
Hi everyone,
(docs)
today we are going to introduce the following:
- Ordered scan
- Merry-go-round or advanced scan
- Allocation order scan
- Index seek
- range scan
- Singleton lookup or point-lookup
- SARGable Predicates
Ordered scan
let’s assume we ran the following query:
select*
from heapvsclustered
order by id asc
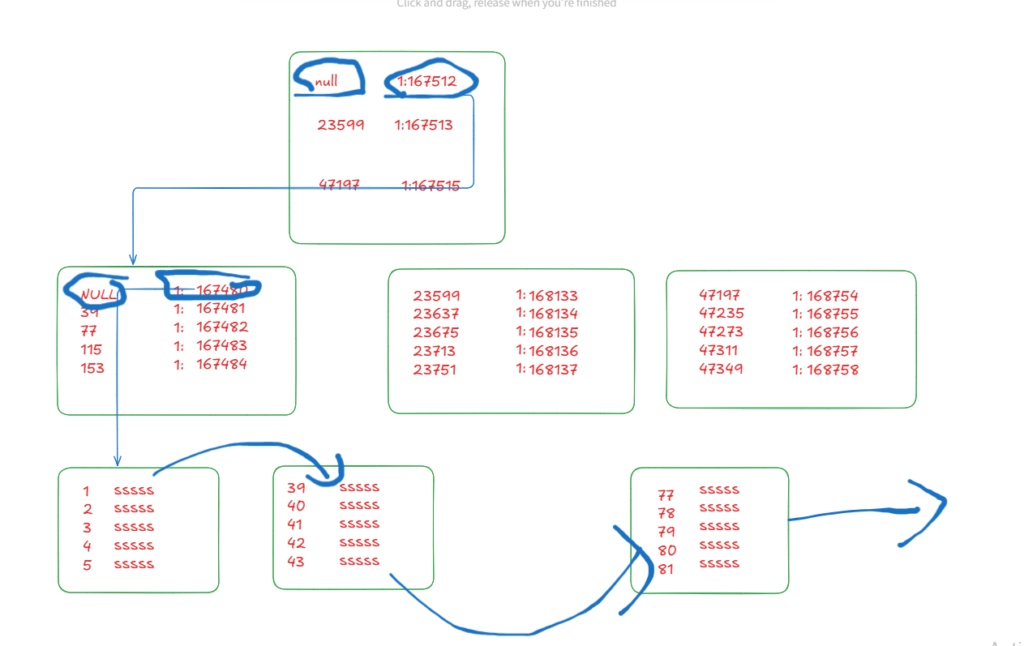
Now here what SQL server does to get the data:
- first, it goes to the root page
- then it identifies the null range page or the lowest id intermediate page
- then it goes to that and identifies the lowest key or the first null page
- then if scans that page and from the doubles links
- it goes to the next page etc. until it finishes the table data
- then it is done
and in the physical operator in the execution plan, we can see the following
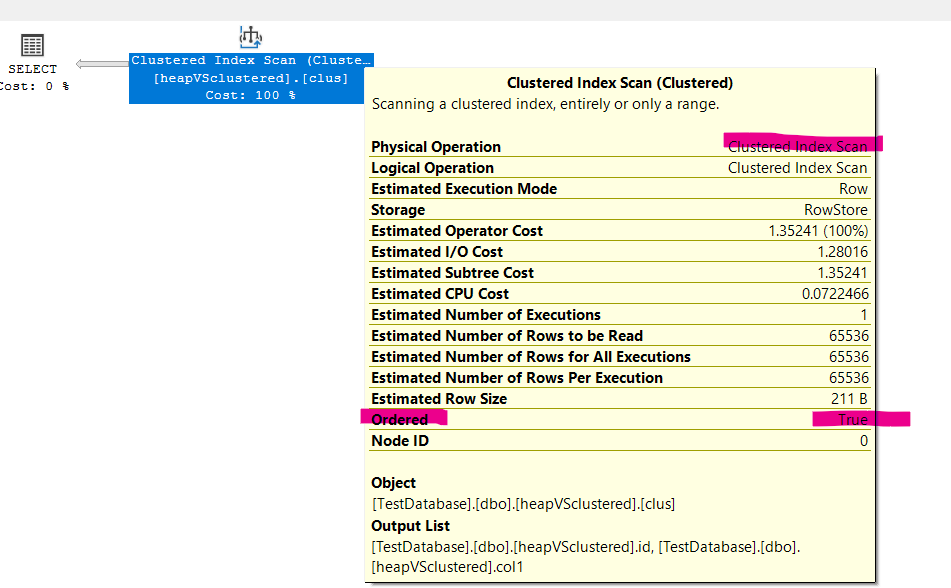
this is what you call an ordered scan
now it does not have to have the order by clause
it just means that it did scan the needed data through the index’s key order
now this order could be forward or backward since the default in SQL server is to create ascending keys
and our key was created with no specific order in mind
and we requested ascending order we scanned the index forward like we showed in the picture, it starts with the first page and picks it up from there
or it could go backward
now if we check the properties of our plan we can see the following:

Now if we order by desc like:
select*
from heapvsclustered
order by id desc

now this one can not run in parallel
Merry-go-round or advanced scan
now here, two queries that share the same scan ranges,
for example in Stackoverflow(brent ozar)
if we write the following queries:
use StackOverflow
select EmailHash
from Users
where id >1 and id< 1000000000
select EmailHash
from Users
where id >5000
and id<1500000000
we would get the following plans
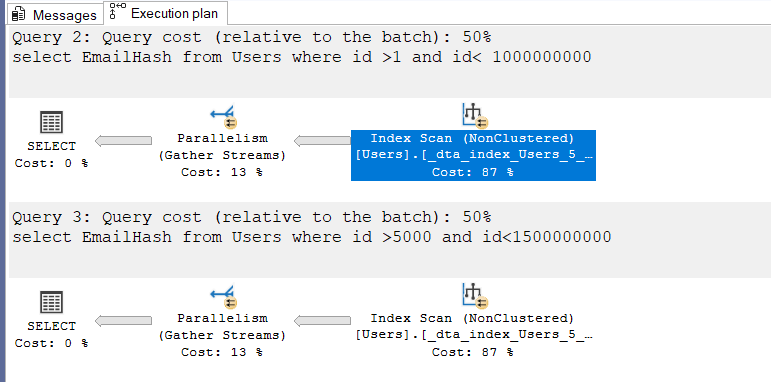
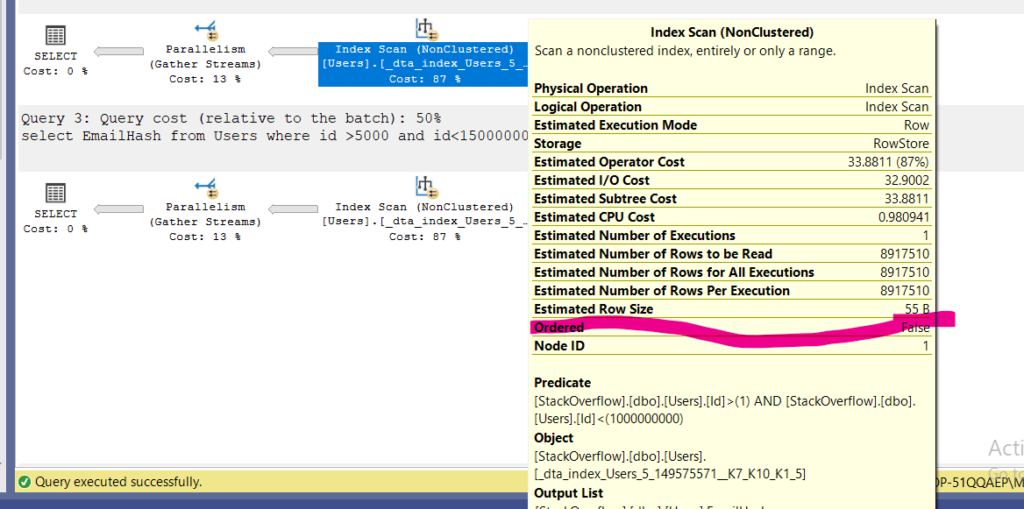
now these two could share the scan, by looking into the ordered property:
now these have to be in two different sessions since these would not execute simultaneously
these queries would use the same index scan twice, which would cut I/O costs
now what would happen if we assume the first query started first, then while executing, the second one started scanning the same pages, SQL server would go, and take the first result set and merge it with the remaining range, and find the rest of the range
in our case, it was the range between 5000 and 1000000000
now while doing that it does not respect the index order
and why is that? because it uses an allocation order scan
and there it might respect the page order, but it would not go through the index
more on it below
now since there is no order
we would see that in our execution plan
so we see that in the properties of our plan
now this does not mean we did use it, it just means that we did not stick to the key order
now here they observed the effects using wait_stats and i/o cost for each query
now since the order is not respected, if wanted and order we should use the ORDER BY clause
now, the only way to tell directly we used such a thing is to attach a debugger and take a look at the code, we will cover that in another blog
Allocation order scan
now instead of using the index key, it uses the IAM pages, just like the heaps and it scans the whole table, and the ordered property would be false as well,
same goes here, we don’t know if the order was not respected we scanned twice, but different pages
or we just went to the allocation unit map
and took whatever we wanted
secondly, here we are not scanning heaps
we are scanning clustered index pages
so no forwarding pointers
here we have index pages
so here we might have to scan pages twice or skipped
since it is not going to use the index pages
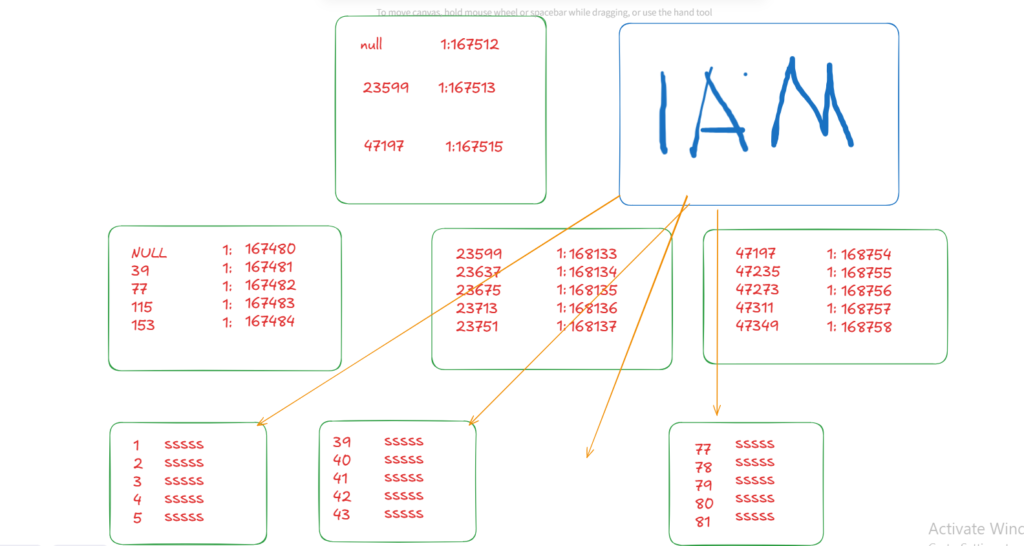
it might scan for a value that has an old range
but then got moved because of index fragmentation
but the allocation map does not have knowledge of that
which causes it to skip some rows
or scan the same rows twice
since the row has been moved after the select statement was issued
that is why this is not used much unless we specify READ UNCOMMITTED or SERIALIZABLE
the previous example fits this category
Index seek
now here we have a very specific value or values that could be reached on a small number of pages and we don’t need to scan the whole index, that which reduces the cost
for example:
select id
from dbo.heapvsclustered
where id between 1 and 5
and 1 = (select 1)
The plan would be like:
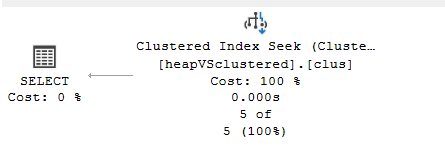
Now here it did this:
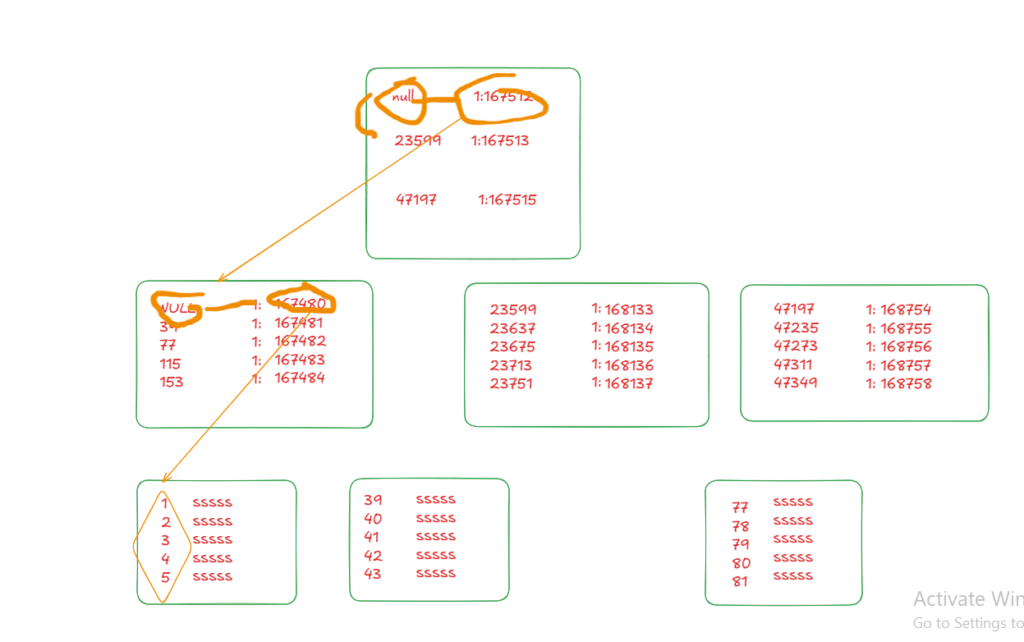
it looked for the minimum and max value requested in the root page
it identified which intermediate page it needed
then it went there, it looked for the leaf pages that contain our ids
then located the data page we needed, went there, and got the rows for us
so instead of scanning the whole thing it just requested some of them and got them for us
now there are two types of seeks point-lookup or singleton-lookup and range scan
range scan
we see this(Paul White) where we have a range of rows, not a specific one that we defined(like the query in the previous example)
there it defines the range it wants, from root to intermediate to page
then it gets it at one move, like we presented in the previous query,
Now if we check the plan tool tip like:

As you can see SQL server defined the range, then it starts at the start, now here we know from the properties:
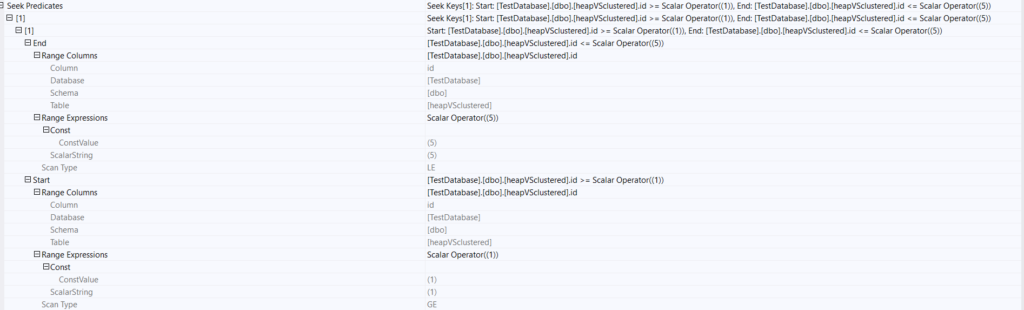
The start is at the 1, and in the same plan we know it is forward, so we know it starts:
- root looks for the range
- intermediate looks for the page
- leaf looks for one
- and keeps on scanning until it reaches 5
- here in logical operator generation(check out our blog on the query optimizer part 1) it created
begin tran
select id
from dbo.heapvsclustered
where id between 1 and 5
and 1 = (select 1)
OPTION (RECOMPILE, QUERYTRACEON 8605, QUERYTRACEON 8606, QUERYTRACEON 8607,querytraceon 3604)
COMMIT TRAN;
*** Converted Tree: ***
LogOp_Project QCOL: [TestDatabase].[dbo].[heapVSclustered].id
LogOp_Select
LogOp_Get TBL: dbo.heapvsclustered dbo.heapvsclustered TableID=2069582411 TableReferenceID=0 IsRow: COL: IsBaseRow1000
ScaOp_Logical x_lopAnd
ScaOp_Comp x_cmpGe
ScaOp_Identifier QCOL: [TestDatabase].[dbo].[heapVSclustered].id
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1)
ScaOp_Comp x_cmpLe
ScaOp_Identifier QCOL: [TestDatabase].[dbo].[heapVSclustered].id
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=5)
ScaOp_Comp x_cmpEq
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1)
ScaOp_Subquery COL: Expr1003
LogOp_Project
LogOp_ConstTableGet (1) [empty]
AncOp_PrjList
AncOp_PrjEl COL: Expr1003
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1)
AncOp_PrjList
It starts with what it is going to project or:
- LogOp_Project QCOL: [TestDatabase].[dbo].[heapVSclustered].id = meaning this is the column that I want to get the rows from, now this one has two child operators
- AncOp_PrjList = which is here for patching sake only
- LogOp_Select: which is a logical operator that filters our request like the where clause in our query, here it defines which rows should we get and it has 2 child operators
- LogOp_Get TBL: that says we should get rows and opens the execution
- ScaOp_Logical x_lopAnd: scalar operator(does scalar operations = deals with single-valued math) that defines the and( the where clause) in our operations since we had an and int it, and this one has 3 child operators
- ScaOp_Comp x_cmpGe ScaOp_Identifier QCOL: [TestDatabase].[dbo].[heapVSclustered].id ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1): here it says it is a comparison operator that deals with greater than or equalt to(GE) and it defines the value int 1 so it is ≥ 1
- ScaOp_Comp x_cmpLe: less than or equal to 5
- ScaOp_Comp x_cmpEq: equality operator from equal hence ‘=’ we had in our where clause now this one has two child operators:
- ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1): Ti here means type of integer, meaning an integer that has the value of 1, hence our one that had a scalar constant which was 1
- ScaOp_Subquery COL: Expr1003: as it sounds it is a subquery logical operator that has a worktable(temporary table created and destroyed by SQL serve during execution) with one column called Expr1003 now this subquery has one child operator:
- LogOp_Project: defines what we are going to project= show in this query it has 2 child operators:
- LogOp_ConstTableGet (1) [empty]: this one gets from table empty a constant called 1 hence our 1 in the subquery
- AncOp_PrjList : shows us calculated columns or constant expressions in a query it has one child operator:
- AncOp_PrjEl COL: Expr1003 el at the end means element so here it is going to project an expression or computed column element that would be defined in the child operator
- ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1): we just explained it
- AncOp_PrjEl COL: Expr1003 el at the end means element so here it is going to project an expression or computed column element that would be defined in the child operator
- LogOp_Project: defines what we are going to project= show in this query it has 2 child operators:
Singleton lookup or point-lookup
now here we have a specific row or rows in mind
we generally use in or = in the syntax
so SQL server does a single lookup for each
for example:
select id
from dbo.heapvsclustered
where id in(1,2)
and 1 = (select 1)
OPTION(RECOMPILE,QUERYTRACEON 8606,QUERYTRACEON 8607,
QUERYTRACEON 8608,QUERYTRACEON 3604,
QUERYTRACEON 8619,QUERYTRACEON 8620,
QUERYTRACEON 8621,QUERYTRACEON 8615,
QUERYTRACEON 8675)
The execution plan had a seek? what kind
if we look up the properties:
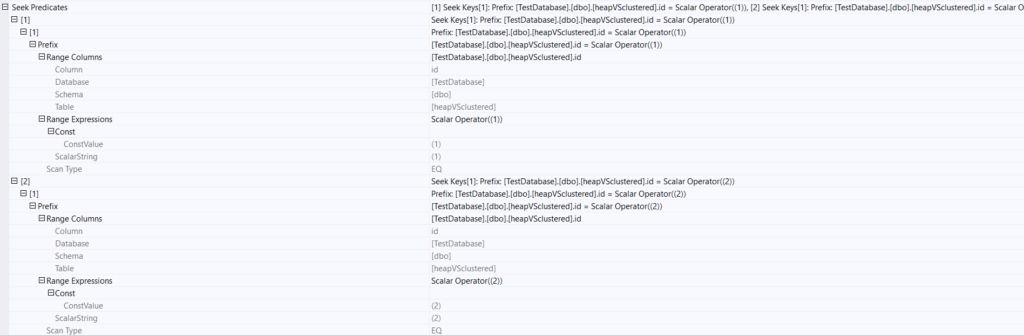
so there is no start or end
just two distinct seek operations
Now in the simplified tree:
*** Simplified Tree: ***
LogOp_Select
LogOp_Get TBL: dbo.heapvsclustered dbo.heapvsclustered TableID=2069582411 TableReferenceID=0 IsRow: COL: IsBaseRow1000
ScaOp_Logical x_lopOr
ScaOp_Comp x_cmpEq
ScaOp_Identifier QCOL: [TestDatabase].[dbo].[heapVSclustered].id
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1)
ScaOp_Comp x_cmpEq
ScaOp_Identifier QCOL: [TestDatabase].[dbo].[heapVSclustered].id
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=2)
- so we have the regular logop_select that filters the rows for us it has two child operators
- ScaOp_Logical x_lopOr: so instead of an and we have an ‘OR’ since it could be anything from the IN() we had it had two child operators
- ScaOp_Comp x_cmpEq: equality it has two child operators
- ScaOp_Identifier QCOL: now this one shows us where to identify, look for the row
- ScaOp_Const TI: it says it should be 1
- the same goes for the other operator
- ScaOp_Comp x_cmpEq: equality it has two child operators
- ScaOp_Logical x_lopOr: so instead of an and we have an ‘OR’ since it could be anything from the IN() we had it had two child operators
and from there it looks for alternatives, generates a physical operator, and then we have two seeks with two seek predicates
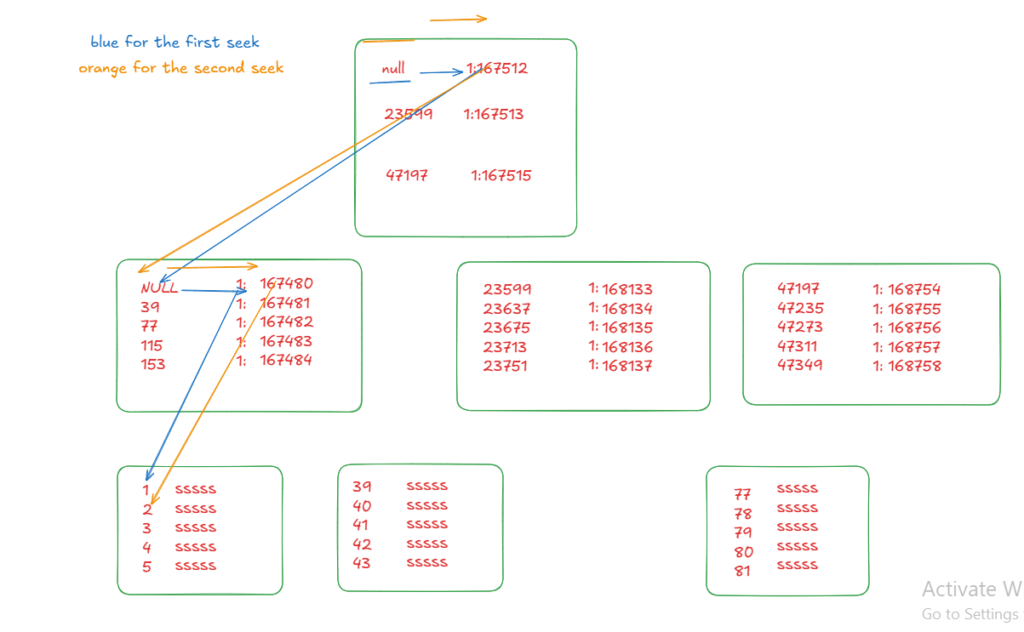
now if we add more values in the in we can see:
select id
from dbo.heapvsclustered
where id in(1,2,3,4,5,7)
and 1 = (select 1)

So 6 in here now if we ask for 50 values
go
SET STATISTICS TIME ON
go
select id
from dbo.heapvsclustered
where id in(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50)
and 1 = (select 1)
option (recompile)
go
select id
from dbo.heapvsclustered
where id between 1 and 50
go
SET STATISTICS TIME off
we get 50 seeks and if we compare with range scan seeks while we measure execution time
the output would be:
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 40 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 33 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
so the range scan was shorter, so if we need 1 value point-lookup might be more effective but once the number increases the range scan might surpass it
both are seeks
but one of them seeks a range, and the other one seeks one row at a time
now if we = like:
select id
from dbo.heapvsclustered
where id = 1

which is what we want
on the other hand, if we scan like this:
go
SET STATISTICS TIME on
go
select id
from dbo.heapvsclustered
where id>1
and 1=(select 1)
go
select id
from dbo.heapvsclustered
where 1=(select 1)
go
SET STATISTICS TIME off
The output was like:
SQL Server Execution Times:
CPU time = 63 ms, elapsed time = 216 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server Execution Times:
CPU time = 32 ms, elapsed time = 369 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Now here it still takes less but if we use a larger table like salesorderheaderenlarged from Adam Machanic:
use adventureworks2022
go
SET STATISTICS TIME on
go
select SalesOrderID
from Sales.SalesOrderHeaderEnlarged
where SalesOrderID>1
and 1=(select 1)
go
select SalesOrderID
from Sales.SalesOrderHeaderEnlarged
where 1=(select 1)
go
SET STATISTICS TIME off
The output was like:
(1 row affected)
SQL Server Execution Times:
CPU time = 500 ms, elapsed time = 4177 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
(1290065 rows affected)
(1 row affected)
SQL Server Execution Times:
CPU time = 610 ms, elapsed time = 4047 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
so it starts taking less
now if we do that for StackOverflow
use StackOverflow
go
set statistics time on
go
select id
from Users
where id > 1
and 1 = (select 1)
go
select id
from Users
where 1 = (select 1)
go
set statistics time off
go
the output
(8917505 rows affected)
SQL Server Execution Times:
CPU time = 3515 ms, elapsed time = 37786 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
(8917507 rows affected)
SQL Server Execution Times:
CPU time = 4094 ms, elapsed time = 36262 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
so it starts taking less and less time
SARGable Predicates
now for a query to get an index seek, it has to be SARGable or search argument-able value
so if we want to use the index seek, we need to meet this criterion, meaning, SQL server has to be able to isolate a single value from the index and show it on its own
what arguments could be qualified as SARGable?
- <
- =
- like in the case of prefix matching example: where id like ‘1%’
- in
- between
non-SARGable queries would be:
- like in case of non-prefix matching, for example: when id like’%1%’
- not
- <>
SQL server has to do extra work to process each row before matching it leading to an index scan
we will end this blog with an example of this and dive deeper into another blog:
select id
from dbo.heapVSclustered
where id in (1)
----
select id
from dbo.heapVSclustered
where id like'%1%'
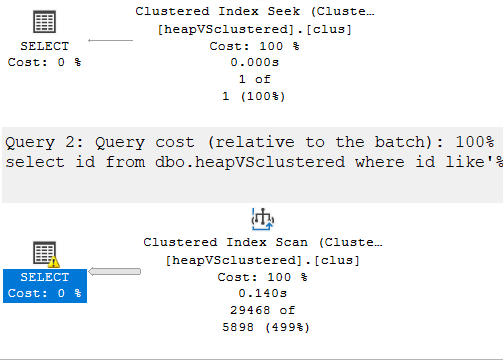
now here as you can see it seeked in the first, scanned in the second
now logically, they are different operations with different results
and the second one has a warning that says there is a convert-implicit
we will dive into both in upcoming blogs, goodbye
[…] comparing performance hits between an index scan and the range scan in index seeks go to our blog( ways to read indexes […]