
In the previous blog, we talked about ROLLUP, which gave us the totals and subtotals based one and two columns, but while giving the subtotals of a certain column, it did not give us the other one
First, let’s create a table and compare on it:
create table SalesOrderW(SalesGuy int ,SalesDate int ,Sales money)
insert SalesOrderW values(500,2023,20000000),(500,2024,200000),(500,2025,200000),
(200,2023,1000000),(200,2024,100),(200,2025,1000000),
(300,2023,3000),(300,2024,20000),(300,2025,4000000000000)
For example:
select SalesGuy,SalesDate,sum(sales)as total_sales
from dbo.SalesOrderW
group by rollup(SalesGuy,SalesDate);
the output pivoted would be like( more on how to pivot this later):
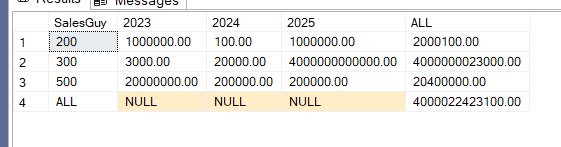
We can see there are no totals per year, only per SalesGuy totals. Now, if we do the following:
select SalesGuy,SalesDate,sum(sales)as total_sales
from dbo.SalesOrderW
group by cube(SalesGuy,SalesDate);
We get:
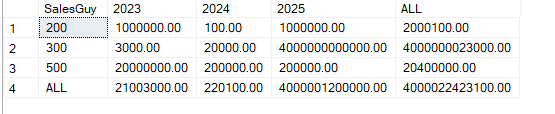
So we get new totals, and we replace the nulls with all when grouping by a certain group.
The actual output was like:
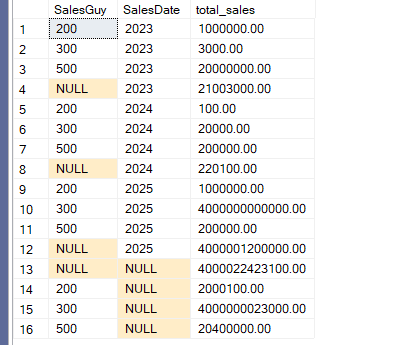
So it groups by both, and calculates totals, then it outputs the total for each SalesGuy, then the total per year, and it does the same 3 times, then after that it outputs the totals per SalesGuy without the SalesDate, and we see a total and 13th row here where it calculates the total.
The execution plan here is slightly different:
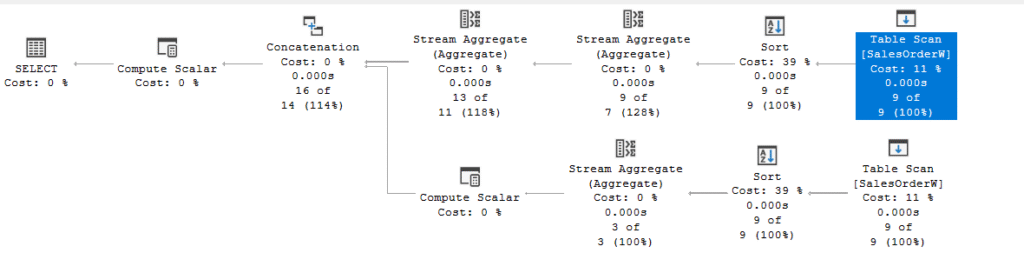
Now let’s dissect the upper section, the sort:

Since the stream aggregate needs sorting, there is nothing new here, it just sorts them based on date, and then SalesGuy. In the stream Aggregate:
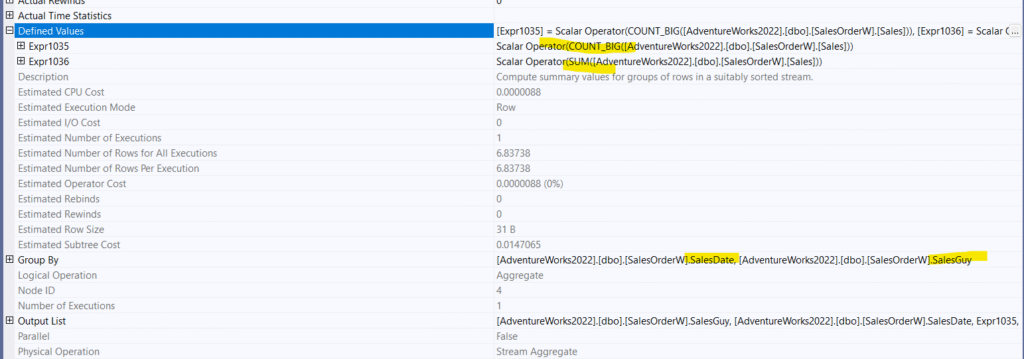
The count here is to output null when the count is = 0, and the sum, is the sum we asked for
It is grouped by SalesDate and SalesGuy, so nothing new, it is like grouping by with out anything, this is our regular old fashion stream aggregate,
We can confirm that by doing this:
select SalesGuy,SalesDate,sum(sales)as total_sales
from dbo.SalesOrderW
group by cube(SalesGuy,SalesDate)
option(hash group);
We get:
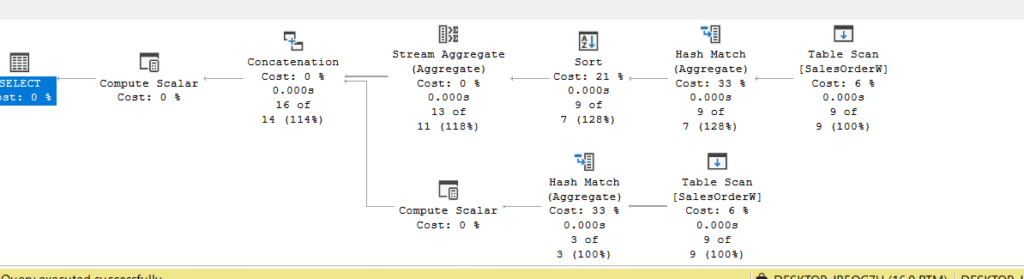
Now, back to our original plan, in the second stream aggregate in the upper section:
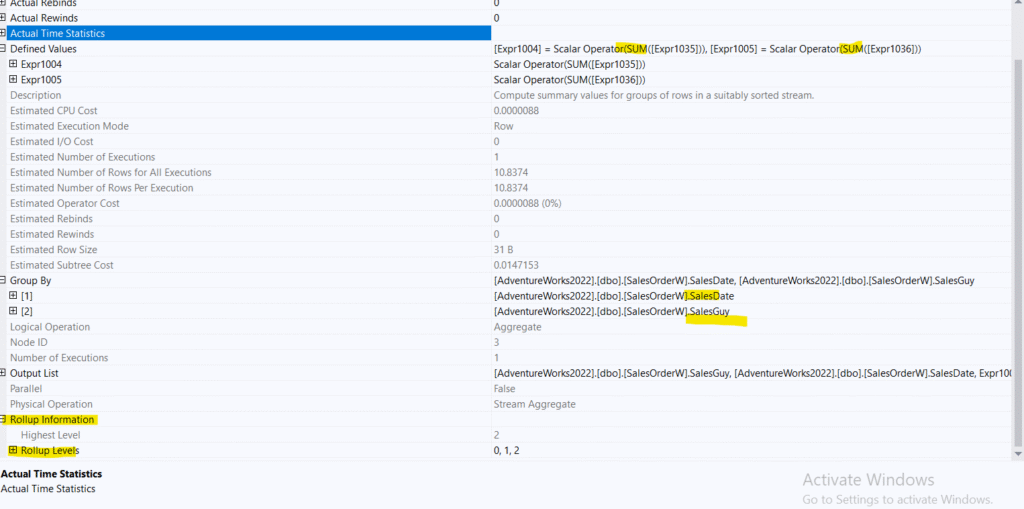
This is the rollup part of our plan, here we see what we saw in the previous blog, so far so good, nothing new, here it starts summing by each, so we can see it computes the totals for SalesDate here, not the SalesGuy, this is why we have our second part of the plan, the lower section, to compute the SalesGuy totals.
In the lower section, in the sort:

So, it tries to sort for the stream aggregate, nothing new, except the fact that this is the part of the plan where we start dealing with SalesGuy totals, in the stream aggregate:
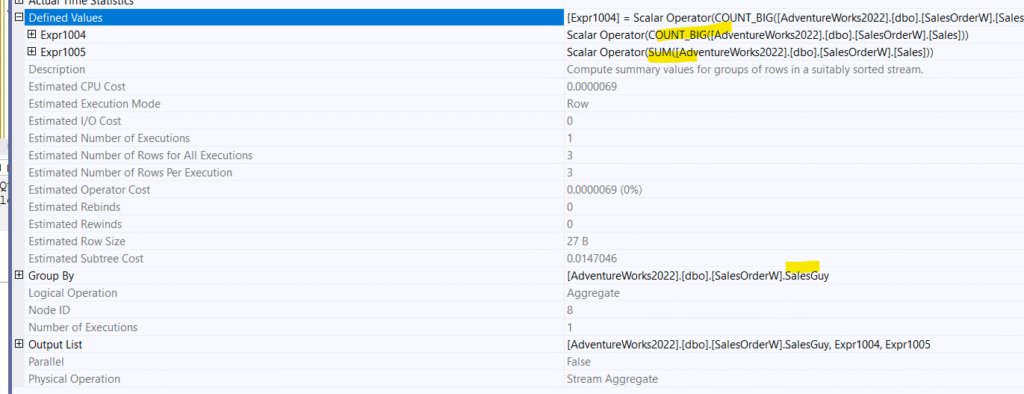
So, here it sums, and the count is for the null thing, Also, we see that the expressions for it and the rollup stream aggregate are the same, so maybe they are treated as the same internal table???
In the compute scalar:
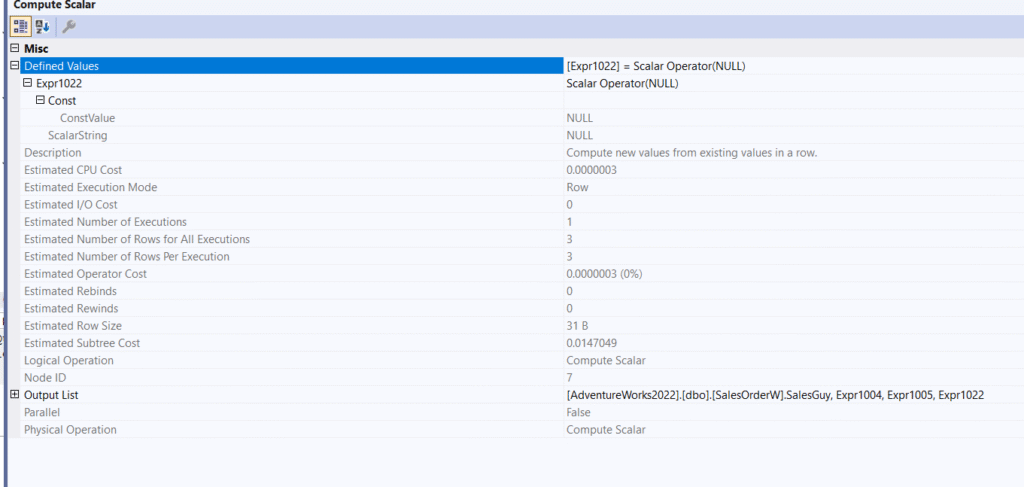
Here, it just declared a constant called null, and added it, like we did when we tried to present the rollup, but here it added for another layer.
In the Concat:

Here, it just puts the columns next to each other, the last compute scalar is to output null when the sum is = 0.
So basically, this is how SQL Server rewrote the query for us:
select SalesGuy,SalesDate,sum(sales)as total_sales
from dbo.SalesOrderW
group by rollup(SalesGuy,SalesDate)
union all
select null, SalesGuy, sum(Sales)
from dbo.SalesOrderW
group by SalesGuy
;
Now, if we look at the execution plan:
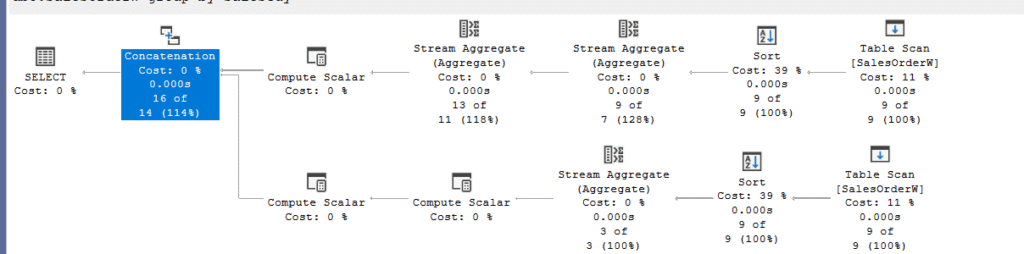
There is not much difference, except the fact that it had to declare different expressions for similar stream aggregates, and it had to declare a different expression for their concatenation.
Now here we have a lot of nulls, how could we get rid of them, and pivot:
select
SalesGuy,[2023],[2024],[2025],[all]
from(
select
case when grouping(SalesGuy) = 0
then convert(char(20),SalesGuy)
else 'all'
end SalesGuy,
case when grouping(SalesDate) = 0
then convert(char(20),SalesDate)
else 'all'
end SalesDate,
sum(Sales) as sales
from SalesOrderW
group by cube(SalesGuy,SalesDate)
) as somet
pivot
(
sum(sales)
for SalesDate in ([2023],[2024],[2025],[all])
) as piv;
We get the results we want, and we can replace the cube with rollup, so we can get the rollup results
The subquery after the FROM clause is similar to what we showed in the previous blog.
And it already shows what we want, but since we want to flip unique row values in the SalesDate column to column for each so we could make it more readable we selected and pivoted by it using the function, nothing much, we can.
for the rules and traces:
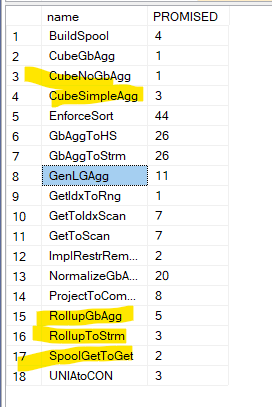
You can see that even the cube syntax converts the cube to rollup, since both have to calculate the same values at some point, the cube just adds another query to calculate subtotals and totals for the leftmost column independently by adding another section of the plan
And with that, we finish this blog.