
create clustered index ix_userid2 on new_id_demo_2(userid)
with( fillfactor = 100);
Now if we look up the DMF:
select page_count, avg_page_space_used_in_percent,fragment_count
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.new_id_demo_2'),1,null,'detailed')

Now if we insert the same amount twice:
go
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as (select row_number() over (order by (select null)) from n5)
insert into new_id_demo_2(purchase_amount)
select id*20
from ids;
go 2
dmf again like:
select page_count, avg_page_space_used_in_percent,fragment_count
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.new_id_demo_2'),1,null,'detailed')
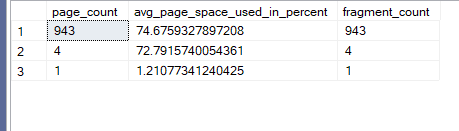
Now for the row count here :
SELECT COUNT(*)
FROM new_id_demo_2;
---196608
Now if we insert it like this:
go
with
n1(c) as (select 0 union all select 0 ),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
ids(id) as (select row_number() over (order by (select null)) from n4)
insert into new_id_demo_2(purchase_amount)
select id*20
from ids;
go 10
Then we look up the DMF again:
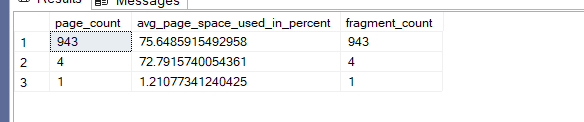
now here as you can see the pages have a lot of splits now here the whole thing could have been stored in 595
and fill factor did help at first, but once passed a certain threshold, the the whole thing blew over
and we needed almost double the pages to store the values
and the process is entirely unpredictable, we can’t know when the next random unique value will be inserted, so it is best to avoid these values, or at least indexing them
now if try inserting the whole thing again twice:
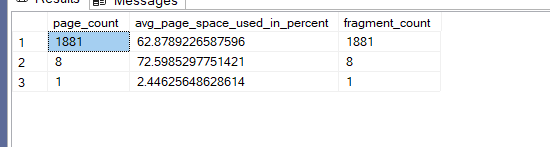
So fragmentation increases, if we do it again:
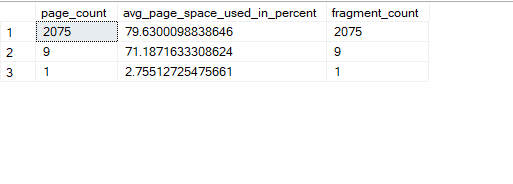
so unpredictable
same could happen if our values in the nonclustered have the same property of total unpredictability
each insert will cause fragmentation
Updates
now updates can cause index fragmentation in two ways
increasing the size of a record
now if we had a record, that has varchar in it, then for some reason we updated that value to a higher one we could induce pagesplits, since that value could no longer fit on that page
for example:
create table dbo.updates_frag
(
id int not null,
col1 varchar(7000)
)
insert into dbo.updates_frag(id,col1) values
(1,REPLICATE('a',900)),
(2,REPLICATE('B',900)),
(3,REPLICATE('C',900))
Now let’s create a clustered:
create clustered index ix_uf_id on dbo.updates_frag(id)
Now let’s see the DMF:
select index_type_desc,page_count, avg_page_space_used_in_percent,fragment_count,avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.updates_frag'),null,null,'detailed')
We get:
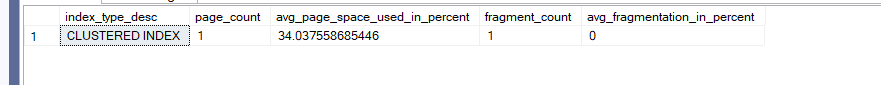
Now if we do the following:
update dbo.updates_frag
set col1 = replicate('x',7000)
where id = 2
Then DMF:
select index_type_desc,page_count, avg_page_space_used_in_percent,fragment_count,avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.updates_frag'),null,null,'detailed')
The output would be like:

Now here since we can see that an update could cause fragmentation in clustered indexes same thing, could happen if this column was a nonclustered key, not just a regular row
DELETE
now anything we delete before reclaiming the space has fragmentation:
use testdatabase
create table delete_frag(
id int identity(1,1),
col1 int);
with
n1(c) as (select 0 union all select 0),
n2(c) as (select 0 from n1 as t1 cross join n1 as t2),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as (select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as(select row_number() over(order by(select null)) from n5)
insert into delete_frag(col1)
select id*4 from ids ;
create clustered index ix_delete on delete_frag(id)
Now after that if we DMF:
select index_type_desc,page_count, avg_page_space_used_in_percent,fragment_count,avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.delete_frag'),null,null,'detailed')

Now if we delete half the rows like:
delete from dbo.delete_frag where id%2 = 0
Now we DMF again:
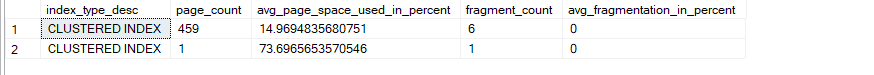
Internal fragmentation doubled
Now if we hit index rebuild like:
alter index ix_delete
on dbo.delete_frag
rebuild
Then DMF again like:
select index_type_desc,page_count, avg_page_space_used_in_percent,fragment_count,avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.delete_frag'),null,null,'detailed')
We would get the older results like:
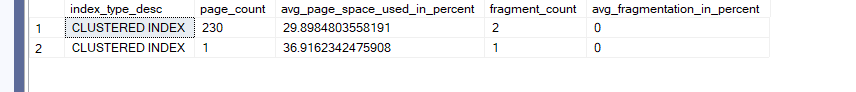
Now, we can configure it like this:
alter index ix_delete
on dbo.delete_frag
rebuild with(fillfactor =100 ,pad_index= on)
Now if we DMF again:
select index_type_desc,page_count, avg_page_space_used_in_percent,fragment_count,avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.delete_frag'),null,null,'detailed')
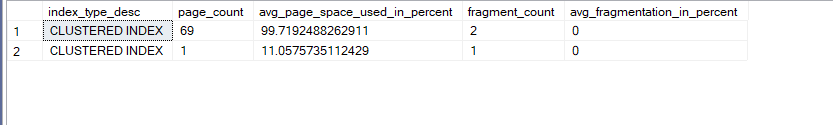
Variant of fragmentation: Heap bloat, or unused deletes, or ghosted that is yet to be cleaned
now here we have a heap, this heap has rows, now these rows get inserted first, after that somebody deletes them, they are waiting to be used, now sometimes they do get reused, and sometimes they don’t, sometimes this space can not be ever reclaimed unless we create a clustered rebuild then drop.
The state where the heap deleted rows still occupy space = the size is still the same but the data is less = bloat state, since the heap is bloated with empty records
to demonstrate the effects:
use testdatabase
create table heap_bloat(
id int not null,
col1 int,
col2 int);
with
n1(c) as (select 0 union all select 0),
n2(C) as ( select 0 from n1 as t1 cross join n1 as t2 ),
n3(c) as (select 0 from n2 as t1 cross join n2 as t2),
n4(c) as ( select 0 from n3 as t1 cross join n3 as t2),
n5(c) as (select 0 from n4 as t1 cross join n4 as t2),
ids(id) as( select row_number() over (order by (select null)) from n5)
insert into heap_bloat(id,col1,col2)
select id,id*2,id*4
from ids
Now if we DMF like:
select OBJECT_NAME(object_id),page_count,index_type_desc,index_level,avg_fragmentation_in_percent,avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID(N'dbo.heap_bloat'),null,null,'detailed')
We get:

Now if we count with statistics:
set statistics io on;
go
select count(*)
from dbo.heap_bloat
go
set statistics io off;
We get the following:
--- row count 65536
---Table 'heap_bloat'. Scan count 1, logical reads 171, physical reads 0
Now if we delete:
delete from dbo.heap_bloat
where id%2 = 0
Now if we check the DMF:
select OBJECT_NAME(object_id),page_count,index_type_desc,index_level,avg_fragmentation_in_percent,avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID(N'dbo.heap_bloat'),null,null,'detailed')

now as you can see the pages are the same but the avg_page_space_used_in_percent = 54 percent so it is half empty now
now if we count with stats:
set statistics io on;
go
select count(*)
from dbo.heap_bloat
go
set statistics io off;
We get:
--32768
--Table 'heap_bloat'. Scan count 1, logical reads 171, physical reads 0, page server reads 0, read-ahead reads 0
Now as you can see even though we have the rows we still need to read 171 pages, even though they are empty, why? heap_bloat
now if we rebuild the table like this:
alter table dbo.heap_bloat rebuild
Now if we check the DMF:
select OBJECT_NAME(object_id),page_count,index_type_desc,index_level,avg_fragmentation_in_percent,avg_page_space_used_in_percent
from sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID(N'dbo.heap_bloat'),null,null,'detailed')

now we have half the page count, and most of the space is full, no fragmentation
and if we read with counts like:
set statistics io on;
go
select count(*)
from dbo.heap_bloat
go
set statistics io off;
We get:
--32768
--Table 'heap_bloat'. Scan count 1, logical reads 86, physical reads 0, page server reads 0, read-ahead reads 0,
Now as you can see we have almost half the reads now.
Variant of fragmentation: forwarded records
now in Heaps, we talked about forwarding records, and we said, when SQL server can not fit an updated record into a page, instead of taking the whole thing to a new page, and assigning a new RID, it moves to another one, leaves what you call a forwarding stub, that tells where is the new record and how to get it, then it forwards, moves the record to another page that can fit it on it, so it becomes a forwarded record.
Now this serves the purpose of not updating nonclustered indexes on heaps, since there is no need to update it, if RID is still the same, however this introduces overhead of random I/O, since SQL server has to look for another random page anytime it encounters such an issue.
Let’s see that in action:
use testdatabase
create table forwarding (
id int identity(1,1),
col1 varchar(6000)
)
create nonclustered index ix_idd on dbo.forwarding(id);
go
insert into dbo.forwarding(col1)
values (replicate('x',500))
go 1000
Now we want to create a baseline for index scans, singleton-lookup, and range seeks using set statistics i/o:
go
set statistics io on;
go
select*
from forwarding;
select*
from forwarding
where id = 200;
select*
from forwarding
where id between 200 and 210;
go
set statistics io off
We get the following:
(1000 rows affected)
Table 'forwarding'. Scan count 1, logical reads 85, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(1 row affected)
(1 row affected)
Table 'forwarding'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(1 row affected)
(11 rows affected)
Table 'forwarding'. Scan count 1, logical reads 13, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Now let’s update:
update dbo.forwarding
set col1 = replicate('x',3000)
where id % 3 = 1
Now if we do the same again:
go
set statistics io on;
go
select*
from forwarding;
select*
from forwarding
where id = 200;
select*
from forwarding
where id between 200 and 210;
go
set statistics io off
We get:
(1000 rows affected)
Table 'forwarding'. Scan count 1, logical reads 460, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(1 row affected)
(1 row affected)
Table 'forwarding'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(1 row affected)
(11 rows affected)
Table 'forwarding'. Scan count 1, logical reads 15, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(1 row affected)
so singleton lookups did not have much change, maybe because the range we looked into did not have any ids that are divided by 3 so no need to forward anything
but the scan definitely increased from 85 to 460 which is like 5 times
and the range scan with nested increased from 13 to 15
so it affects performance a lot
and with this, we are done with this one, see you in the next one.
[…] there is a third option, we touched on in fragmentation(here […]
[…] since this data is for defragmentation purposes like we talked about here , generally the last piece of advice is always […]